



全参数微调(full fine-tuning)
即调整所有参数,性能效果很好,但是显存占用极高,并且需要大量微调数据以避免过拟合.适用于计算资源充足,且任务对性能要求很高的情形.
LoRA(low-rank adaptation)和QLoRA(quantized low-rank adaptation)通过最小化微调参数的数量来缓解大模型训练的成本.
LoRA(low-rank adaptation)
低秩分解,冻结原模型参数,在旁路添加两个可训练的低秩矩阵,通过矩阵分解模拟参数更新,训练时仅优化低秩矩阵,推理时将结果和原模型输出叠加.性能接近全参数微调,稳定性高,扩展性强,适用于资源有限的情形,性价比高,并且训练后的模块化插件可以随时加载或卸载,不影响原模型,特别适合多任务场景,在实际工作中,参数量可以减少到0.01%-3%.
为什么可以低秩分解?
矩阵中有很多冗余维度,只需抓住主要方向.另外,微调是为了强化模型某个领域的能力,不要对所有方向的参数进行调整.
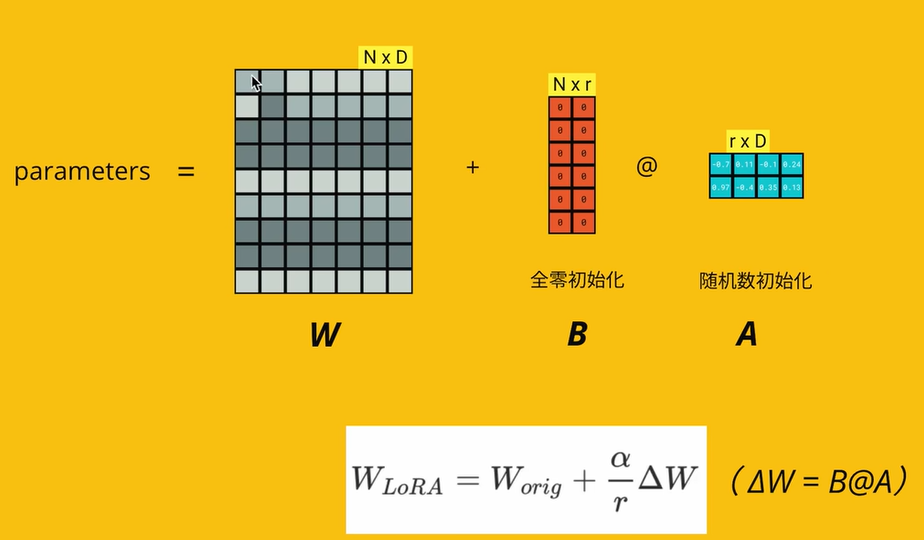
B全零初始化A随机初始化的原因?
1. 在刚开始训练时保持与预训练模型一样的能力(因为有全零初始化层)
2. 如果AB都全零初始化,容易训练时梯度消失
3. 如果AB都随机初始化,容易训练时噪声过多,模型难以收敛
from peft import get_peft_model,LoraConfig
peft_config=LoraConfig(
r=8,#秩,即上图中的r
lora_alpha=32,#LoRA 缩放因子 (scaling factor)
#一个常见的经验法则是将 lora_alpha 设置为 r 的 2 倍(例如 r=8, lora_alpha=16),这有时能带来更好的性能
lora_dropout=0.1,#在 LoRA 适配器的 A 矩阵输出上应用 dropout 的概率
target_modules=['query','key','value']#最关键的参数之一,指定要在模型的哪些层上应用 LoRA
#可以打印模型结构 (print(model)) 来查看具体的模块名称
'''
其他参数:
modules_to_save (List[str], optional)
指定除了 LoRA 适配器外,哪些原始模块的参数也需要被设置为可训练并保存
fan_in_fan_out (bool, optional)
适用于某些特定架构(如 Switch Transformers),是否将 LoRA 权重的 fan_in 和 fan_out 维度互换。对于标准的 Transformer 模型(如 LLaMA, GPT),通常不需要设置为 True。
init_lora_weights (bool, optional)
是否使用 LoRA 论文中的方法初始化 A 和 B 矩阵。
