



 该文介绍了如何利用Python的Selenium库处理需要登录的网站,通过自动化浏览器操作下载EarthData上的北半球积雪海冰数据。作者详细讲解了设置浏览器驱动、登录过程、文件下载路径以及处理大量下载时的策略,包括随机休眠和用户代理,最终成功下载了2846个数据文件。
该文介绍了如何利用Python的Selenium库处理需要登录的网站,通过自动化浏览器操作下载EarthData上的北半球积雪海冰数据。作者详细讲解了设置浏览器驱动、登录过程、文件下载路径以及处理大量下载时的策略,包括随机休眠和用户代理,最终成功下载了2846个数据文件。
使用 python selenium 批量下载需要登录的网站上数据
文章目录
主要目标
写这个东西主要是为了记录一下自己批量下载 EarthData 上的空间数据的过程,以北半球积雪海冰数据下载为例。
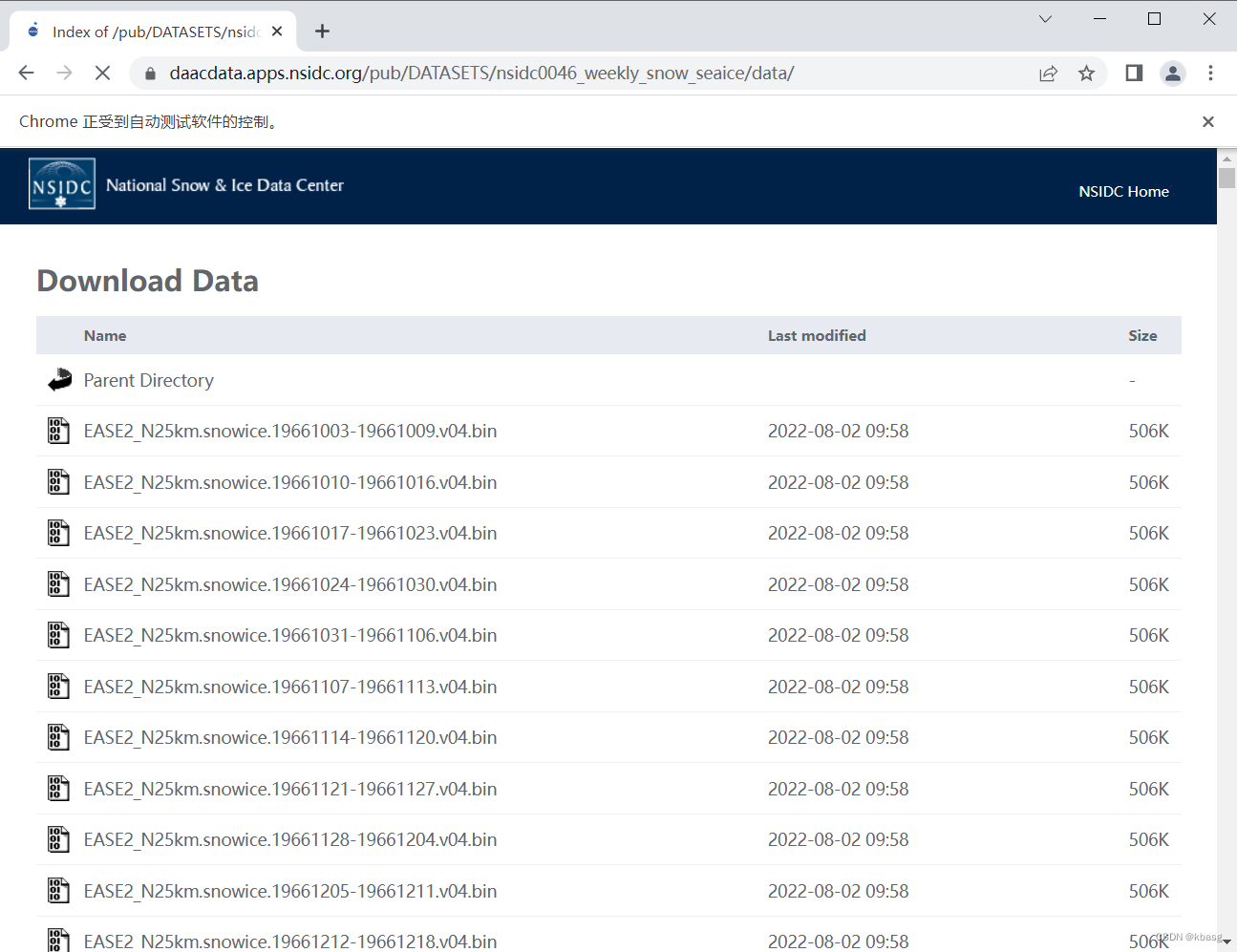
网页是这样的
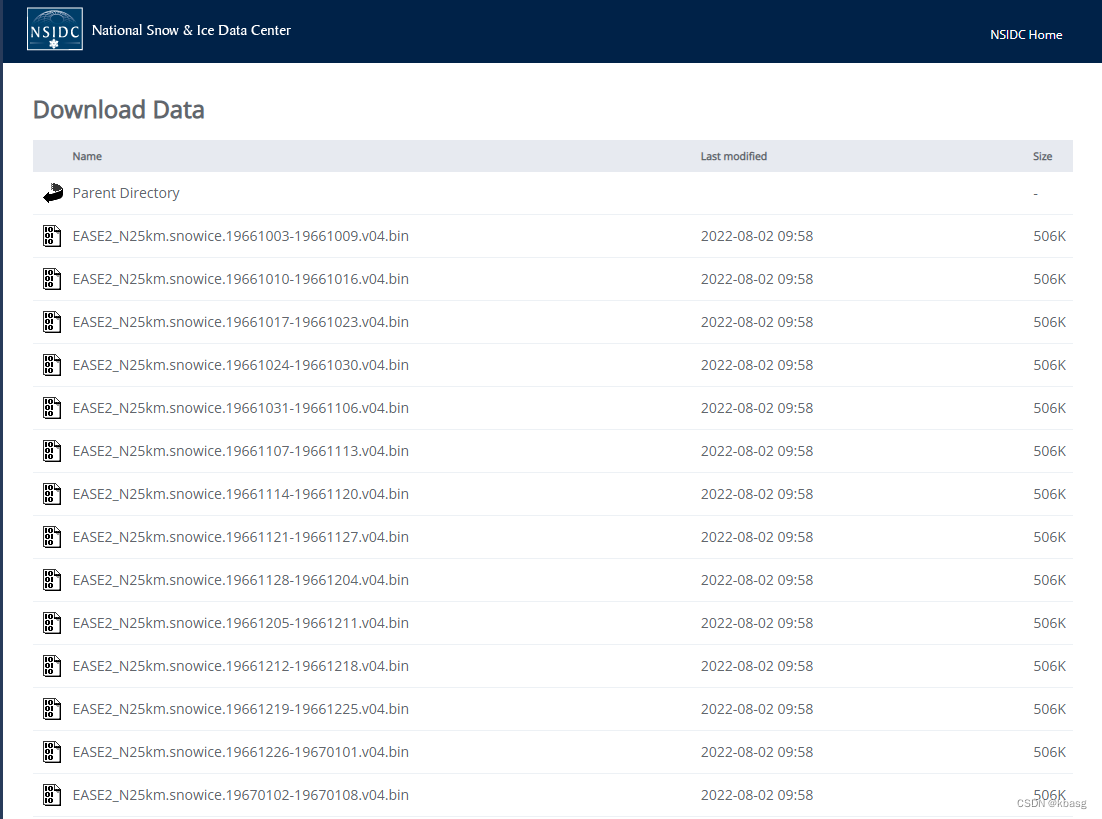
主要的问题
这个页面上共有2000多个文件链接,由于网页不提供 ftp下载,且我又不想装 wget,所以就想着使用python 爬虫来做。使用爬虫下载earthdata 上的数据主要有两个问题,(1)需要登录:之前用python下载earth上的数据时,我是从登录的网页上 找到 cookie 然后通过写入 headers完成的, 但是这样有点麻烦;(2)下载文件过多时,容易被服务器识别到,导致连接不到,之前主要是通过 随机的 user agent 和 下载过程中 随机休眠来避免的。
主要的代码内容
