



一、前期准备
# 查找指定月份的原始文件
import os
import re
# 指定目录路径
directory_path = r"E:\LT111\LT_data" # 替换为你的实际路径
# 初始化计数器
september_count = 0
# 正则表达式,用于匹配连续的 8 个数字作为日期
date_pattern = re.compile(r'\d{8}') # 匹配 8 个连续的数字
# 遍历目录中的所有文件
for file_name in os.listdir(directory_path):
# 构建文件的完整路径
file_path = os.path.join(directory_path, file_name)
# 检查文件是否以 .gz 结尾
if file_name.endswith('.gz') and os.path.isfile(file_path):
# 查找文件名中所有符合日期模式的字符串
match = date_pattern.search(file_name)
if match:
date_str = match.group(0) # 获取日期字符串
# 检查日期是否为九月份
if date_str[4:6] == '09': # 获取日期中的月份部分(第 5 和第 6 个字符)
september_count += 1
# 输出结果
print(f"在目录 {directory_path} 中,共有 {september_count} 个九月份的数据文件。")
# 查找轨道数据文件
import os
import re
# 指定目录路径
directory_path = r"E:\LT111\LT_data\canshu" # 替换为你的实际路径
# 初始化计数器
september_count = 0
# 遍历目录中的所有文件
for file_name in os.listdir(directory_path):
# 构建文件的完整路径
file_path = os.path.join(directory_path, file_name)
# 检查文件是否以 .txt 结尾,且文件名包含 8 位数字
if file_name.endswith('.txt') and os.path.isfile(file_path):
# 查找文件名中的日期部分(假设日期格式是 YYYYMMDD)
date_match = re.search(r'(\d{8})', file_name) # 查找 8 位数字
if date_match:
# 提取匹配到的日期部分
date_str = date_match.group(1)
# 检查日期中的月份部分(第五和第六位)是否为 '09'(9 月份)
if date_str[4:6] == '09': # 获取日期中的月份部分
september_count += 1
# 输出结果
print(f"在目录 {directory_path} 中,共有 {september_count} 个九月份的数据文件。")
查找复制轨道文件
import os
import re
import shutil
# 指定目录路径
directory_path = r"E:\LT111\LT_data\canshu" # 替换为你的实际路径
