






SparkSQL
一、 SparkSQL概述
1.1 SparkSQL是什么?


Spark SQL是Spark用于"结构化数据"(structured data)处理的Spark模块
1.2 Hive 和 SparkSQL解析
- Hive和SparkSQL之间的关系
1. Hive是SQL-on-Hadoop的工具,但由于底层还是基于MR,所以效率低。
2. 产生了大量提升SQL-on-Hadoop的工具,表现较为突出的是:
Drill
Impala
Shark
3. Shark是Spark生态环境组件之一,基于Hive开发,性能较hive提高了10-100倍。
4. 由于Shark性能提升时,有很多Hive的依赖(如hive的解析器,查询优化器等),制约了Shark的发展。
5. 2014.6.1,Shark项目终止,开始了SparkSQL项目。
6. 自此,Hive的底层引擎可以是tez、mr、Spark
- SparkSQL
1. 简化RDD,提高开发效率
2. 提供了2个编程抽象,类型spark core中的RDD:
a、DataFrame --DF
b、DataSet --DS
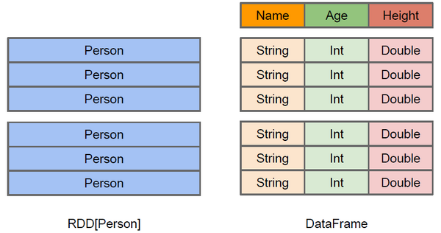
1.3 DataFrame是什么
-- DataFrame是什么
DataFrame 是一种以RDD为基础的分布式数据集,类似传统数据库中的二维表格。
-- DataFrame 与RDD的区别
1. DF带有结构(Schema)信息,即包含了二维表数据集每一列的列名和类型;
2. Hive类似,DataFrame也支持嵌套数据类型(struct、array和map)
3. 在性能上,DF的执行性能优于RDD,因为它底层会自动优化执行过程,它是如何做到的呢?利用基于关系代数的等价变换,将高成本的操作替换为低成本操作的过程,如简化shuffle阶段,先过滤再进行IO等等。
1.4 DataSet是什么
--1. DataSet是什么?
是分布式数据集合,是DataFrame的扩展,是一个强类型集合。
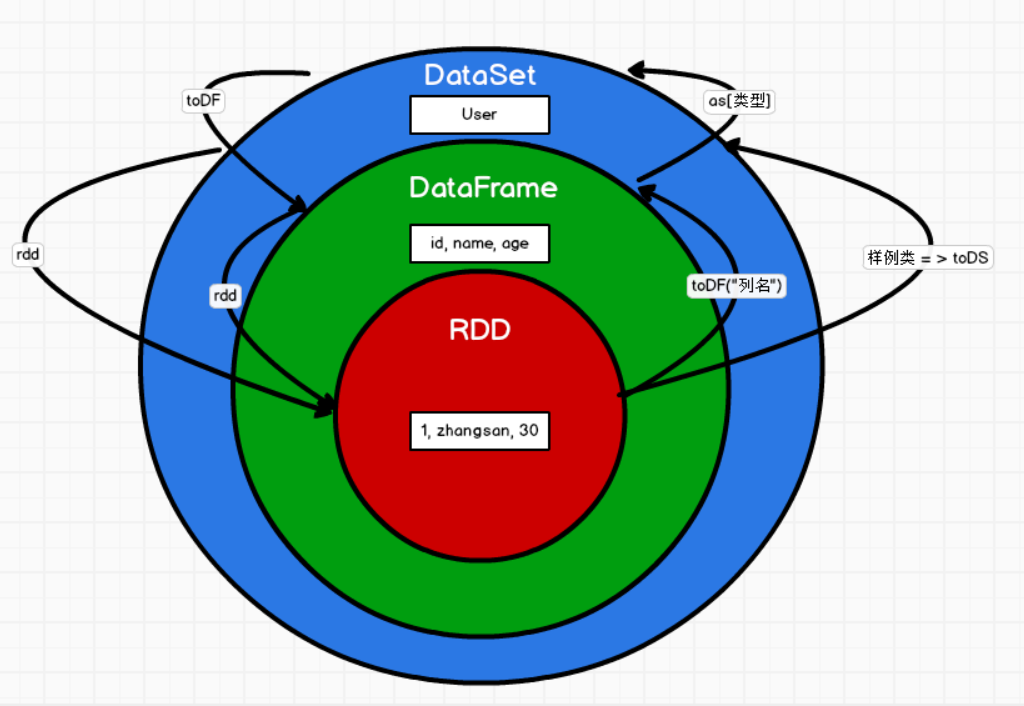
1.5 三者之间的关系
--1. 三者出现的时间顺序
Spark1.0 => RDD
Spark1.3 => DataFrame
Spark1.6 => Dataset
--2. 三者之间的关系
a、DataFrame是在RDD上进行扩展,将数据增加了结构信息
b、DataSet是在DataFrame的基础上进行扩展,增加数据的类型。
c、DataFrame是DataSet的一个特例,即为数据类型ROW的DataSet
二、 SparkSQL核心编程
2.1 SparkSQL的环境对象
--1. 上下文的环境对象
1. SparkCore --> SparkContext,使用sc来代替
2. SparkSQL --> SparkSession,使用spark代替,实际上是内部封装了SparkContext,底层实现还是SparkContext
2.2 DataFrame
2.2.1 创建DataFrame
一共有 三种方式:
- 通过Spark的数据源进行创建
- 从一个存在的RDD进行转换
- 还可以从HiveTable进行查询返回
暂时先讲第一种,就是从数据源中创建,另外两种后续章节讨论。
-- 1. 启动Spark-Local模式中的Spark
