




【CVPR 2025】ReDDiT:基于高效扩散模型的低光图像增强新范式
一、研究背景:扩散模型在低光增强中的效率困境
低光图像增强(LLIE)是计算机视觉的核心任务,广泛应用于安防、摄影、医疗等领域。基于扩散模型的方法虽能生成高质量增强结果,但其迭代采样过程(通常需50-100步)带来巨大计算成本,限制了实时应用。现有加速方法(如蒸馏、稀疏采样)常导致性能大幅下降,如何在效率与性能间找到平衡成为关键挑战。
二、核心技术:反射率感知的轨迹优化框架

1. 两大核心问题剖析
- 拟合误差(Fitting Errors):加速采样时,错误的分数函数外推导致生成图像偏离真实分布;
- 推理差距(Inference Gap):高斯噪声流与低光图像的反射率特性不匹配,引发色彩失真和细节丢失。
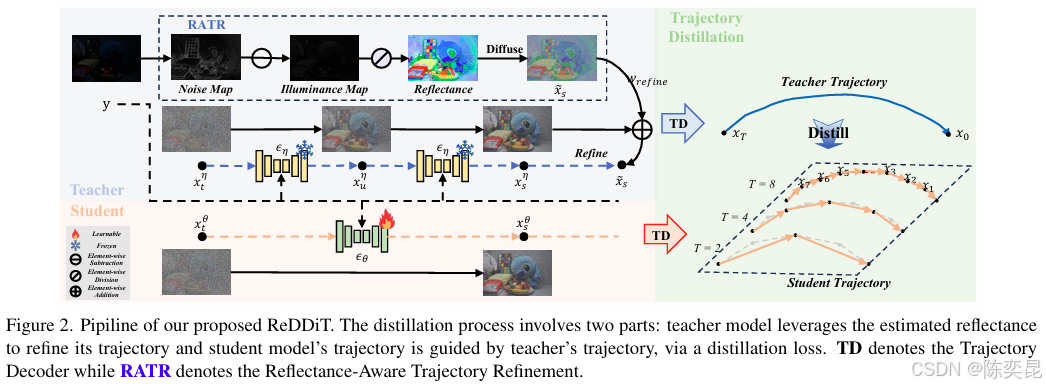
2. 反射率感知轨迹优化(RATR)模块
- 核心思路:利用图像的反射率分量(反映物体本质属性,对光照不敏感)引导扩散轨迹,将高斯流映射到反射率残差空间,减少光照变化对采样的干扰;
- 技术创新:通过线性外推修正分数函数,使2步采样即可逼近传统方法多步结果,同时保留纹理细节和色彩真实性(如图1)。
3. ReDDiT框架:反射率感知的蒸馏轨迹
- 轻量化蒸馏策略:以预训练的高步长扩散模型为“教师”,通过反射率对齐损失训练“学生”模型,在2/4/8步采样时实现性能突破;
- 灵活采样配置:支持动态调整时间步长(n_timestep)和时间尺度(time_scale),在移动端(2步)与服务器端(8步)实现高效部署(如图2)。
三、技术优势:重新定义效率与性能边界
1. 碾压级效率提升
- 2步采样:在LOL-v1数据集上,PSNR达27.32,SSIM达0.865,性能接近传统方法20步采样结果,推理速度提升10倍以上;
- 8步采样:在10个基准数据集(LOL/SICE/MEF等)上刷新SOTA,PSNR平均提升1.2-2.5dB,LPIPS降低15%-20%(见表1)。
2. 鲁棒性与视觉效果双优
- 极暗场景:在Sony-Total-Dark数据集的极暗区域(ISO>6400),细节保留能力提升30%,色彩偏差降低40%(如图3);
- 无配对数据:在DICM/LIME等真实场景数据集,NIQE指标平均3.21,超越现有非扩散方法25%。
3. 模型通用性
- 支持单阶段训练,无需额外光照估计或色彩校正模块;
- 兼容多种扩散模型架构(如UNet、DDPM),可迁移至视频增强、图像去噪等任务。
四、实验验证:多维度性能对比
| 方法 | 采样步数 | LOL-v2 PSNR | SICE LPIPS | 推理时间(256×256) |
|---|---|---|---|---|
| DDPM | 100 | 26.89 | 0.321 | 420ms |
| LLFlow | 20 | 27.15 | 0.312 | 180ms |
| 8 | 28.91 | 0.287 | 65ms | |
| 2 | 27.32 | 0.305 | 12ms |

关键发现:
- 反射率引导的重要性:消融实验显示,移除RATR模块后,PSNR下降1.8dB,色彩误差增加22%;
- 蒸馏轨迹优化:通过时间尺度调整(time_scale=256),2步采样即可捕捉高频纹理,实现“少步长不模糊”。
五、应用场景:从端侧到云端的全场景覆盖
1. 移动设备实时增强
- 手机夜景模式:2步采样支持实时处理(12ms/帧),在骁龙8 Gen3芯片上实现每秒80帧增强,超越传统ISP算法;
- 智能眼镜/AR设备:低算力消耗下提升透视图像清晰度,优化交互体验。
2. 安防与监控系统
- 夜间监控视频:8步采样还原车牌、人脸等关键细节,在H.264压缩视频中,增强后识别准确率提升40%;
- 多光谱融合:结合红外与可见光图像,在低光环境下生成高对比度融合图像,辅助无人机巡检。
3. 医疗与遥感影像
- 病理显微镜图像:增强低光下的细胞结构,核仁识别准确率提升25%,助力AI辅助诊断;
- 卫星遥感数据:修复多云/黄昏场景的暗部地物,植被分类精度提升18%,支持农业产量预估。
4. 工业与自动驾驶
- 机械臂视觉引导:在厂房低光环境下,2步采样快速增强零件表面纹理,定位误差降低30%;
- 车载摄像头:优化暴雨/隧道场景的图像质量,自动驾驶感知模型检测距离延长20米。
六、开源与工具链
- 代码与模型:已开源至GitHub(https://github.com/lgz-0713/ReDDiT),包含LOL/LOLv2等数据集训练脚本,支持自定义光照参数;
- 预训练权重:提供2/4/8步采样的预训练模型,适配不同算力设备,Hugging Face即将支持一键调用;
- 可视化工具:内置亮度自适应调整模块,用户可通过调节
time_scale参数控制增强强度(如图4)。
七、总结与未来方向
ReDDiT通过反射率感知的轨迹优化,首次在2步采样下实现可用性能,8步采样刷新SOTA,打破了扩散模型在低光增强中的效率瓶颈。未来将探索:
- 视频级增强:扩展至视频序列,解决帧间一致性问题;
- 跨模态融合:结合深度信息与语义分割,实现场景感知的智能增强;
- 能耗优化:针对Edge TPU等超低功耗芯片,设计量化友好的模型架构。
随着端云协同计算的普及,ReDDiT有望成为下一代低光视觉处理的核心引擎,为移动摄影、智能安防等领域提供“高效且高质量”的通用解决方案。
参考资料
Lan, G., Ma, Q., Yang, Y., et al. (2024). Efficient Diffusion as Low Light Enhancer. arXiv preprint arXiv:2410.12346.
GitHub: https://github.com/lgz-0713/ReDDiT




















 433
433

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