# 目标目录路径
lt1a_dir = r"E:\LT111\202409\LuTanorbit\LT1A"
lt1b_dir = r"E:\LT111\202409\LuTanorbit\LT1B"
# 初始化计数器
september_count = 0
# 遍历目录中的所有文件
for file_name in os.listdir(directory_path):
# 构建文件的完整路径
file_path = os.path.join(directory_path, file_name)
# 检查文件是否以 .txt 结尾,且文件名包含 8 位数字
if file_name.endswith('.txt') and os.path.isfile(file_path):
# 查找文件名中的日期部分(假设日期格式是 YYYYMMDD)
date_match = re.search(r'(\d{8})', file_name) # 查找 8 位数字
if date_match:
# 提取匹配到的日期部分
date_str = date_match.group(1)
# 检查日期中的月份部分(第五和第六位)是否为 '09'(9 月份)
if date_str[4:6] == '09': # 获取日期中的月份部分
september_count += 1
# 根据文件名前缀复制文件
if file_name.startswith('LT1A'):
# 确保目标目录存在
if not os.path.exists(lt1a_dir):
os.makedirs(lt1a_dir)
# 复制文件到 LT1A 目录
shutil.copy(file_path, os.path.join(lt1a_dir, file_name))
print(f"文件 {file_name} 已复制到 {lt1a_dir}")
elif file_name.startswith('LT1B'):
# 确保目标目录存在
if not os.path.exists(lt1b_dir):
os.makedirs(lt1b_dir)
# 复制文件到 LT1B 目录
shutil.copy(file_path, os.path.join(lt1b_dir, file_name))
print(f"文件 {file_name} 已复制到 {lt1b_dir}")
# 输出结果
print(f"在目录 {directory_path} 中,共有 {september_count} 个九月份的数据文件。")
# 单个解压
import tarfile
import os
# 使用原始字符串 (raw string) 确保路径中的反斜杠不被误解析
tar_file = r"E:\LT111\202409\LT1B_MONO_KRN_STRIP1_013730_E80.2_N44.7_20240907_SLC_HH_S2A_0000502800.tar.gz"
# 获取文件所在的目录
output_dir = os.path.dirname(tar_file)
# 获取文件名(去掉扩展名 .tar.gz)
file_name = os.path.basename(tar_file).replace('.tar.gz', '') # 去掉 .tar.gz 部分