[atguigu@hadoop105 spark-local]$ bin/spark-shell
-- 2. 创建DataFrame
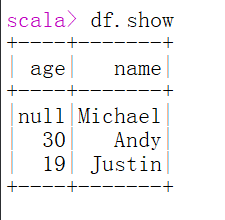
scala> val df = spark.read.json("examples/src/main/resources/people.json")
打印结果:df: org.apache.spark.sql.DataFrame = [age: bigint, name: string]
-- 3. 说明:
1. 为啥数据类型是bigint,是因为从文件中读取数据,不知道数据的长度,所用使用bigint来表示,如果是从内存创建df,那么Spark可以知道数据的具体类型。
2. spark.read.json("path:String"),从指定路径下读取json格式的文件
-- 4. 展示df的内容: show
2.2.2 SQL语法
-- SQL语法说明:
SQL语法风格是指我们查询数据的时候使用SQL语句来查询,这种风格的查询必须要有临时视图或者全局视图来辅助
-- 1. 创建临时视图和全局视图
a、 创建临时视图,
createTempView
createOrReplaceTempView :原视图存在则覆盖,不存在则创建
--案例
df.createTempView("People")
b、 创建全局视图
createGlobalTempView
createOrReplaceGlobalTempView :原视图存在则覆盖,不存在则创建
--案例
df.createGlobalTempView("People")
c、 两种视图含义上的区别:
临时视图:表示仅此次的sparkSession可以使用
全局视图:表示多次连接均可使用,可以理解为多次连接Mysql
d、 两种视图在访问上的区别:
全局视图需要加上:"global_temp."才能进行访问。
e、 view 和 table的区别:
view: 是临时结果,视图,由查询结果得到的对象,不能进行增删改,只能查询
table:是长久存在,可以进行增删改查操作。
--总结:
创建临时或者全部表,也就是视图,临时表是仅在本次连接可用,新的连接sparkSession就不能使用,但是全局表是可以跨连接使用,类似咱们的mysql,多次访问mysql的数据库,数据库中的表单都是可以访问的,同时在创建视图的时候,需要给创建的视图进行命名,如果视图名称已存在,那么会报错可以使用createorReplace,如果表存在,那么直接覆盖,如果不存在,则直接创建。
-- 2. spark.newSession : 创建新的SparkSQL的连接
-- 3. spark.sql("sql语句").show

2.2.3 DSL
-- 什么是DSL
一个特定领域的语言,用来管理结构。
-- 好处:
不用创建临时的绘图。
-- 具体的应用见API,用到的方法和展示的方式是相同的
2.2.4 SQL语法和DSL语法的区别
--1. 两个的用途是什么:均是用来查询,SQL是针对数据结构,DSL是针对数据类型
--2. 区别是什么
a、sql需要建立临时的表,而dsl不需要
b、调用sql的对象不同,使用sql使用的是sparkSession的对象,而dsl是dataframe或者是dataSet
c、语法上的差异:
sql:spark.sql(sql文)
DSL: ds/df.
