







TL;DR
2022 年谷歌发表的 transformer 结构优化论文,本文提出了两种创新方法——门控注意单元(GAU)和混合块注意力(Mixed Chunk Attention),共同构成FLASH模型。FLASH 在短序列和长序列任务中均能匹配 Transformer 的质量,同时显著提升训练速度,为高效长序列建模提供了新思路。
Paper name
Transformer Quality in Linear Time
Paper Reading Note
Paper URL:
- https://arxiv.org/abs/2202.10447
Introduction
背景
- Transformer 模型随输入长度呈二次复杂度增长。这一限制阻碍了 Transformer 处理长期信息,而长期信息对于许多应用来说至关重要。
- 为了加速 Transformer 在长上下文中的计算效率,研究人员提出了多种更高效的注意力机制。现有高效注意力方法通常存在以下缺陷
- 质量下降:相比于增强后的 Transformer,现有的高效注意力方法往往会导致显著的质量下降,而这种质量损失超过了它们在计算效率上的优势
- 实际开销较大:许多高效注意力方法在 Transformer 层中引入了额外的复杂性,并需要大量的内存重排操作,导致它们的 理论复杂度 与 实际加速性能(在 GPU 或 TPU 上的表现) 之间存在较大差距。
- 自回归训练效率低:大多数注意力线性化技术在推理过程中可以实现快速解码,但在 自回归任务(如语言建模) 训练时却极为缓慢。这主要是因为它们采用 类似 RNN 的逐步状态更新方式,需要在大量训练步骤中不断维护和更新状态,无法充分利用现代加速器的并行计算能力。
本文方案
- 提出了以下两种模型单元和架构
- 提出了一种名为门控注意单元(Gated Attention Unit, GAU)的简单层,它允许使用较弱的单头注意力机制,同时仅带来最小的质量损失
- 提出了一种与该新层互补的线性近似方法,最终得到的模型被命名为 FLASH,在短(512)和长(8K)上下文长度上均能匹配改进版 Transformer 的困惑度(perplexity)
- 在 Wiki-40B 数据集上实现了最高 4.9 倍的训练加速,在 PG-19 数据集上达到了 12.1 倍加速;在 C4 数据集上的掩码语言建模任务中,训练速度提升了 4.8 倍
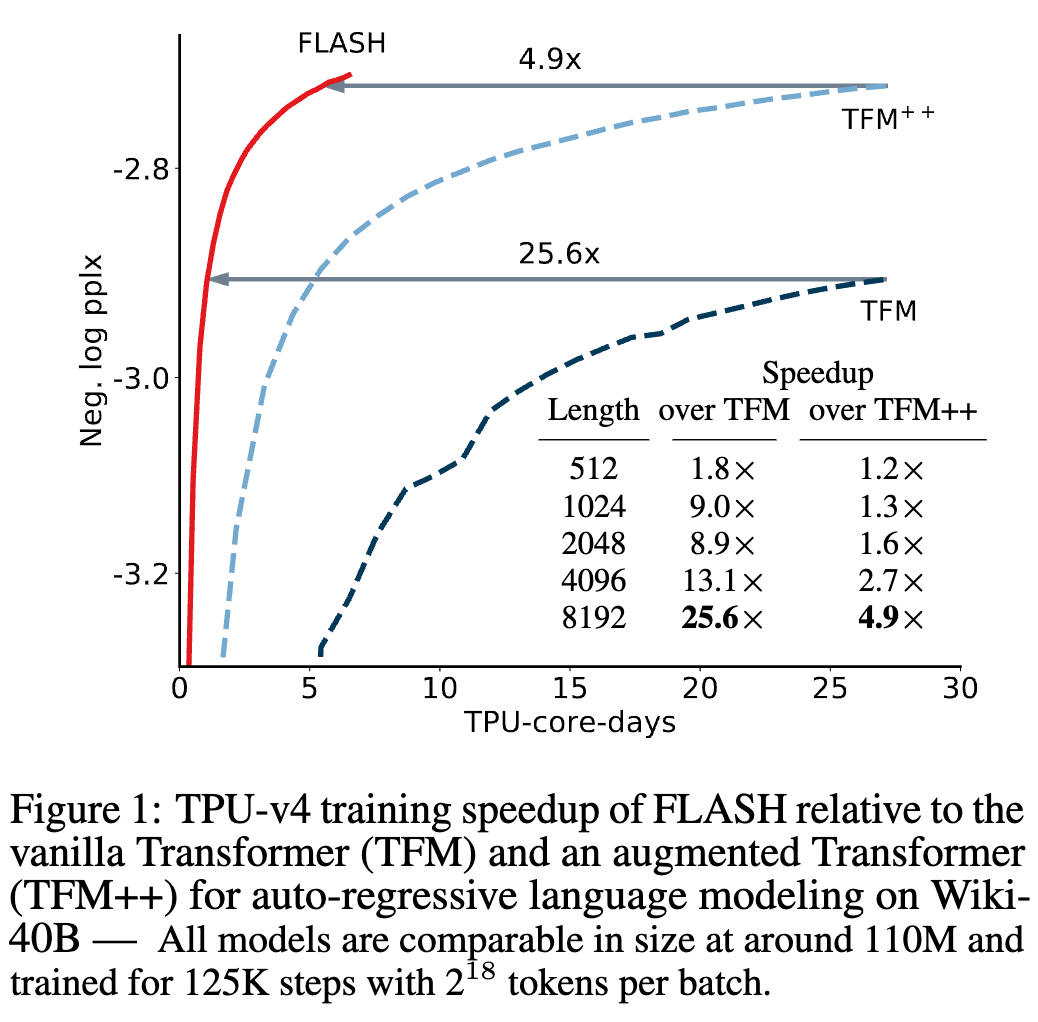
Methods
门控注意单元(Gated Attention Unit, GAU)
- 门控注意单元(GAU) 是比 Transformer 更简单但更高效的计算层。虽然 GAU 仍然具有 随上下文长度呈二次复杂度的计算成本,但它更适合作为后续近似方法的基础。首先介绍相关层的背景:
标准 MLP