为了避免上面的问题,就想到了使用 selenium来完成 登录并下载数据的过程,关于selenium的介绍网上有很多, 有详细的安装和 配置教学。
安装正确的浏览器Drivers
需要根据你自己电脑上已经安装的浏览器及版本去下载对应的Drivers,这个网页给了常用浏览器的Drivers下载网站。以chrome浏览器为例,在设置中可以找到版本信息。
虽然网上看到很多教程说 将下载的驱动加入到 环境变量的 path中就可以正常使用, 但是我自己试了一下 好像不太行,因此 就直接在代码中 说明 driver的路径。
使用的包
from selenium import webdriver
from selenium.webdriver.common.by import By
import re
from bs4 import BeautifulSoup
import time
import random
其中 selenium包 用来实现 浏览器操作
re包 用来完成一些可能需要的 正则表达式匹配
bs4 包 用来完成一些需要的 网页解析
time 和 random 包 则主要是用来设置休眠
通过selenium 操作浏览器
options = webdriver.ChromeOptions()
prefs = {'profile.default_content_settings.popups': 0,
'download.default_directory': 'G:\\weekly_snow_seaice'}
options.add_experimental_option('prefs', prefs)
browser = webdriver.Chrome(options=options, executable_path='D:/chrome_driver/chromedriver.exe')
通过 options 屏蔽弹窗 并设置下载文件的存储路径(download.default_directory)
通过 executable_path 说明 上面下载的浏览器驱动的 路径
需要说明的是,在设置存储路径时,开始写成了以下的形式
r'G:/weekly_snow_seaice'
结果后面下载是 出现下载错误
运行以上代码,可以看到 打开了一个 空的浏览器页面,如下所示
登录网站
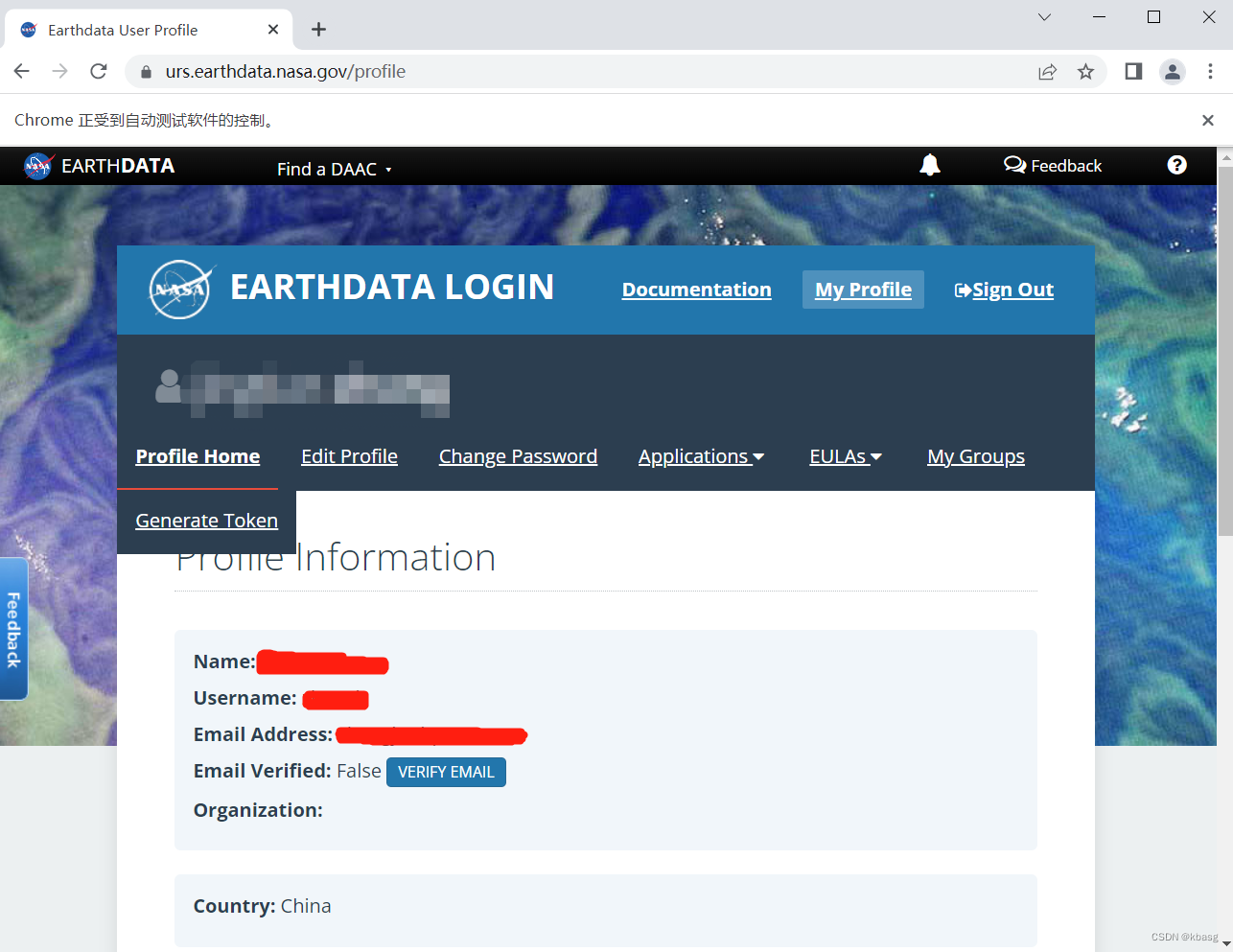
browser.get('https://urs.earthdata.nasa.gov/home')
browser.find_element(By.ID, "username").send_keys("......") # 填入用户名
browser.find_element(By.ID, "password").send_keys("......") # 填入密码
browser.find_element(By.NAME, "commit").click()
打开earthdata的登录页面,使用 selenium 的 find_element方法 找到 填写用户名和密码的位置,并点击登录
打开数据下载页面
browser.get('https://daacdata.apps.nsidc.org/pub/DATASETS/nsidc0046_weekly_snow_seaice/data/')
