






网页爬虫能够获取网页上的信息,要使用Python来爬取网页内容,需要安装requests模块,该模块可以用于获取网络数据。由于requests模块是Python的第三方模块,需要额外安装,安装requests模块非常简单,在VScode终端输入代码:pip install requests 然后回车即可安装。

备注:要在自己的电脑上使用requests模块,还需要在自己的电脑端安装。
之后安装相关模块也是以下这样操作。
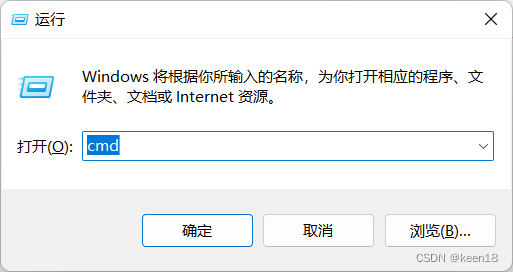
按电脑上的Windows键窗格不放再按R建,输入cmd再按回车,打开对话框启动器,输入相关代码安装。
对于爬虫来说,要获取网页中的内容,就需要网页的URL。

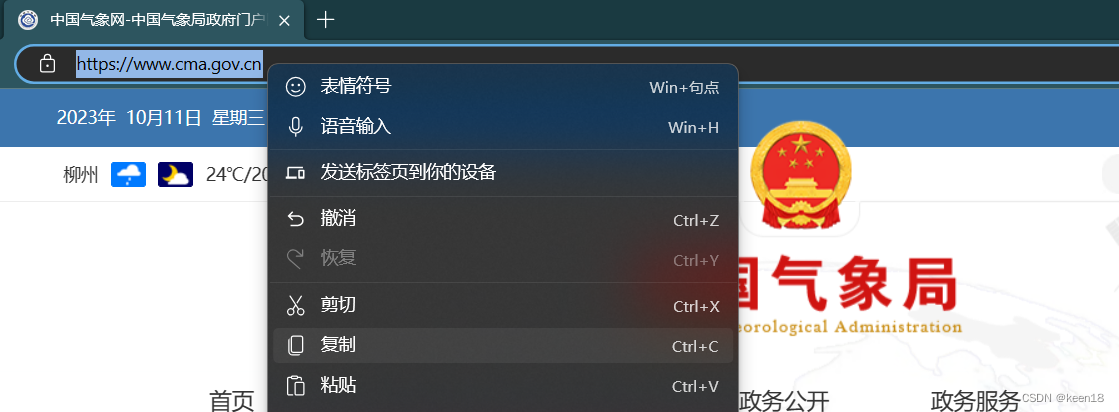
复制链接的方法如下图所示,打开网页,点击链接框,右键选择复制。
使用requests.get()方法获取案例URL网页数据

在请求某些网站时,会收到SSLError异常,原因是因为HTTTPS的安全协议造成的,这时可以在请求网页时添加一个参数verify=False,表示忽略证书认证。
即:response=requests.get(url,verify=False)
在浏览器中查看请求方法(推荐使用Chrome浏览器)
1.打开Chrome浏览器
2.右键选择【检查】
3.找到【Network】
4.将链接复制过去,打开网页
5.找到名为【example-post-3/】
6.点击该文件,查看【Headers】
7.找到【Requests Headers】
8.查看方法method:GET
获取网页内容
要用到.text属性,该属性能够将获取到的网页信息提取出来。由于网页内容较多,可以用切片的方法,先输出前1000个字符。(网页源代码)

切片截取遵从“左闭右开”原则,可以将字符串按照指定的位置进行分割。
解析模块Beautiful Soup
BeautifulSoup 是 Python 的一个 HTML 或 XML 的解析模块,可以用它来从网页中提取想要的数据。XML设计用来传送及携带数据信息,不用来表现或展示数据,HTML则用来表现数据,所以XML用途的焦点是它说明数据是什么,以及携带数据信息。
BeautifulSoup不是一个内置模块,所以在使用前要先通过代码 pip install bs4 在终端中进行安装。
网络爬虫的最终目的就是过滤选取网络信息,最重要的部分可以说是解析器。解析器的优劣决定了爬虫的速度和效率。
lxml 不是一个内置模块,所以在使用前要先通过代码 pip install lxml 在终端中进行安装。
安装完成后,我们需要使用 bs4 模块中的 BeautifulSoup 类。
这就要使用 from...import 从 bs4 中导入 BeautifulSoup 。