设 X ∈ R T × d X \in \mathbb{R}^{T \times d} X∈RT×d 为 T T T 个 token 的表示,Transformer 中的 MLP 计算如下:
O = ϕ ( X W u ) W o O = \phi(X W_u) W_o O=ϕ(XWu)Wo
其中, W u ∈ R d × e W_u \in \mathbb{R}^{d \times e} Wu∈Rd×e, W o ∈ R e × d W_o \in \mathbb{R}^{e \times d} Wo∈Re×d, d d d 为模型维度, e e e 为扩展的中间层维度, ϕ \phi ϕ 为逐元素的激活函数。
门控线性单元(Gated Linear Unit, GLU)
GLU 是在 MLP 的基础上加入门控机制的改进(Dauphin 等,2017)。GLU 在多个任务中被证明有效(Shazeer,2020;Narang 等,2021),并已应用于最先进的 Transformer 语言模型(Du 等,2021;Thoppilan 等,2022)。其计算如下:
U = ϕ u ( X W u ) , V = ϕ v ( X W v ) ∈ R T × e U = \phi_u(X W_u), \quad V = \phi_v(X W_v) \in \mathbb{R}^{T \times e} U=ϕu(XWu),V=ϕv(XWv)∈RT×e
O = ( U ⊙ V ) W o ∈ R T × d O = (U \odot V) W_o \in \mathbb{R}^{T \times d} O=(U⊙V)Wo∈RT×d
其中 ⊙ \odot ⊙ 表示逐元素乘法。在 GLU 中,每个表示 u i u_i ui 由另一个与相同 token 关联的表示 v i v_i vi 进行门控。
门控注意单元(GAU)
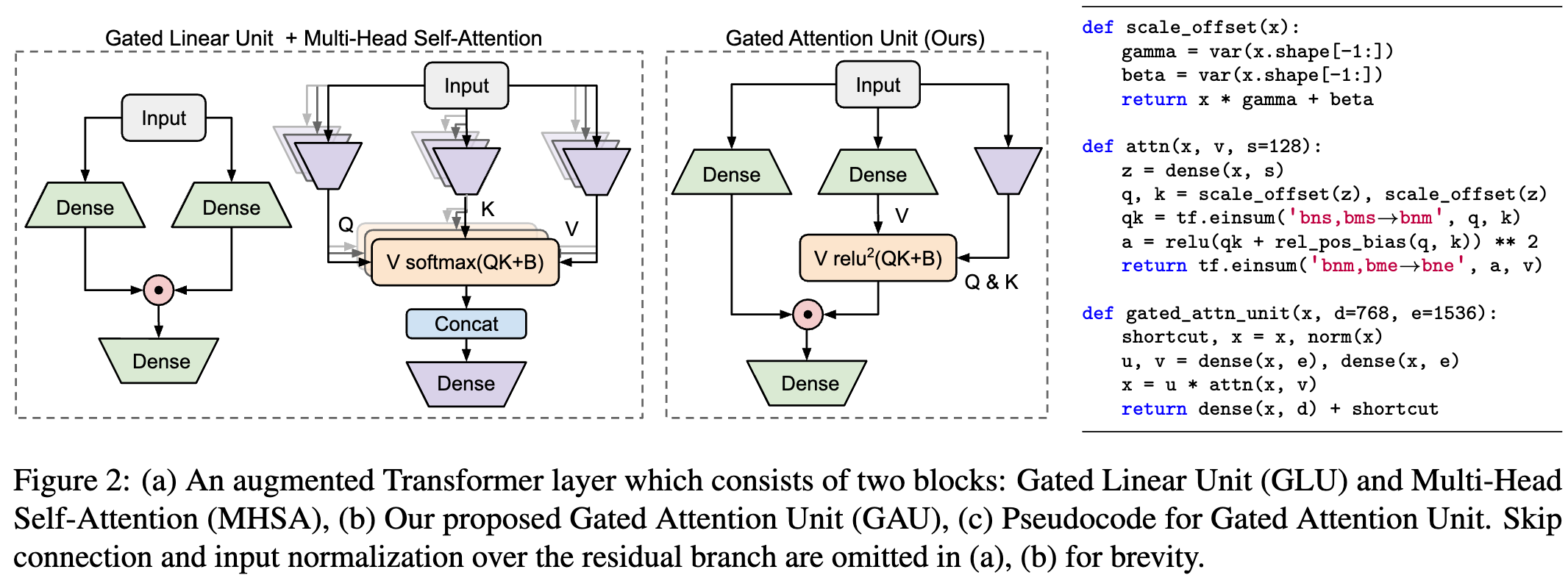
GAU 的核心思想是 将注意力和 GLU 统一成一个计算层,并尽可能共享它们的计算(如图 2 所示)。这样不仅提高了 参数/计算效率,还能自然引入 强大的注意力门控机制。具体而言,GAU 推广 了 GLU 中的公式:
O = ( U ⊙ V ^ ) W o , V ^ = A V O = (U \odot \hat{V}) W_o, \quad \hat{V} = A V O=(U⊙V^)Wo,V^=AV
其中, A ∈ R T × T A \in \mathbb{R}^{T \times T} A∈RT×T 为 token 之间的注意力权重。与 GLU 始终使用 v i v_i vi 来门控 u i u_i ui(两者都与相同 token 相关)不同,GAU 用注意力计算出的 v ^ i = ∑ j a i j v j \hat{v}_i = \sum_j a_{ij} v_j v^i=∑jaijvj 代替 v i v_i vi,从所有可用的 token 中“检索”更相关的信息。当 A A A 为单位矩阵时,该公式将退化为 GLU。