rank_pattern (Dict, optional) 和 lora_alpha_pattern (Dict, optional)
允许为 target_modules 中的不同模块指定不同的 r 或 lora_alpha 值。
task_type (TaskType)
指定任务类型, 这会影响 PEFT 库如何处理模型的头部 (head)。对于大多数生成任务,使用 CAUSAL_LM。
layers_to_transform (Union[List[int], int], optional):
指定只在模型的特定层(索引)上应用 LoRA。例如 layers_to_transform=[0, 1, 2] 只在前 3 层添加适配器。
'''
)
model=get_peft_model(model,peft_config)其中最后一个线性层照常训练的代码
for param in model.get_submodule("model").get_submodule("classifier").parameters():
param.requires_grad = TrueQLoRA(quantized low-rank adaptation)
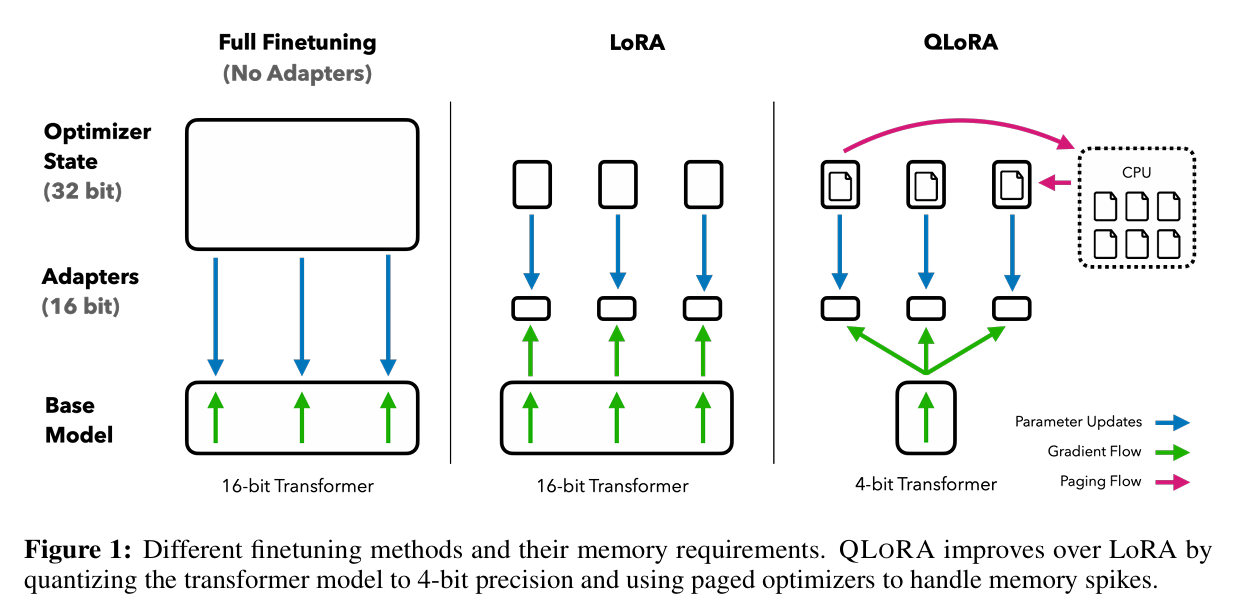
在LoRA基础上引入量化技术,将原模型权重以4bit精度存储,推理时反量化至16bit或BF16,在极低显存下仍然接近Lora性能,适用于超大规模模型或边缘设备部署,另外还使用了分页优化器的功能来处理内存峰值。
量化:将输入从多信息表达离散化为少信息表达的过程,经常意味着将多比特数据转化为少比特数据。
比如说,将32比特的FP32量化为INT8的数据:
![]()
其中c就是量化因子
再进行反量化:
![]()
这个方法的弊端是,如果存在一个值非常大的异常点,那么c就会异常,数据就不会体现真实的水平。
为了防止这个问题出现,一个通用的方法是将输入张量切分成blocks,然后每个block独立量化,每个block都有自己单独的量化因子c。
下图是QLoRA和微调,LoRA的区别
提出节省内存的新方法:
(1)NF4
(2)双重量化
(3)分页优化器

工作流程:
- 基础模型的权重矩阵被量化到4-bit精度,即基础模型存储在显存中的权重是 4-bit (比如NF4) 的。
- 和LoRA相同,QLoRA在权重矩阵上添加低秩更新AB, 当需要进行计算(前向/反向传播)时,仅训练A和B的参数,冻结基础模型的权重矩阵. 这些4-bit 权重会被临时反量化(dequantize)到
compute_dtype(如 bfloat16)。 - 使用反量化后的 bfloat16 权重和 bfloat16 的激活值进行实际的矩阵乘法等运算。
- 推理时,可以选择将QLoRA计算的增量永久的加到基础模型的权重上,也可以选择同时计算经过原始模型权重临时反量化之后的输出和经过QLoRA的输出,并将两者相加.第二种方法的灵活性更高.
