



配合代码一起看当然更好,想看代码的朋友可以去搜一搜,这里只介绍了主要内容
BGE Landmark Embedding
一共包括三个关键点,分别是下面的三个标题
-
不需要将文本切分的结构
使用一组特殊的标记(token),并将标记命名为landmarks,将这些标记放在每个句子的最后。这个标记用来捕捉这个句子的潜在语义。同时,使用一个基于大模型的编码器来嵌入标记后的长文本,这个编码器也嵌入了查询。由于感知了丰富的上下文信息,这个标记后的嵌入可以是一个对于每个句子高度辨别的表示。
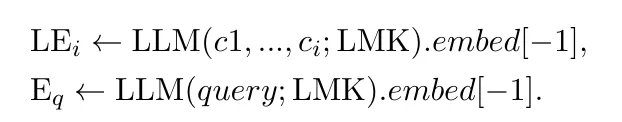
另外,这个新的结构会使用一个滑动窗口,这样标记嵌入可以通过流处理从任意长的文本上生成。
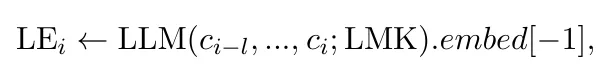
-
position-aware的目标函数,优先考虑连续数据的最终边界
给每个句子分配不同的权重,这个权重随着句子在文章中的位置呈现指数级的增长。因此,最后一个句子(最终边界)会被强调并更好的区分(这样做是为了提取完整的句子群)。通过选择最终边界前的k个句子,查询所对应的有效信息可以被综合考虑。
![]()
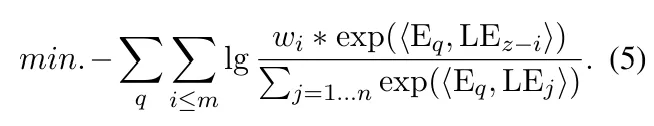
-
多阶段的学习算法,最大程度的使用已有数据和生成数据,做到训练成本最优化
将标记嵌入分解成两个部分:基础语义辨别和高水平的上下文表示能力(包括三个部分:1)对于成对数据的远程监督 2)对于根据规则生成的噪声长数据的弱监督 3)对于大模型生成的高质量长文本数据的微调。
1)对于成对数据的远程监督
模型初始化:基于这些成对数据,模型可以被初始化为一个基本的句子嵌入器(sentence embedder)。这意味着模型能够将句子转换为向量表示,以便后续的相似度计算或检索任务。
地标嵌入:在这一过程中,地标嵌入(landmark embedding)采取了一种特殊的形式。具体来说,只有一个单一的地标被附加到答案上下文的末尾。
训练形式:第一阶段的训练遵循密集检索(dense retrieval)的基本训练形式。
负样本选择:对于每个查询,会提供15个难负样本(hard negatives)以及批次内的负样本(in-batch negatives)。硬负样本是指与查询相关性较低但容易混淆的样本,有助于提高模型的区分能力。
2)对于根据规则生成的噪声长数据的弱监督
将不同查询对应的答案随机打乱,然后将他们合并成一个伪长文档
2.1)模拟真实场景中“长文档包含多个无关/相关句子”的情况。
2.2)迫使模型不能靠位置或固定模式识别答案,而必须真正理解语义。
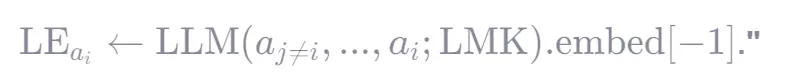
要为第 i 个答案 a_i 生成嵌入 LE_{a_i} ,就把整个伪长文档(包含 a_i 和其他打乱的答案 a_{j≠i} )作为输入送入 LLM。然后取 a_i 所在位置(或整个序列末尾,取决于实现)的 hidden state,即 .embed[-1] ,作为该句子的嵌入。
训练方式:使用 批内负采样(in-batch negatives)
3)对于大模型生成的高质量长文本数据的微调
这一步,使用了真实的长文本,对于每个长文本,一系列的文本跨度被随机采样,然后通过大模型生成伪查询。由于这可能会和真实世界的分布不同,所以只有一小部分的合成数据在最后一个阶段生成。
chunking-free in-context retrieval
RAG系统的组成:检索器和生成器。给定要给输入查询,检索器先鉴定相关证据内容,生成器再基于内容生成答案