与 Liu 等(2021)的研究结果一致,GAU 的门控机制允许使用比 MHSA 更简单、更弱 的注意力机制,而不会影响质量:
Z = ϕ z ( X W z ) ∈ R T × s Z = \phi_z (X W_z) \in \mathbb{R}^{T \times s} Z=ϕz(XWz)∈RT×s
A = relu 2 ( Q ( Z ) K ( Z ) ⊤ + b ) ∈ R T × T A = \text{relu}^2 (Q(Z) K(Z)^\top + b) \in \mathbb{R}^{T \times T} A=relu2(Q(Z)K(Z)⊤+b)∈RT×T
其中, Z Z Z 是共享表示( s ≪ d s \ll d s≪d), Q Q Q 和 K K K 是两个轻量级变换,对 Z Z Z 进行逐维缩放和平移(类似于 LayerNorm 的可学习参数), b b b 为相对位置偏置。此外,我们发现 在 GAU 中 softmax 可以被替换为更简单的激活函数。
表 1 展示了不同修改对 GAU 质量的影响:
| 修改 | PPLX (LM/MLM) | 参数量 (M) |
|---|---|---|
| 原始 GAU | 16.78 / 4.23 | 105 |
| relu² → softmax | 17.04 / 4.31 | 105 |
| 单头 → 多头 | 17.76 / 4.48 | 105 |
| 无门控 | 17.45 / 4.58 | 131 |
此外,GAU 仅在 GLU 之上引入了一个小型的 稠密矩阵 W z W_z Wz(参数量 d s d s ds),相比于 Transformer 中 MHSA 的 4 d 2 4d^2 4d2 参数,其计算复杂度大幅降低。通过设定 e = 2 d e = 2d e=2d,可以 用两个 GAU 层替换每个 Transformer 块(MLP/GLU + MHSA),同时保持相似的模型大小和训练速度。
基于 GAU 的快速线性注意力(FLASH)
前面的研究给出了两个启发,使我们能够扩展 GAU 以处理长序列:
- GAU 的门控机制允许使用更弱(单头、无 softmax)的注意力,而不会损失质量。如果将这一思想扩展到长序列建模,GAU 也能增强近似(弱)注意力机制(如 局部注意力、稀疏注意力、线性注意力)的效果。在接下来的部分,我们将介绍如何利用这一特点,开发 真正高效的线性注意力模型 FLASH。