# 创建新的文件夹,文件夹名为去掉 .tar.gz 后的文件名
new_output_dir = os.path.join(output_dir, file_name)
# 如果目录不存在,则创建
if not os.path.exists(new_output_dir):
os.makedirs(new_output_dir)
# 打开 tar.gz 文件并解压到新的目录
try:
with tarfile.open(tar_file, 'r:gz') as tar:
tar.extractall(path=new_output_dir) # 解压到新的文件夹
print(f"文件已解压到: {new_output_dir}")
except FileNotFoundError:
print(f"文件未找到:{tar_file}")
except Exception as e:
print(f"发生了其他错误:{e}")
# 遍历解压
import tarfile
import os
# 文件夹路径
folder_path = r"E:\LT111\202409" # 替换为实际的文件夹路径
# 遍历文件夹中的所有 .tar.gz 文件
for tar_file in os.listdir(folder_path):
# 确保只处理 .tar.gz 文件
if tar_file.endswith('.tar.gz'):
# 获取完整的文件路径
tar_file_path = os.path.join(folder_path, tar_file)
# 获取文件所在的目录
output_dir = folder_path
# 获取文件名(去掉扩展名 .tar.gz)
file_name = os.path.basename(tar_file).replace('.tar.gz', '')
# 创建新的文件夹,文件夹名为去掉 .tar.gz 后的文件名
new_output_dir = os.path.join(output_dir, file_name)
# 如果目录不存在,则创建
if not os.path.exists(new_output_dir):
os.makedirs(new_output_dir)
# 打开 tar.gz 文件并解压到新的目录
try:
with tarfile.open(tar_file_path, 'r:gz') as tar:
tar.extractall(path=new_output_dir) # 解压到新的文件夹
print(f"文件 {tar_file} 已解压到: {new_output_dir}")
except FileNotFoundError:
print(f"文件未找到:{tar_file_path}")
except Exception as e:
print(f"解压 {tar_file} 时发生了其他错误:{e}")
二、ENVI处理处理
创建几个文件夹
Originaldata 原始解压之后的数据
workspace 生成结果的
LuTanorbit 精密轨道的
这个参考
https://www.cnblogs.com/enviidl/p/18125558
搞起
设置工作路径