创建 BeautifulSoup 对象,将 BeautifulSoup 对象赋值给变量 soup

在创建一个 BeautifulSoup 对象时,需要传入两个参数:
第一个参数
是需要解析的 HTML 文本,在这里我们传入变量 html。
第二个参数
是解析器的类型,这里我们使用的是lxml。(不要漏掉引号)
查询符合条件的节点
可以使用 BeautifulSoup 中的 find_all() 函数,获取所有符合指定条件的节点。可以根据标签名,获取soup中的节点。
变量 soup 是一个 BeautifulSoup 对象,调用 soup 使用 find_all() 函数就能查找 HTML 中的内容。
find_all() 函数可以查询 soup 中所有符合条件的元素,组成一个列表赋值给tako。
name参数
find_all(name="标签") 根据标签名查询节点。
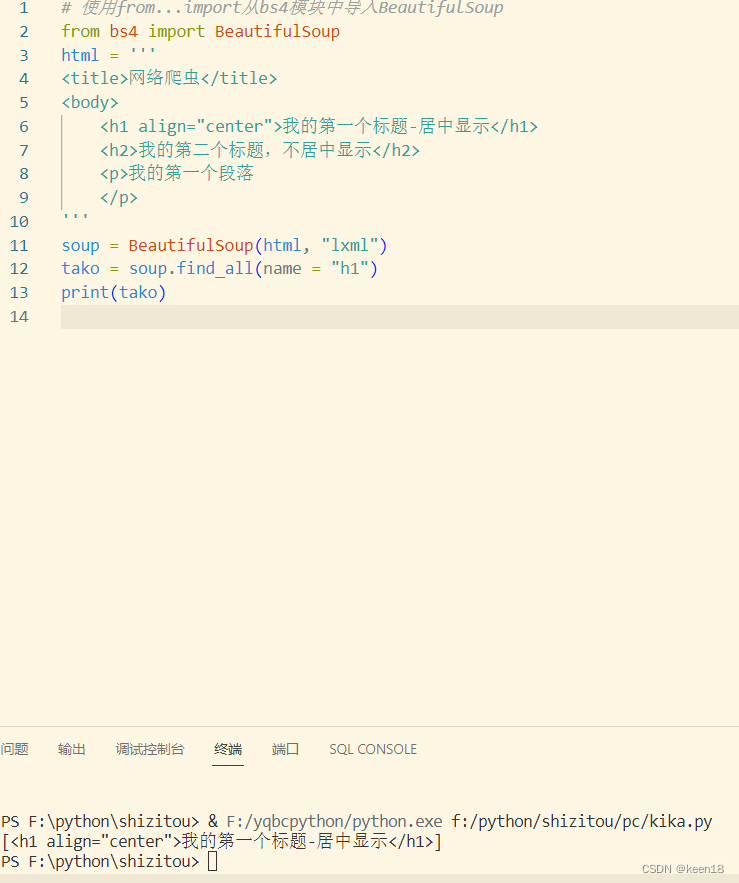
示例代码中,如果我们想要获取 h1 标签所在的节点,可以在 find_all() 中,传入 name 参数,其参数值为 h1 。
由于 name 可以省略,我们也可以直接传入参数值。
将返回的结果,赋值给一个变量。输出的结果是包含所有 h1 节点的列表。
获取标签内容
之前获取到的内容包含 h1 节点,可以调用 .string 属性 ,用来获取节点中的内容,把文字提取出来。