- 额外的注意力模块数量加倍的影响:此外,由于 MLP+MHSA≈2×GAU 在计算成本上是等价的,因此 GAU 天然具有两倍的注意力模块数量。由于近似注意力通常需要更多层才能捕获完整的依赖关系(Dai 等,2019;Child 等,2019),这一特性使 GAU 在处理长序列时更具吸引力。基于这一直觉,我们首先回顾了一些现有的 长序列建模方法,然后介绍 如何让 GAU 在长序列上以线性时间实现 Transformer 级别的质量。
现有的线性复杂度变体
部分注意力(Partial Attention)
一种常见的方法是使用 局部/稀疏注意力 近似完整的注意力矩阵,这些方法包括:
- 局部窗口注意力(Dai 等,2019;Rae 等,2019)
- 局部 + 稀疏注意力(Child 等,2019;Li 等,2019;Beltagy 等,2020;Zaheer 等,2020)
- 轴向注意力(Ho 等,2019;Huang 等,2019)
- 基于哈希(Kitaev 等,2020)或聚类(Roy 等,2021)学习的模式
虽然这些方法不能完全匹配完整注意力的效果,但它们通常能够 通过扩展至更长的序列来获得质量提升。然而,这类方法的主要问题在于,它们 涉及大量的不规则或规则的内存重排操作(如 gather、scatter、slice 和 concatenation),这些操作 不适用于现代加速器的高并行性计算,特别是 TPU 这类专用 ASIC 硬件。因此,它们的 理论效率和实际加速效果 之间通常存在较大差距。因此,在本研究中,我们 刻意减少了模型中的内存重排操作。
线性注意力(Linear Attention)
另一种流行的方法是 通过分解注意力矩阵并重新排列矩阵乘法的顺序 来线性化计算(Choromanski 等,2020;Wang 等,2020;Katharopoulos 等,2020;Peng 等,2021)。其计算公式如下:
V ^ lin = Q ( K ⊤ V ) ≈ V ^ quad = Softmax ( Q K ⊤ ) V \hat{V}_{\text{lin}} = Q (K^\top V) \approx \hat{V}_{\text{quad}} = \text{Softmax} (Q K^\top) V V^lin=Q(K⊤V)≈V^quad=Softmax(QK⊤)V
其中, Q , K , V ∈ R T × d Q, K, V \in \mathbb{R}^{T \times d} Q,K,V∈RT×d 分别为 查询(query)、键(key)和值(value)。这种 重排计算顺序 使得复杂度从 O ( T 2 d ) O(T^2 d) O(T2d) 降至 O ( T d ) O(T d) O(Td)。
线性注意力的 另一个优点 是,在推理过程中,每个 自回归解码步骤 的计算和内存需求是 常数:
M t = M t − 1 + K t V t ⊤ M_t = M_{t-1} + K_t V_t^\top Mt=Mt−1+KtVt⊤
