







1. 环境准备
- 操作系统:Linux
- 硬件:NVIDIA GPU(用于加速训练和推理)
- 软件依赖:
- Python 3.8+(推荐使用 Python 3.10)
- PyTorch 1.12+(建议安装合适的版本以确保兼容性)
- CUDA 11.6+(用于 GPU 加速)
2. 安装依赖
pip install causal-conv1d>=1.2.0 # 可选, 跑demo可以不安装
pip install mamba-ssm
如果 pip 报告有关 PyTorch 版本的错误,可以尝试使用 --no-build-isolation 参数:
pip install causal-conv1d>=1.2.0 --no-build-isolation
pip install mamba-ssm --no-build-isolation
3. 下载预训练模型
预训练模型下载地址haggingface,以mamba-130m-hf为例。
下载后放进文件目录中(新建目录mamba-130m-hf)
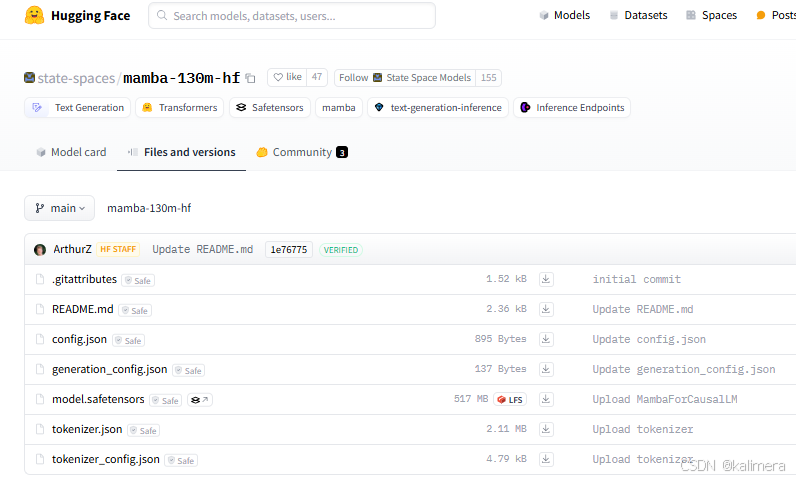
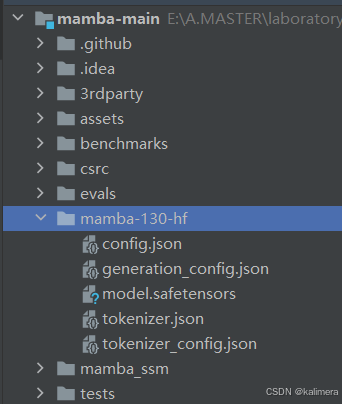
另外两个文件可以不要
3. 安装transformer库
pip install transformers>=4.39.0
4. 测试运行
编写测试demo.py
from transformers import MambaConfig, MambaForCausalLM, AutoTokenizer
import torch
path = "mamba-130-hf" # 模型位置
# 加载预训练的 tokenizer。`local_files_only=True` 表示仅从本地加载,而不尝试从 Hugging Face Hub 下载
tokenizer = AutoTokenizer.from_pretrained(path, local_files_only=True)
# 加载预训练的 Mamba 模型,`local_files_only=True` 确保模型从本地加载
model = MambaForCausalLM.from_pretrained(path, local_files_only=True)
# 使用 tokenizer 将输入文本 ("Hey how are you doing?") 转换为模型可以理解的输入格式(input_ids)
input_ids = tokenizer("Hey how are you doing?", return_tensors="pt")["input_ids"]
# 使用模型生成输出,`max_new_tokens=10` 指定生成最多 10 个新的 token
out = model.generate(input_ids, max_new_tokens=10)
# 使用 tokenizer 将生成的 token(`out`)解码成可读的文本,并打印输出
print(tokenizer.batch_decode(out))
# 输出结果
["Hey how are you doing?\n\nI'm so glad you're here."]

















 5085
5085

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