在RAG系统里面使用长文本的问题:1)生成模型的输入长度小于证据内容的长度 2)不相关的内容可能导致模型偏离查询,生成不正确的回复
Chunking-Free In Context (CFIC) retrieval approach
如何规避chunking:1)使用编码的隐藏状态来对内容进行检索,2)使用自回归解码来鉴别查询所需要的特定证据文本,解码时用到了两个策略,分别是Constrained Sentence Prefix Decoding和Skip Decoding
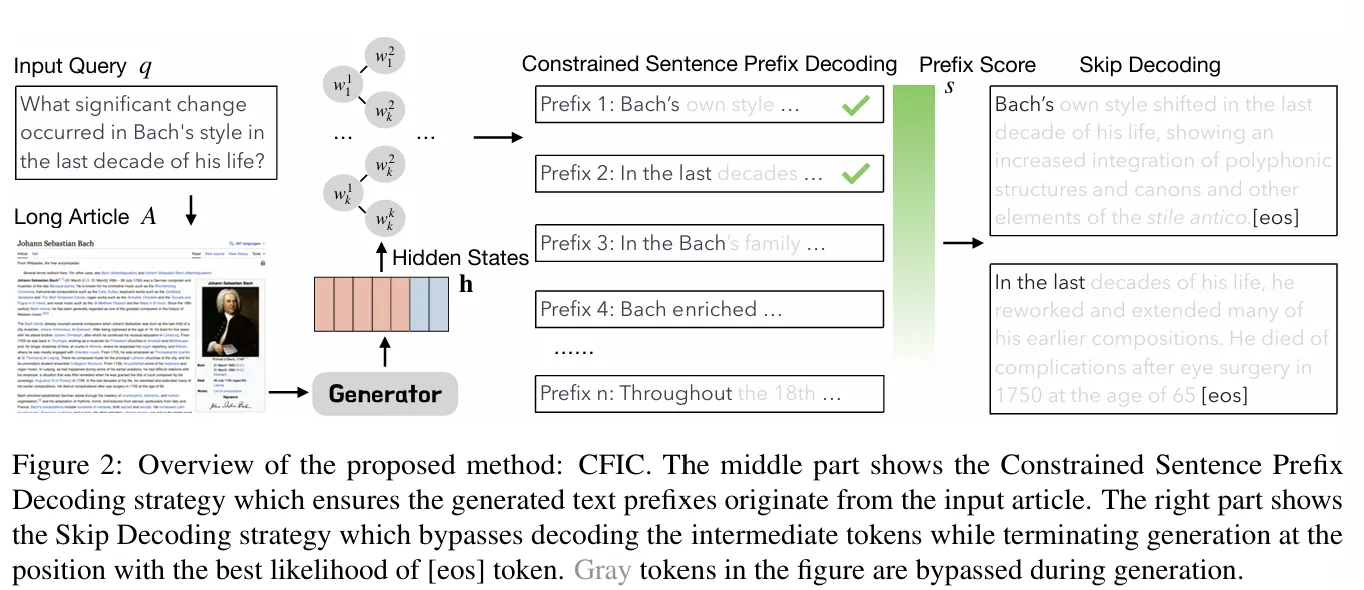
- 输入一个查询,使用搜索引擎检索一篇长文章作为基础证据。
- 将查询和长文章作为输入提示词编码成隐藏状态。
- 基于隐藏状态,使用Constrained Sentence Prefix Decoding策略识别top-k个句子前缀。
- 使用Skip Decoding策略省略了对于中间标记的解码,并在最可能生成结束标记的地方停止生成过程。
Constrained Sentence Prefix Decoding策略:减少幻觉问题
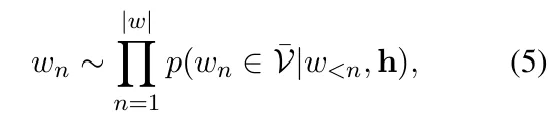
根据第n个词以前的词的隐藏状态,从句子前缀集合中选取第n个词
为了找到最相关的证据,而不仅仅是一个,系统会使用 top-k 采样 策略。
它会从 V̅ 中采样出概率最高的 k 个起始词(或短前缀)。
关键点:如果多个句子以相同的词开头(例如,文档里有多个句子都以 “In” 开头),那么仅凭一个词是无法唯一确定是哪一个句子的。
因此,解码过程会继续进行,但依然保持约束:下一个词的选择范围被限制在那些以已生成前缀开头的句子集合中。
这个过程会持续进行(论文中用 β 表示所需的解码步数),直到生成的前缀足以在文档中唯一地标识出一个或多个具体的句子位置为止。
对于每个通过上述过程生成的、能唯一标识位置的句子前缀 b ,系统会计算其序列得分(sequence score)。这个得分通常是该前缀所有token的对数概率之和,并进行了长度归一化(如公式6所示),以避免过长的前缀天然得分更高。
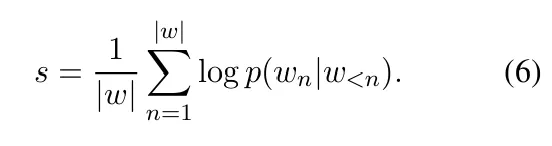
最后,系统会选择得分最高的 k 个句子前缀(如果有重复的内容会进行合并),并将它们对应的完整句子在原文中的起始位置作为潜在的证据文本起点。
Skip Decoding策略
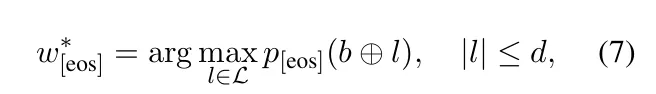
l代表前缀b之后的标记序列,最大长度为d
训练阶段:
将“从长文本中找出支持性段落以支撑下游任务”这一过程,正式命名为 Evidence Generation(证据生成)。要实现证据生成,必须增强语言模型的能力,使其能够在海量文本中精准定位到具体的、相关的句子或段落。
为什么用 SFT? 因为它可以直接让模型学习“给定查询和文档,输出正确证据”的映射关系,更贴近实际应用需求。
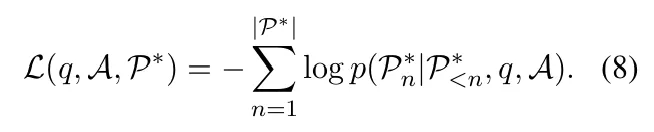
q是查询,A是长文档,P是长文档中对应的段落内容
BGELandmarkEmbedding: A Chunking-Free Embedding Method For Retrieval Augmented Long-Context Large Language Models
Grounding Language Model with Chunking-Free In-Context Retrieval

















 311
311

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