这意味着:
- 只需维护一个 O ( d 2 ) O(d^2) O(d2) 大小的缓存。
- 每个新输入 t t t 仅需 O ( d 2 ) O(d^2) O(d2) 计算量来更新 M t M_t Mt。
相比之下,完整的二次注意力 在 每一步解码时都需要 O ( T d ) O(T d) O(Td) 计算和内存,因为每个新输入必须 与所有先前的输入进行注意力计算。
然而,线性注意力在 自回归训练阶段存在严重的低效问题:
- 由于 自回归因果约束,每个时间步的查询 Q t Q_t Qt 需要不同的缓存值 M t = K : t ⊤ V : t M_t = K_{:t}^\top V_{:t} Mt=K:t⊤V:t。
- 这意味着模型 需要存储 T T T 个不同的 M t M_t Mt,而非自回归情况下的 单个 K ⊤ V K^\top V K⊤V。
- 在理论上,可以通过 累积求和(cumsum) 计算:
M t = ∑ i = 1 t K i V i ⊤ M_t = \sum_{i=1}^{t} K_i V_i^\top Mt=i=1∑tKiVi⊤
但在实践中,这种 累积求和操作 在现代加速器上 引入了类似 RNN 的顺序依赖,导致:
- 并行计算受限
- 每个步骤都需要 T T T 次内存访问
- 导致实际计算速度大幅下降
在 TPU 和 GPU 上,直接计算完整二次注意力甚至比线性注意力更快。
混合块注意力(Mixed Chunk Attention)
基于现有 线性复杂度注意力方法 的优缺点,我们提出了一种新的 混合块注意力(Mixed Chunk Attention),结合了 部分注意力 和 线性注意力 的优势,如图 4 所示。以下是具体方法。
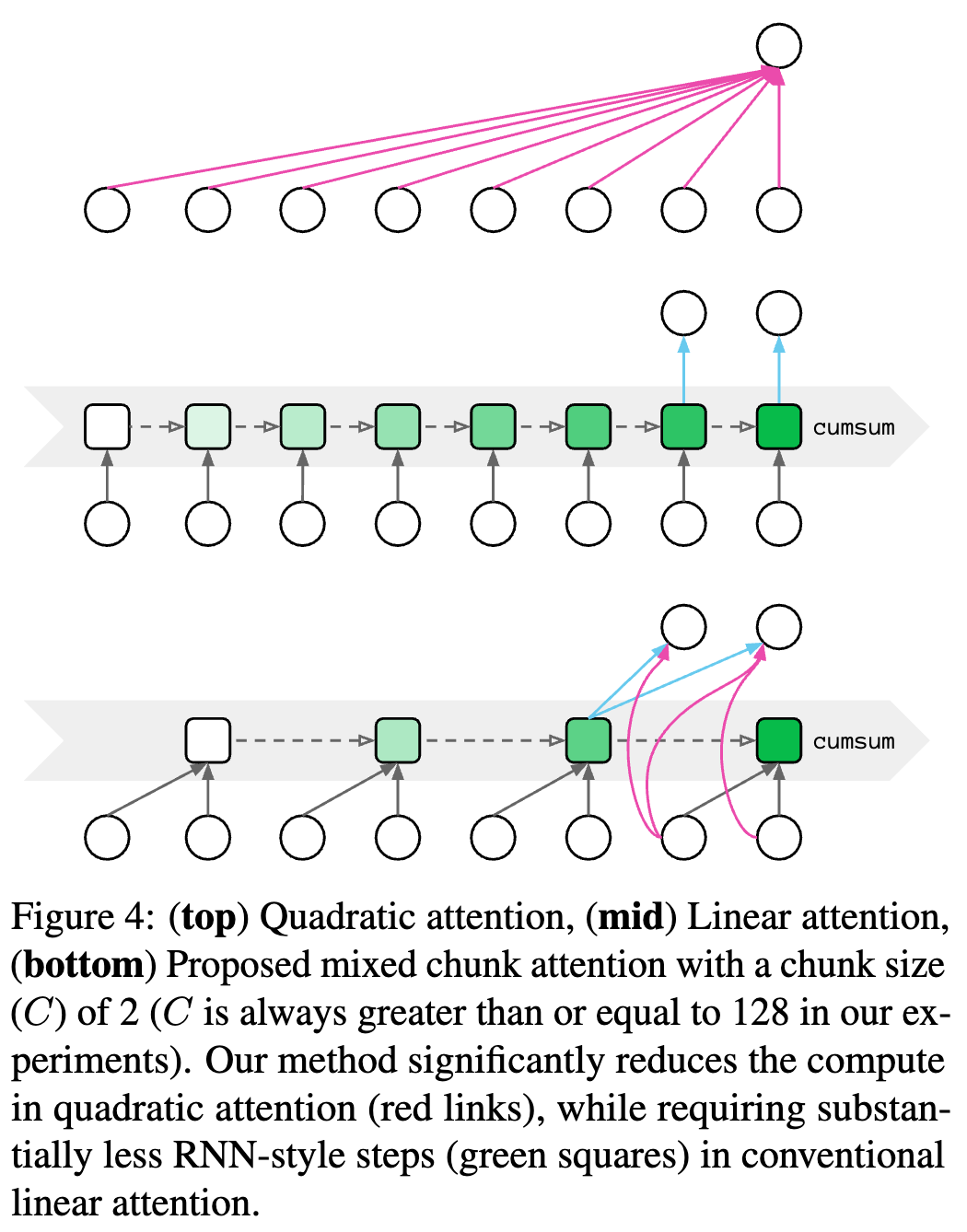
预处理
首先,我们将输入序列 划分为 G G G 个不重叠的块(chunk),每个块大小为 C C C,即:
[ T ] → [ T / C × C ] [T] \rightarrow [T / C \times C] [T]→[T/C×C]
然后,对每个块 g g g,根据 GAU 公式(见式 (1) 和 (4)),计算:
U g ∈ R C × e , V g ∈ R C × e , Z g ∈ R C × s U_g \in \mathbb{R}^{C \times e}, \quad V_g \in \mathbb{R}^{C \times e}, \quad Z_g \in \mathbb{R}^{C \times s} Ug∈RC×e,Vg∈RC×e,Zg∈RC×s
接着,我们从 Z g Z_g Zg 生成四种注意力头:
Q g quad , K g quad , Q g lin , K g lin Q_g^{\text{quad}}, K_g^{\text{quad}}, Q_g^{\text{lin}}, K_g^{\text{lin}} Qgquad,Kgquad,Qglin,Kglin
这些变换都是 逐维缩放和平移(计算开销极低)。接下来,我们介绍 如何高效地近似 GAU 的注意力。
局部块内注意力
首先,在 每个块内 独立应用 二次注意力:
V ^ g quad = ReLU 2 ( Q g quad K g quad ⊤ + b ) V g \hat{V}_g^{\text{quad}} = \text{ReLU}^2 (Q_g^{\text{quad}} K_g^{\text{quad} \top} + b) V_g V^gquad=ReLU2(QgquadKgquad⊤+b)Vg
其计算复杂度为:
O ( G × C 2 × d ) = O ( T C d ) O(G \times C^2 \times d) = O(T C d) O(G×C2×d)=O(TCd)
如果 C C C 为常数,则该部分计算复杂度对 T T T 是线性的。
全局块间注意力
此外,我们使用 全局线性注意力 处理 块间的长程交互:
-
非因果(Non-Causal):
V ^ lin = Q lin ( ∑ h = 1 G K h lin ⊤ V h ) \hat{V}^{\text{lin}} = Q^{\text{lin}} \left( \sum_{h=1}^{G} K_h^{\text{lin} \top} V_h \right) V^lin=Qlin(h=1∑GKhlin⊤Vh)
-
因果(Causal):
V ^ lin = Q lin ( ∑ h = 1 g − 1 K h lin ⊤ V h ) \hat{V}^{\text{lin}} = Q^{\text{lin}} \left( \sum_{h=1}^{g-1} K_h^{\text{lin} \top} V_h \right) V^lin=Qlin(h=1∑g−1Khlin⊤Vh)
注意:上述求和运算是在 块级别 进行的,因此相比于 token 级别的线性注意力,累积求和的步数减少了 C C C 倍(通常设 C = 256 C=256 C=256),大幅加快训练速度。
最终, V ^ g quad \hat{V}_g^{\text{quad}} V^gquad 和 V ^ lin \hat{V}^{\text{lin}} V^lin 相加,并经过门控和后处理:
O g = [ U g ⊙ ( V ^ g quad + V ^ lin ) ] W o O_g = \left[ U_g \odot (\hat{V}_g^{\text{quad}} + \hat{V}^{\text{lin}}) \right] W_o Og=[Ug⊙(V^gquad+V^lin)]Wo
讨论:为什么混合块注意力更快?