html = browser.page_source
soup=BeautifulSoup(html,'html.parser')
links = soup.find_all('a', href = True)
进入数据下载页面, 并解析页面,获取每一个下载链接的名称
下载每一个链接的数据
for i in range(len(links)):
file_names = links[i]['href']
if file_names.startswith('EASE2_N25km.snowice.'):
print(file_names)
browser.find_element(By.LINK_TEXT, file_names).click()
time.sleep( random.randint(1,5))
browser.close()
下载的时候设置了 随机 1-5 秒的休眠。最终完成了2846个数据的下载
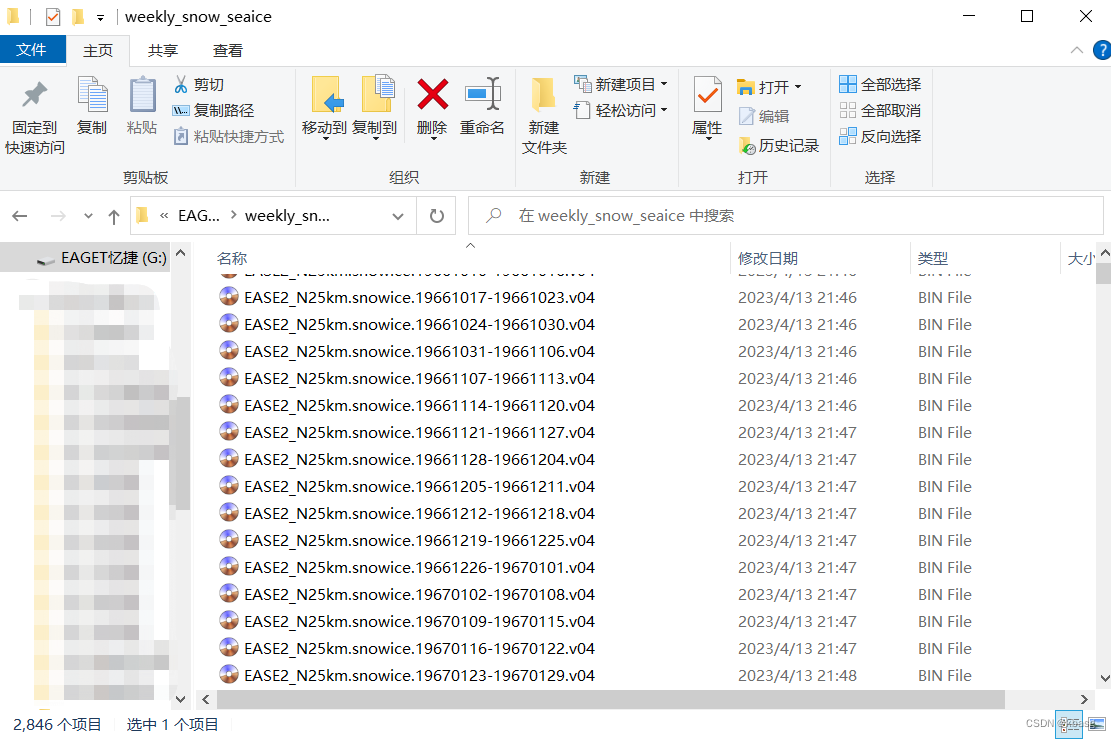
一些说明
- selenium提供了 录制浏览器操作 并转换为 python代码的插件,对不了解 python selenium包 代码的人很有用,网上可以找到很多教程。
- 以上纯属为了完成个人需求所写的代码,可能存在很多问题,可能也不能完全适合其他需求。发布在这里主要是为了记录,也希望对需要的人有点用。


















 2517
2517

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