- 运算完成后,结果被处理,而原始的 4-bit 权重仍然安全地存储在显存中。
1. 提前配置好参数,这样模型导入的时候会转换成4bit的量化模型
compute_dtype = getattr(torch, "float16")
quant_config = BitsAndBytesConfig(
load_in_4bit=True,#启用 4 位量化加载。这是开启整个 4-bit 量化流程的总开关。
bnb_4bit_quant_type="nf4",
#可选值: fp4, nf4
#"fp4": 4 位浮点数 (Floating Point 4)
#"nf4": 正态分布浮点数 4 位 (NormalFloat 4)。这是 QLoRA 论文推荐并默认使用的类型。
bnb_4bit_compute_dtype=compute_dtype,
#作用: 指定在进行计算时(如矩阵乘法),反量化后的权重和激活值使用的计算精度。
bnb_4bit_use_double_quant=True,
#启用双重量化 (Double Quantization)
)什么是'nf4'?
- 基于分位数量化(quantile quantization)设计,分位数量化指的是确保每个分位数区间中有相同数量的输入张量的值。分位数量化通过经验CDF评估输入张量的分位数。但是分位数量化存在问题---量化评估的过程非常费力,因此会使用一些快速的分位数估计方法,但是这些方法会导致对于异常值的估计错误。
- 如果你能合理假设输入张量来自某个固定形状的分布(如高斯),那么量化就从一个数据驱动的估计问题,变成了一个参数缩放问题——既快又准。
- NormalFloat 4 (NF4)
- 神经网络的权重通常近似服从正态分布(大部分值集中在 0 附近,少数值远离 0)。
"nf4"是一种非均匀量化方案。它在 [-1, 1] 区间内,在接近 0 的区域分配了更多的量化级别,而在绝对值较大的区域分配较少的级别。
1、生成 k 位分位数量化类型:对标准正态分布(N(0,1))计算2ᵏ+1个分位数,这些分位数将分布划分为2ᵏ个等概率区间(每个区间概率相等),从而得到k位的量化数据类型(共 2ᵏ个量化值)。
k 位量化需要 2ᵏ个等概率区间,本质是二进制位数的表达能力与量化精度的匹配,k 位二进制的表达能力:最多对应 2ᵏ个离散值。要得到2ᵏ
个等概率区间,需要2ᵏ+1个分位数(分位数是区间的 “边界”)。
2、归一化量化类型到 [-1,1]:把第一步得到的分位数数值,缩放到[-1,1]区间内(让量化类型的范围符合目标)。
3、量化输入权重张量:通过 “绝对最大值缩放”,把输入权重张量也归一化到[-1,1](让权重范围与量化类型范围匹配),然后按常规方式量化。注:这一步等价于调整权重的标准差,使其与 k 位量化类型的标准差一致。
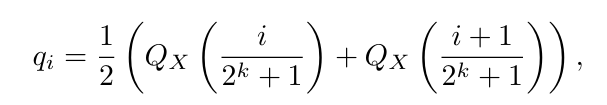
- (Q_X(p)):标准正态分布的分位数函数(即累积分布函数的反函数,输入概率 p,输出对应分位数);
 :是
:是2ᵏ+1个分位数对应的概率点(把 [0,1] 分成 2ᵏ+1 份);- 取相邻两个分位数的平均值作为该区间的量化值(让每个量化值代表一个等概率区间的 “中点”)。
在对称量化(Symmetric Quantization)中一个非常关键的技术缺陷:在对称的 k-bit 量化方案中,数字“0”无法被精确地表示出来,总会存在微小的误差。
📏 1. 什么是 k-bit 量化?
在计算机中,我们通常用 32 位浮点数(FP32)来表示神经网络的权重。为了节省显存,我们会将其压缩成低精度的整数,比如 8 位整数(INT8)或 4 位整数(INT4),这就是量化。
k-bit:指用 k 个比特来表示数据。例如 k=8 时,能表示的整数范围通常是 [−128,127] 。
映射关系:量化的过程就是把一个浮点数范围(比如 [−a,a] )线性地映射到整数范围(比如 [−128,127] )。
🔍 2. 对称量化(Symmetric Quantization)的问题
对称量化假设数据的分布是以 0 为中心的,即正负范围相等(例如 [−a,a] 映射到 [−128,127] )。
为什么“0”无法被精确表示?