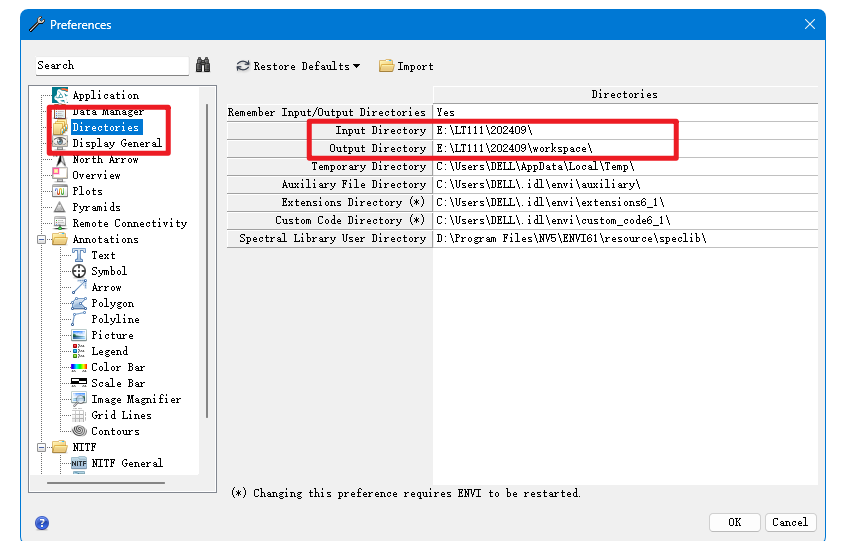
数据导入
在Toolbox 中,双击/SARscape/Preferences/Preferences common。设置LuTan orbit directory参数指定到一个目录中,并在该目录中新建2个文件夹:LT1A和LT1B。分别存放对应卫星的精密轨道文件。
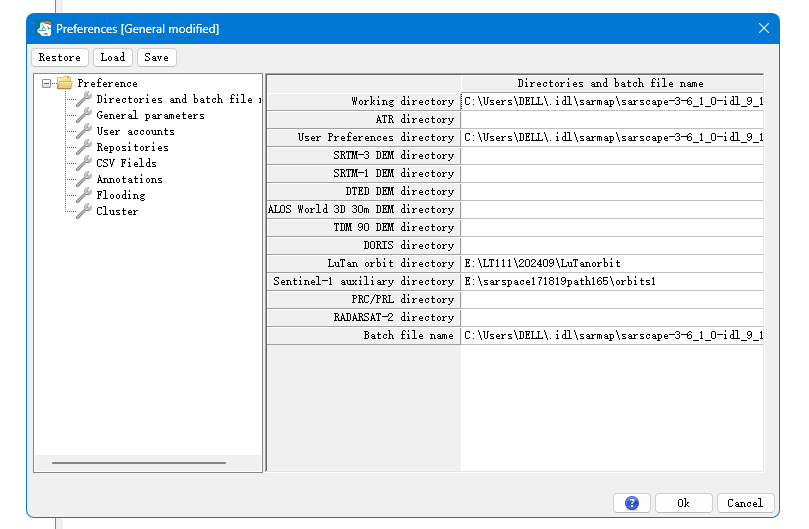
数据导入
打开Toolbox/SARscape/Preferences/Preferences specific
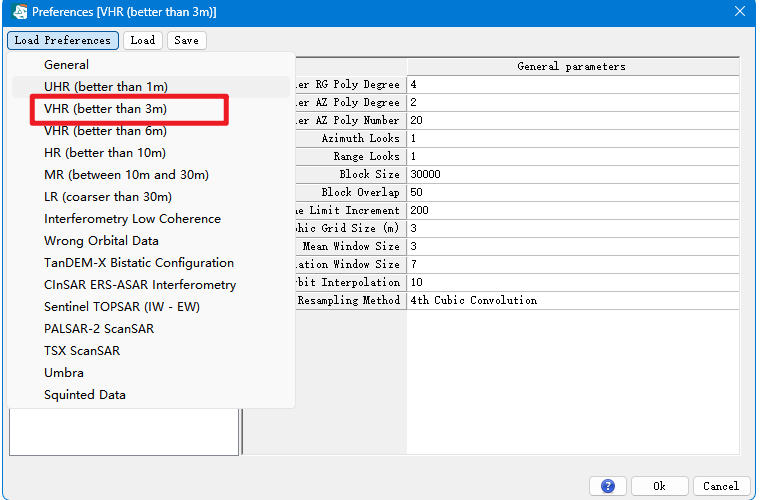
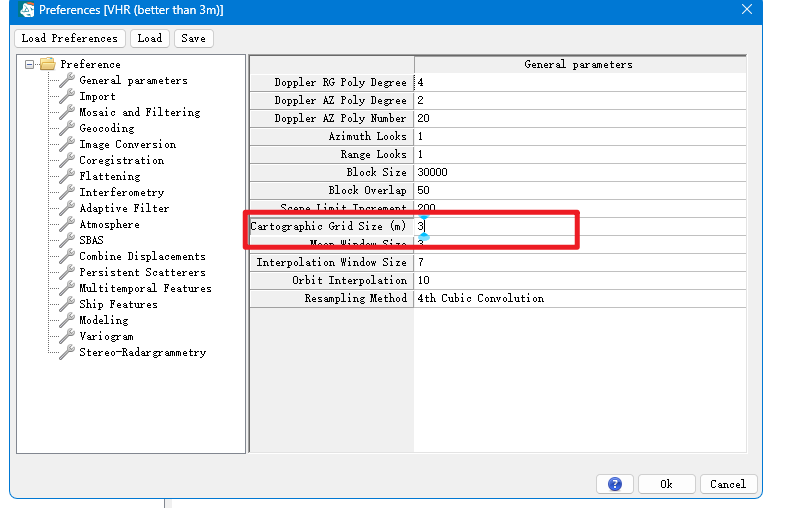
在Toolbox中,选择/SARscape/Import Data/SAR Spaceborne/Single Sensor/LuTan-1
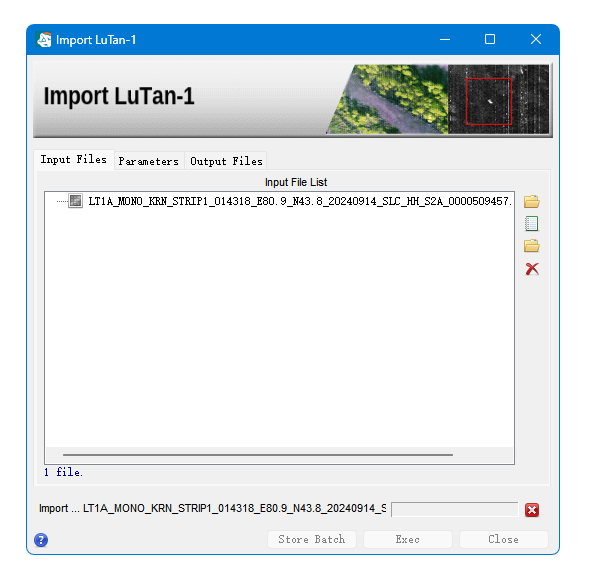
导入数据就可以了 一次性可以多加载点哈哈哈哈
在打开的面板中,
数据输入面板(Input Files)
输入文件(Input File List):输入过滤的.meta.xml文件
参数设置面板(Parameters):主要参数(Principal Parameters)
极化方式(Polarization):ALL,输出所有的极化数据,可以选择只输出同极化或者交叉极化的数据;
对数据重命名(Rename the File Using Parameters):True。软件会自动在输入文件名的基础上增加几个标识字母,如增加“_HH_slc”。
数据输出面板(Output Files)
输出文件(Output file list):自动读取ENVI默认的数据输出目录以及输入面板中的数据文件名。
注:1.如果要修改输出的路径,在右边单击文件夹图标选择输出文件夹目录。
2、如果要修改输出的路径,在输出文件名右键选择Edit菜单。
(3)单击Exec按钮开始执行。
多视处理
单视复数(SLC)SAR图像产品包含很多的斑点噪声,为了得到最高空间分辨率的SAR图像,SAR信号处理器使用完整的合成孔径和所有的信号数据。多视处理是在图像的距离向和方位向上的分辨率做了平均,目的是为了抑制SAR图像的斑点噪声。多视的图像提高了辐射分辨率,降低了空间分辨率。输出雷达强度图像。
该步骤可以不做,直接对SLC图像进行地理编码。
(1)在Toolbox中,选择/SARscape/Basic/Intensity Processing/Multilooking。
(2)在Multilooking面板中:
数据输入(Input Files)面板,单击Browse Files按钮,选择SLC数据,此处选择上一步导入得到的slc数据,根据选择的输出Grid Size=12自动算出了视数。
参数设置(Parameters)面板,主要参数(Principal Parameters)中,多视的视数和输出的制图分辨率按照默认。
数据输出(Output Files)面板,输出路径及文件名按照默认,结果自动添加_pwr后缀。
(3)单击Exec按钮执行。
滤波
从连贯SAR传感器中获取的图像都有斑点噪声,可通过空间滤波方式抑制噪声。
