



“ 微软用一个令人惊讶的高性能模型更新了其最小的模型系列。”
最新消息:Marah Abdin 和微软的一个团队发布了 Phi-4,这是一个拥有 140 亿个参数的大型语言模型,在数学和推理基准测试中优于 Llama 3.3 70B 和 Qwen 2.5(720 亿个参数)。该模型在 Azure AI Foundry 上可用,许可允许非商业使用,权重将于下周通过 Hugging Face 发布。
工作原理:Phi-4 是一个转换器,可处理多达 16,000 个输入上下文标记。作者构建预训练和微调数据集的方式是其相对于其他模型的大部分性能优势。
• 大部分预训练集是来自网络或现有数据集的高质量数据。作者使用了已知的高质量数据集和高质量网络数据存储库(如书籍和研究论文)。他们还使用经过训练的分类器过滤网站以识别高质量文本。
• 其余的预训练数据由 GPT-4o 生成或重写。给定来自网页、代码、科学论文和书籍的文本片段,GPT-4o 将它们重写为练习、讨论、问答对和结构化推理任务。然后,GPT-4o 遵循反馈循环,通过批评自己的输出并生成新的输出来提高其准确性。
• 作者以类似的方式根据他们获得的现有和新生成的数据对 Phi-4 进行了微调。
• 他们使用直接偏好优化 (DPO) 在两轮生成的数据上对其进行了进一步微调,该优化训练模型更有可能生成首选示例,而不太可能生成不首选示例。在第一轮中,作者通过识别生成的响应中的重要标记来生成首选/非首选对:如果在模型生成一个标记(作为部分响应的一部分)之后,它最终产生正确输出的概率显著提高(或下降),则他们认为该标记很重要。他们通过生成给定提示的多个完成并确定模型在生成给定标记后产生正确答案的次数百分比来测量这个概率。首选/非首选对(其中对的一个元素由输入、要生成的标记以及首选或非首选标签组成)将重要标记之前生成的标记作为输入,将重要标记作为首选标记,将降低概率的重要标记作为非首选标记。
• 在第二轮生成首选/非首选对并通过 DPO 进行微调时,作者从 GPT-4o、GPT-4 Turbo 和 Phi-4 生成响应,然后使用 GPT-4o 对它们进行评分。评分高的回答更受欢迎,评分低的回答则不受欢迎。
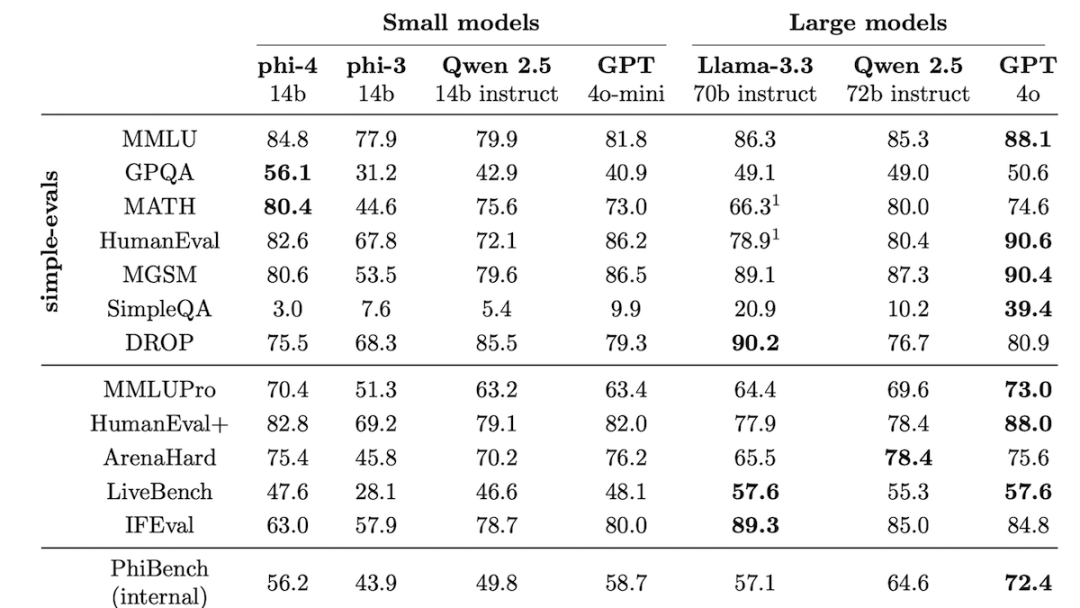
结果:在 13 个基准测试中,Phi-4 在 6 个方面优于 Llama 3.3 70B(其最新的开放权重竞争对手),在 5 个方面优于 Qwen 2.5。
• Phi-4 在 GPQA(研究生水平的问题和答案)和 MATH(竞赛级数学问题)上优于 Llama 3.3 70B、Qwen 2.5 和 GPT-4o。
• 但是,Llama 3.3 70B 赢得了 DROP(阅读理解)和 SimpleQA(回答有关基本事实的问题)。Llama 3.3 70B 在 IFEval(指令遵循)上的表现也明显更好。
重要性:Phi-4 表明,通过整理训练数据,仍有空间提高小型模型的性能,这遵循了古老的格言:更好的数据造就更好的模型。
我们的想法是:一些研究人员发现,Phi 的早期版本对某些基准测试表现出过度拟合的迹象。微软团队在论文中强调,他们已经改进了 Phi-4 的数据净化过程,并在其方法上添加了附录。我们相信,独立测试将证明 Phi-4 的表现与基准测试分数一样出色。
(本文系翻译,内容来自DeepLearning.AI,文章内容不代表本号立场)
觉得文章不错,顺手点个“点赞”、“在看”或转发给朋友们吧。

相关阅读:
关于译者

关注公众号看其它原创作品
坚持提供对你有用的信息
觉得好看,点个“点赞”、“在看”或转发给朋友们,欢迎你留言。


















 782
782

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