2.3 DataFrame/DateSet/RDD三者之间的转换
-- 1. RDD <=> DF
a、RDD --> DF
"rdd.toDF"("列名1","列名2",...)
b、DF --> RDD
"df.rdd"
-- 2. RDD <=> DS
a、 RDD => DS
将rdd的数据转换为样例类的格式。
"rdd.toDS"
b、 DS => RDD
"ds.rdd"
-- 3. DF <=> DS
a、DF => DS
"df.as[样例类]",该样例类必须存在,而且df中的数据个样例类对应
b、 DS => DF
"ds.toDF"
-- 说明:
a、通过DF转换得来的RDD的数据类型是ROW。
b、通过DS转换得来的RDD的数据类型和DS的数据类型一致
c、RDD:只关心数据本身
DataFrame:关心数据的结构
DataSet:关心数据类型
2.4 IDEA编程
2.4.1 添加依赖
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.12</artifactId>
<version>2.4.5</version>
</dependency>
2.4.2 构建sparkSession对象
- 重要:连接SparkSQL
// 1. 创建环境
val sparkConf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("sparksql")
// 2. 创建SparkSession对象
val spark: SparkSession = SparkSession.builder().config(sparkConf).getOrCreate()
- 添加隐式转换,每次构建完对象以后都需要增加这个 隐式转换的代码
// 3. 增加隐式转换
import spark.implicits._
"1. 这里的spark不是Scala中的包名,而是创建的sparkSession对象的变量名称
2. spark对象不能使用var声明,因为Scala只支持val修饰的对象的引入"
- 说明
-- 为啥要导入隐式转换
sparkSQL是在spark的基础上进行延伸,属于功能的扩展,使用隐式转换,体现了OCP开发原则。
--构建对象为什么不直接new呢?
因为sparkSession是对sparkContext的包装,创建这个对象时,需要很多步骤,将这些过程进行封装,让开发更容易,使用一个构建器来创建对象。
2.4.3 代码实现
- 创建df
val frame: DataFrame = spark.read.json("input/people.json")
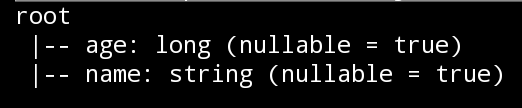
- 查看DataFrame的Schema信息
frame.printSchema()
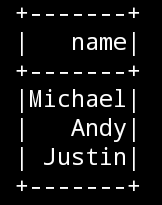
- 只查看"username"列数据
frame.select("name","age").show()
- 查看"username"列数据以及"age+1"数据
说明:
1. 涉及到运算的时候, 每列都必须"使用$, 或者采用引号表达式:单引号+字段名"
2. as 取别名
frame.select('age,'age + 1 as "newAge").show()

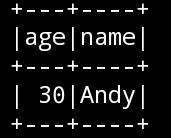
- 查看"age"大于"20"的数据
frame.filter('age > 20).show()
2.5 UDF和UDAF
-- 什么是UDF,什么是UDAF?