- 自回归训练加速:由于 块化操作,自回归训练中的顺序依赖 从 T T T 下降到 T / C T/C T/C,大幅提高了训练速度。
- 非重叠块注意力:相比 重叠局部注意力(如 Longformer、BigBird),我们的方法减少了 内存重排操作,在 TPU 上表现更优。
Experiments
- FLASH 在长序列上达到了 Transformer 级别的质量,同时实现了线性复杂度加速
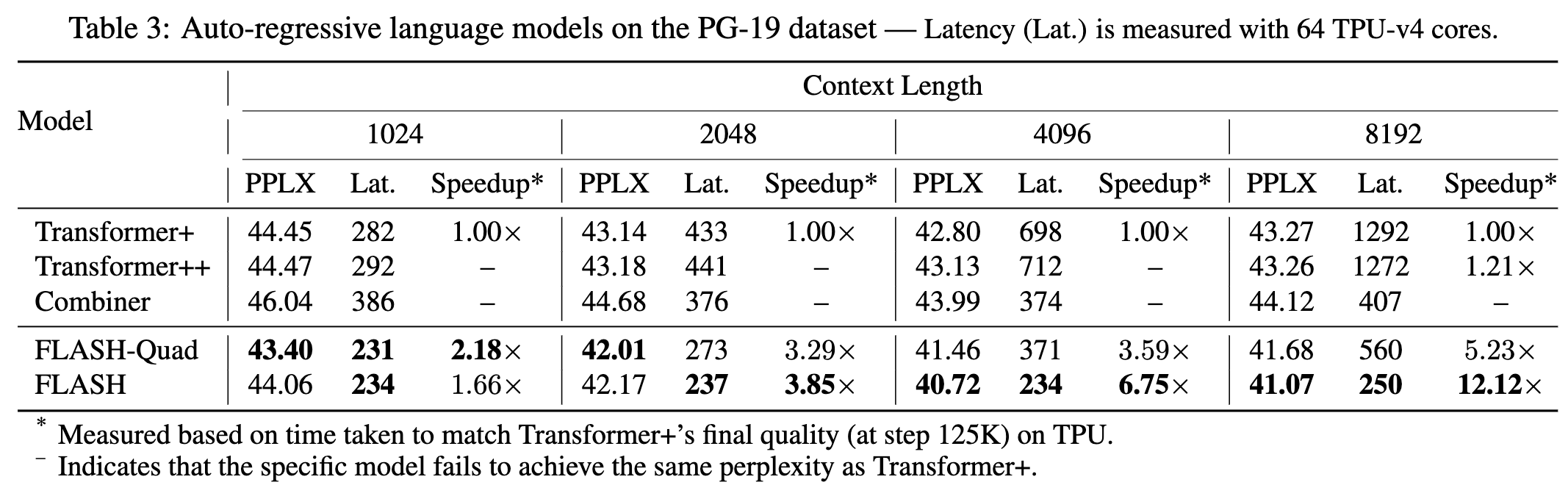
Conclusion
- GAU 以简洁的结构融合门控与注意力,显著降低了参数量和计算成本,同时保持模型表现力。
- 论文的研究思路很值得参考,从基于 GLU 的思考,想办法降低 attention 在模型中的重要性占比,然后用线性 attention 近似就不会造成过大的性能损失,整个逻辑很顺畅。


















 901
901

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