在整数体系中,0 就是 0。
但在浮点数映射到整数的过程中,量化公式通常是这样的:
对于对称量化,由于正负区间的划分以及缩放因子(Scale)的计算方式,原始浮点数中的 0.0 往往很难完美地对应到整数中的 0。即使对应上了,由于后续计算中的舍入误差,原本应该是 0 的位置在反量化后可能会变成一个极小的非零数(例如 0.0001)。
📉 3. 这个问题会导致什么后果?
在深度学习推理中,0 是一个非常特殊的值,因为它代表“没有贡献”或“填充(Padding)”。
计算误差:如果量化后的“0”变成了一个微小的非零数,那么在矩阵乘法中,它仍然会进行计算,而不是像真正的 0 那样直接跳过。这会引入不必要的计算噪声。
无法利用稀疏性:很多模型利用“0”来进行稀疏计算(Sparse Computation),即遇到 0 直接跳过以加速运算。如果 0 变成了非零数,这种加速优化就失效了。
填充(Padding)问题:在处理不同长度的输入(如 NLP 中的句子)时,短的序列会被填充(Padding)为 0 来对齐长度。如果这些填充的 0 无法被精确表示,它们会变成无意义的噪声参与计算,影响模型输出的准确性。
🛠️ 4. 解决方案:非对称量化(Asymmetric Quantization)
为了解决这个问题,很多现代量化方案(如文中提到的 NormalFloat 或者常见的 Affine 量化)会引入一个 zero_point(零点) 参数。
非对称量化允许映射范围是不对称的(例如 [−a,b] 映射到 [−128,127] )。
强制对齐:通过调整 zero_point,我们可以强制让量化后的整数 0 精确地对应原始浮点数中0.0。
总结:
这句话揭示了对称量化的一个数学缺陷——它无法完美地保留“零值”。这对于需要精确处理稀疏数据或填充数据的模型(如 Transformer)来说是不可接受的,因此 QLoRA 等技术倾向于使用能精确表示零的非对称数据类型(如 NF4)。
如何解决对称量化的数学缺陷呢?
为了解决问题,NF4 没有采用“正负对称”的方式,而是采用了非对称(Asymmetric)的分配策略。假设我们有 k 个比特(例如 k=4),总共有 2^k = 16 个编码槽位。
第一步:分配槽位
负数部分:分配 2^{k-1} 个槽位。
当 k=4 时,负数分得 2^3 = 8 个槽位。
正数部分:分配 2^{k-1} + 1 个槽位。
当 k=4 时,正数分得 2^3 + 1 = 9 个槽位。第二步:计算分位数 (q_i)
负数范围:在负数区间(例如 -1 到 0)内,计算出 8 个最优的量化点(分位数)。
正数范围:在正数区间(例如 0 到 1)内,计算出 9 个最优的量化点(分位数)。🧩 3. 最后的拼接(去重)
当你分别算出负数的 8 个点和正数的 9 个点后,你会发现一个问题:这两个集合都包含了数字 0。
负数集合的最后一个点是 0。
正数集合的第一个点也是 0。如果直接把它们拼起来,你会得到 8 + 9 = 17 个点,但这不仅超过了 4-bit 的容量(16 个),还重复表示了 0。
解决方案:
将这两个集合合并,并移除其中一个重复的 0。🏁 4. 最终结果
通过这种“8+9-1”的操作,最终得到了一个包含 16 个数值的完美码本(Codebook):
7 个负数(不包含 0)
1 个精确的 0
8 个正数(不包含 0)📌 总结
这段话描述的是一种非对称量化策略。它通过给正数多分一个槽位(2^{k-1}+1),确保了 0 能作为一个离散的点被包含在内。这种设计专门针对神经网络权重的正态分布特性,在 0 附近提供了更密集的刻度,从而在极低比特(4-bit)下依然保持了极高的数学精度。
这种设计能更精确地表示权重分布,在 4-bit 的极低精度下最大限度地保留原始模型的信息,从而在微调后能获得更好的性能。相比之下,均匀量化的 fp4 效果通常稍差。
什么是双重量化?