但是由于 find_all() 返回的是一个列表,我们不能直接调用 .string 属性。我们需要使用 for 循环遍历列表,获取每一个节点字符串,再来调用 .string 属性获取节点中的标签里的内容。
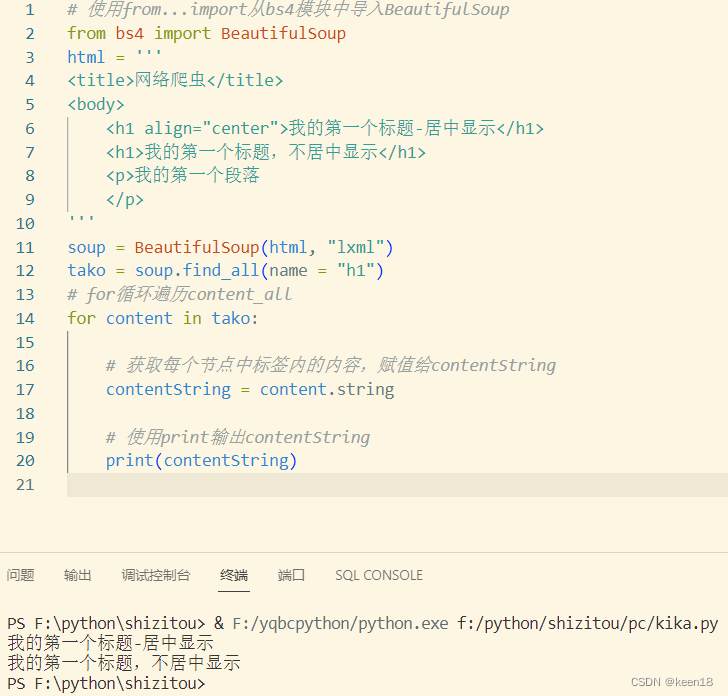
.string 属性只能提取单个节点或节点统一的内容。
提取单个节点内容:
例如
<p><em>老子人间无著处</em></p>
p 节点包含一个子节点 em ,由于 p 节点有且只有一个子节点,使用 .string 属性时,会输出 em 节点的 .string 内容。
提取节点包含多个子节点时:
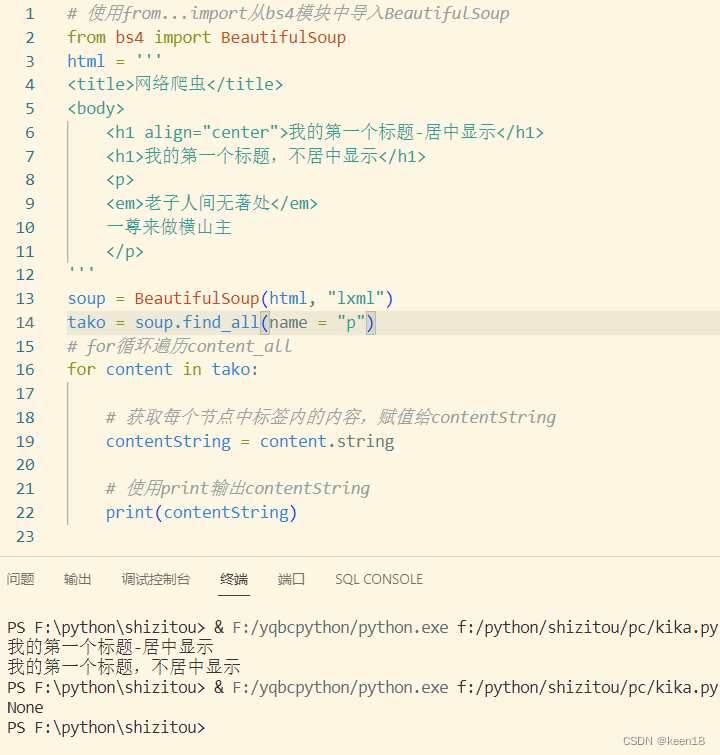
当定位的节点中同时包含了多个子节点时,示例中标黄的部分:有两个节点,一个节点是 em 标签内容,另一个节点是纯文字。
使用 .string 属性 属性时,不清楚应该调用哪个节点的内容,会返回None值。
<p>
<em>老子人间无著处</em>
一尊来做横山主
</p>
获取全部内容
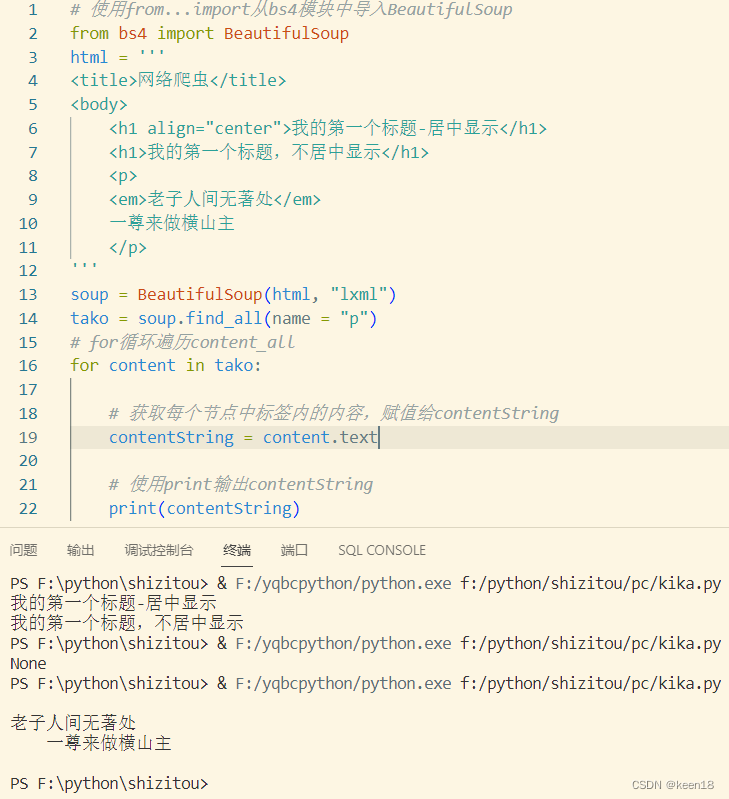
遇到节点中既包含其他节点,也有文字时,可以使用 .text 属性来提取内容。
.text 属性能直接提取该节点中的所有文字,并返回字符串格式。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