(1)Toolbox中,选择/SARscape/Basic/Intensity Processing/Filtering/Filtering Single Image。
(2)在Filtering Single Image面板:
数据输入(Input Files)面板,单击Browse Files按钮,选择需要滤波的雷达强度图像。
注:也可以选择地理编码后的雷达强度图像。
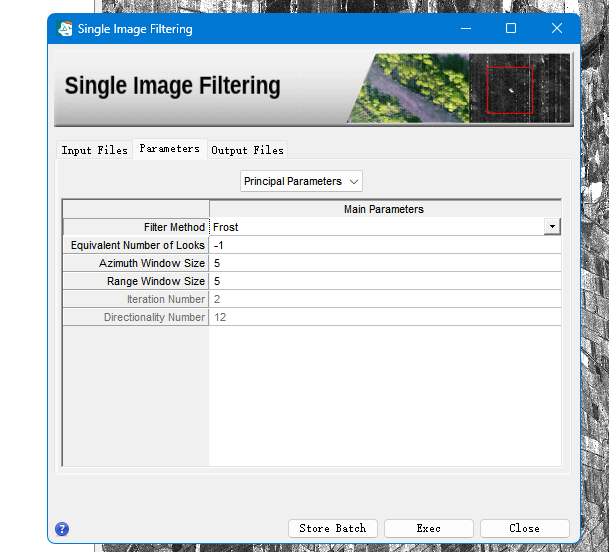
参数设置(Parameters)面板,主要参数设置(Principal Parameters)为
滤波方法(Filter Method):Frost。有8种滤波方法
方位向窗口大小(Azimuth Window Size):5
距离向窗口大小(Range Window Size):5
等值视数(Equivalent Number of Looks):-1
说明:窗口设置越大,滤波效果越平滑,需要的时间越长
数据输出(Output Files)面板,设置输出路径和文件名,默认自动添加了_fil的后缀。
(3)单击Exec执行。
陆探一号的成像质量非常不错,窗口5的滤波前后变化不大。
地理编码
拿到的例子数据中*Meta.xml中项缺少定标参数,本文档中不设置辐射定标为后向散射系数。
(1) Toolbox中,选择/SARscape/Basic/Intensity Processing/Geocoding/Geocoding and Radiometric Calibration。
(2) 打开Geocoding and Radiometric Calibration面板:
数据输入(Input Files):选择上一步得到的滤波结果。
注:也可以选择导入的SLC、多视后的PWR强度数据。
可选文件(Optional Files):Geometry GCP File和Area File这两个文件是可选项,这里不使用这两个文件。
投影参数(DEM/Cartographic System):选择Geo-GLOBAL,其他默认。
注:可以选择提前下载好的DEM数据,输出与DEM一样的投影坐标信息,几何定位精度也会提高。
参数设置(Parameters)面板,主要参数(Principal Parameters)
像元大小(X Grid Size):3
像元大小(Y Grid Size):3
辐射定标(Radiometric Calibration):False
其他默认。
output files面板,选择输出路径和文件名,默认自动添加了_geo后缀。
(3)单击Exec执行。
输出结果中,除了输出一个ENVI格式的结果文件,同时还输出一个8bit、Geotif格式的拉伸结果图像,KML格式的外接边文件。
参考教程
https://www.cnblogs.com/enviidl/p/17469219.html
https://zhuanlan.zhihu.com/p/552961084
https://www.cnblogs.com/enviidl/p/18125558
新手 勿喷


















 1744
1744

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