- 量化过程需要存储一些元数据,主要是每个量化组的缩放因子 (scale)。
- 这些
scale值通常是 16 位或 32 位的浮点数。 bnb_4bit_use_double_quant=True表示bitsandbytes会对这些scale值本身再进行一次量化,通常是量化到 8 位整数 (int8)。
2. 加载模型,传入定义的参数
original_model = AutoModelForCausalLM.from_pretrained(
model_path,
torch_dtype=compute_dtype,
device_map={"": 0},
quantization_config=quant_config
)3.刚刚load的是预训练模型,现在在这个基础上微调,构造用于微调的模型
from peft import LoraConfig, get_peft_model, prepare_model_for_kbit_training
config = LoraConfig(
r=32, #Rank
lora_alpha=16,
target_modules=["q_proj", "k_proj", "v_proj", "o_proj"],
bias="none",
lora_dropout=0.01, # Conventional
task_type="CAUSAL_LM",
)
# 1 - Enabling gradient checkpointing to reduce memory usage during fine-tuning
original_model.gradient_checkpointing_enable()
# 2 - Using the prepare_model_for_kbit_training method from PEFT
original_model = prepare_model_for_kbit_training(original_model)
peft_model = get_peft_model(original_model, config)如何处理内存峰值?
梯度检查点(Gradient Checkpointing)的代价:
为了节省显存,我们通常会使用“梯度检查点”技术。它通过牺牲计算时间(重新计算中间结果)来减少存储中间激活值(Activations)的内存。
内存“潮汐”现象:
虽然检查点技术降低了平均显存占用,但它会导致内存峰值。因为在反向传播(Backward Pass)计算梯度的瞬间,系统需要同时加载权重、梯度和临时的激活值,这会导致显存需求瞬间激增(就像潮水的波峰)。
后果:
如果这个峰值超过了GPU的物理显存容量,程序就会报错 CUDA Out of Memory (OOM),导致训练中断。
分页优化器(Paged Optimizers) 的核心思想借鉴了操作系统的虚拟内存管理:
化整为零:它不再将整个模型的优化器状态(动量矩阵)作为一个连续的大块内存驻留在GPU显存中。
分页管理:将动量矩阵切分成一个个固定大小的“页”(Page)。
按需加载:就像你刚才看到的代码逻辑,只有当某个参数需要更新时,才去获取对应的页。如果页不在GPU上,就从内存(或更慢的存储)中“换入”;如果GPU显存紧张,就把不常用的页“换出”到内存。
解决方案:NVIDIA 统一内存(Unified Memory)
这就是这句话中最关键的“连接点”。如果没有统一内存,管理“换入换出”会非常复杂,需要手动调用 memcpy。
NVIDIA 统一内存(UM) 提供了一个由 CPU 内存和 GPU 显存组成的单一内存地址空间。
打破界限:开发者只需分配一块“托管内存”(Managed Memory),这块内存对程序来说是统一的,CPU 和 GPU 都可以直接访问同一个指针。
自动迁移:系统(硬件+驱动)会自动跟踪数据的访问模式。当 GPU 核函数需要访问某个分页优化器的页时,如果该页当前在 CPU 内存中,系统会自动将其迁移(Migration)到 GPU 显存;反之亦然。
消除峰值:
通过分页优化器,我们将原本巨大的、连续的优化器状态拆分成了小块。
通过统一内存,这些小块可以按需在 CPU 内存和 GPU 显存之间自动流动。
结果:GPU 显存中只保留当前计算所需的“热数据”页,其余的可以暂存在容量巨大的 CPU 内存中。这就像给显存装了一个“缓冲气囊”,平滑了反向传播时的瞬时显存需求高峰,避免了 OOM 错误。
这个过程对用户是透明的,你只需要将普通的 Adam 或 AdamW 替换为 PagedAdam 或 PagedAdamW 即可。
使用方法:
peft_training_args=TrainingArguments(
...
optim='paged_adamw_8bit',
#使用分页优化器(Paged Optimizers)是 QLoRA(以及标准 LoRA)在极端内存受限环境下进行微调时,应对内存峰值(memory spikes)的一种重要技术
...
)
peft_trainer=transformers.Trainer(
model=peft_model,
train_dataset=train_dataset,
eval_dataset=eval_dataset,
args=peft_training_args,
data_collator=transformers.DataCollatorForLanguageModeling(tokenizer,mlm=False),
)如何避免过拟合?
QLORA:Efficient Finetuning of Quantized LLMs


















 2283
2283

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









