 LSTM详解
LSTM详解





 本文深入浅出地介绍了长短时记忆网络(LSTM),一种特殊的循环神经网络(RNN),旨在解决长期依赖性问题。文章详细解释了LSTM的结构、原理及其如何通过门控机制有效处理序列数据。
本文深入浅出地介绍了长短时记忆网络(LSTM),一种特殊的循环神经网络(RNN),旨在解决长期依赖性问题。文章详细解释了LSTM的结构、原理及其如何通过门控机制有效处理序列数据。
 本文收录于《深入浅出讲解自然语言处理》专栏,此专栏聚焦于自然语言处理领域的各大经典算法,将持续更新,欢迎大家订阅!
本文收录于《深入浅出讲解自然语言处理》专栏,此专栏聚焦于自然语言处理领域的各大经典算法,将持续更新,欢迎大家订阅! 个人主页:有梦想的程序星空
个人主页:有梦想的程序星空 个人介绍:小编是人工智能领域硕士,全栈工程师,深耕Flask后端开发、数据挖掘、NLP、Android开发、自动化等领域,有较丰富的软件系统、人工智能算法服务的研究和开发经验。
个人介绍:小编是人工智能领域硕士,全栈工程师,深耕Flask后端开发、数据挖掘、NLP、Android开发、自动化等领域,有较丰富的软件系统、人工智能算法服务的研究和开发经验。 如果文章对你有帮助,欢迎
如果文章对你有帮助,欢迎
关注、
点赞、收藏、订阅。
1、LSTM的背景介绍
长短时记忆神经网络(Long Short-term Memory Networks,简称LSTM)是特殊的RNN,尤其适合顺序序列数据的处理,LSTM 由 Hochreiter & Schmidhuber (1997) 提出,并在近期被 Alex Graves 进行了改良和推广,LSTM明确旨在避免长期依赖性问题,成功地解决了原始循环神经网络的缺陷,成为当前最流行的RNN,在语音识别、图片描述、自然语言处理等许多领域中成功应用。
2、RNN的不足
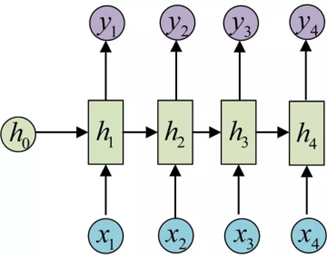
图1 RNN的网络结构图
循环神经网络处理时间序列数据具有先天优势,通过反向传播和梯度下降算法达到了纠正错误的能力,但是在进行反向传播时也面临梯度消失或者梯度爆炸问题,这种问题表现在时间轴上。如果输入序列的长度很长,人们很难进行有效的参数更新。通常来说梯度爆炸更容易处理一些。梯度爆炸时我们可以设置一个梯度阈值,当梯度超过这个阈值的时候可以直接截取。
有三种方法应对梯度消失问题:
(1)合理的初始化权重值。初始化权重,使每个神经元尽可能不要取极大或极小值,以躲开梯度消失的区域。
(2)使用 ReLu 代替 sigmoid 和 tanh 作为激活函数。
(3)使用其他结构的RNNs,比如长短时记忆网络(LSTM)和 门控循环单元 (GRU),这是最流行的做法。
3、LSTM的结构和原理
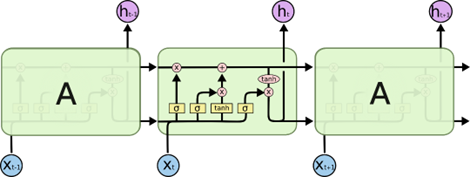
图2 LSTM的结构图
上图中使用的各个元素的图标的含义如下图所示:

其中:
Neural Network Layer:神经网络层,用于学习;
Pointwise Operation:逐点运算操作,如逐点相乘、逐点相加、向量和等;
Vector Transfer:向量转移,向量沿箭头方向移动;
Concatenate:连接,将两个向量连接在一起;
Copy:复制,将向量复制为两份。
LSTM核心是细胞状态,穿过图的顶部的长横线,长直线称之为细胞状态(Cell State),决定什么样的信息会被保留,什么样的信息会被遗忘,记为。
细胞状态像传送带一样,它贯穿整个细胞却只有很少的分支,这样能保证信息不变的流过整个RNN,细胞状态如下图所示:
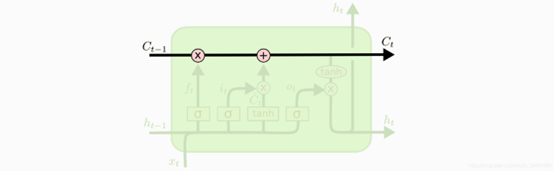
图3 细胞状态图
LSTM网络能通过一种被称为门的结构对细胞状态进行删除或者添加信息。门能够有选择性的决定让哪些信息通过。门的结构为一个sigmoid层和一个点乘操作的组合,sigmoid层输出0到1之间的数,描述每个部分有多少量可以通过,0代表不允许任何量通过,1表示允许任何量通过,结构如下图所示:
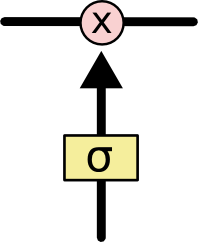
图4 门结构单元
LSTM实现了三个门计算,即遗忘门、输入门和输出门,用来保护和控制细胞状态。
遗忘门负责决定保留多少上一时刻的单元状态到当前时刻的单元状态,即决定从细胞状态中丢弃什么信息。该门读取和
,然后经过sigmoid层后,输出一个0-1之间的数
给每个在细胞状态
中的数字逐点相乘。
的值为0表示完全丢弃,1表示完全保留。结构如下图所示:
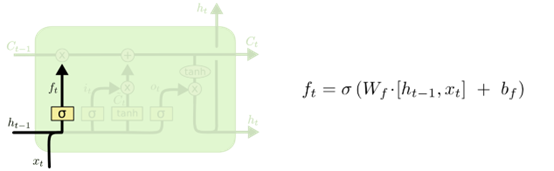
图5 遗忘门结构图
输入门负责决定保留多少当前时刻的输入到当前时刻的单元状态,包含两个部分,第一部分为sigmoid层,该层决定要更新什么值,第二部分为tanh层,该层把需要更新的信息更新到细胞状态里。tanh层创建一个新的细胞状态值向量,
会被加入到状态中。结构如下图:
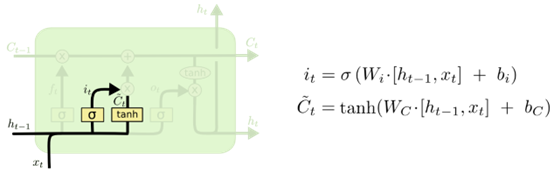
图6 输入门结构图
然后就到了更新旧细胞状态的时间了,将更新为
,把旧状态与
相乘,丢弃确定需要丢弃的信息,再加上
,这样就完成了细胞状态的更新,结构如下图所示:
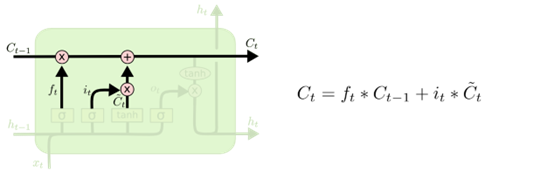
图7 更新旧细胞状态
输出门负责决定当前时刻的单元状态有多少输出,通过一个sigmoid层来确定细胞状态的哪个部分将输出出去。把细胞状态通过tanh进行处理,得到一个-1到1之间的值,并将它和sigmoid门的输出相乘,最终仅仅输出确定输出的部分。结构如下图所示:
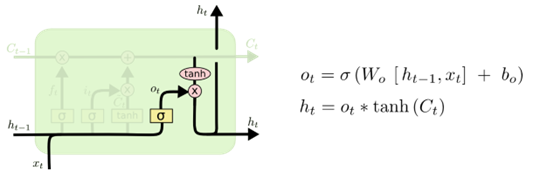
图8 输出门的结构
4、LSTM的训练过程
LSTM的参数训练算法,依然是反向传播算法。主要有如下三个步骤:
第一步:前向计算每个神经元的输出值。对于LSTM而言,依据前面介绍的算法,分别进行计算。
第二步:确定优化目标函数。在训练早期,输出值和预期值会不一致,于是计算每个神经元的误差项值,构造出损失函数。
第三步:根据损失函数的梯度指引,更新网络权值参数。与传统RNN类似,LSTM误差项的反向传播包括两个层面:一个是空间上层面的,将误差项向网络的上一层传播。另一个是时间层面上的,沿时间反向传播,即从当前t时刻开始,计算每个时刻的误差。
然后跳转第一步,重复做第一、二和三步,直至网络误差小于给定值。
关注微信公众号【有梦想的程序星空】,了解软件系统和人工智能算法领域的前沿知识,让我们一起学习、一起进步吧!



















 890
890

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