a、UDF : UserDefinedFunction,用户自定义函数,可以类比为map方法,给你一个数据,然后对每条数据进行处理,如取出日期中年信息
b、UDAF : UserDefinedAggregateorFunction,用户自定义"聚合"函数,可以类比sql中的count,sum、avg、max、min等方法
2.5.1 UDF
1. 创建dataFrame
2. 自定义和注册udf
方法:spark.udf.register(形参)
形参:有两个形参
形参1:自定义函数的名字
形参2:自定义函数的逻辑,是一个函数
3. 使用自定义函数:
3.1 使用自定义的udf函数用于sql语法
a、创建临时或全局视图
b、使用spark.sql(sql文)的方法调用自定的UDF方法
3.2 使用于DSL语法
a、获取注册udf的返回值
b、使用df.select(调用函数(列名)),调用自定的udf函数
- 代码实现
// 1. 创建dataFrame
val frame: DataFrame = spark.read.json("input/people.json")
/*
2. 自定义和注册udf,并获取返回值
方法:spark.udf.register(形参)
形参:有两个形参
形参1:自定义函数的名字
形参2:自定义函数的逻辑,是一个函数
*/
val udf: UserDefinedFunction = spark.udf.register("newName", (x :String) => "Name:" + x )
// 3.1、使用自定义的udf函数用于sql语法
// a、创建临时或全局视图
frame.createOrReplaceTempView("people")
// 使用spark.sql(sql文)的方法调用自定的UDF方法
spark.sql("select newName(name) from people").show()
// 3.2、使用于DSL语法
frame.select(udf('name)).show()
2.5.2 UDAF
自定义的UDAF分为两种:弱类型自定义聚合函数、强类型自定义函数
--1. 关于强类型自定义函数的说明:
将数据转换为dataset,此时二维表中的一条数据封装为一个对象因为聚合函数是强类型,那么sql中没有类型的概念,所以无法使用, 可以采用DSL语法方法进行访问将聚合函数转换为查询的列让DataSet访问
--2、强类型自定义函数和弱类型自定义的区别:
a、"使用范围区别":
弱类型自定义函数支持SQL语法和DSL语法,
而强类型语言仅支持DSL语法,因为SQL没有类型的概念
b、"声明自定义方法方式的差别":
"弱类型语言":
1)自定义函数,继承extends UserDefinedAggregatorFunction
2) 重写8个方法:
方法1:指明输入值的数据类型,不能是map类型,只能是anyval中的类型,特别注意数据的格式
override def inputSchema: StructType = ???
方法2:指明缓冲区的数据类型
override def bufferSchema: StructType = ???
方法3:指明输出值的数据类型
override def dataType: DataType = ???
方法4:数据的稳定性,设定true
override def deterministic: Boolean = ???
方法5:初始化缓冲区的值,对缓冲区
override def initialize(buffer: MutableAggregationBuffer): Unit = ???
方法6:更新缓冲区的数据,每来一条数据,将数据更新到缓冲区内
override def update(buffer: MutableAggregationBuffer, input: Row): Unit = ???
方法7:合并缓冲区中的数据,两两合并
override def merge(buffer1: MutableAggregationBuffer, buffer2: Row): Unit = ???
方法8: 计算最后的结果
override def evaluate(buffer: Row): Any = ???
"强类型语言":
1)自定义函数,继承extends Aggregator
2) 指明父类中的三个泛型
[-IN, BUF, OUT]
-IN: 指输入的数据类型,和java中 ? super IN相同,指传入的参数类型为IN类型或是IN的父类类型
BUF:指缓冲区的数据类型
OUT:指输出的数据类型
此时-IN:是指原表的一条数据,因为已经是被封装成了一个对象,所以是People
BUF:(对象的年龄,次数),(Int,Int)
OUT:(平均年龄),(Int)
3) 重写6个方法
方法1:初始化缓冲区的值
override def zero: avgAGE
方法2:将数据添加到缓冲区
override def reduce(b: avgAGE, a: People): avgAGE
方法3:合并缓冲区,两两进行合并
override def merge(b1: avgAGE, b2: avgAGE): avgAGE
方法4:计算最后的结果
override def finish(reduction: avgAGE): Long
方法5:固定写法,输入的编码器
override def bufferEncoder: Encoder[avgAGE] = Encoders.product
方法6:固定的写法,输入的解码器
override def outputEncoder: Encoder[Long] = Encoders.scalaLong
c、 "使用上的区别"
"弱语言":
使用在sql语法上:
a、创建临时视图或者全局视图
b、new 自定义方法
val uadf = new MyUADF
c、注册自定义方法
spark.udf.register(函数名,uadf)
d、使用自定义方法
spark.sql("select 函数名(输入列) from 全局表").show()
使用在DSL上:
a、new 自定义方法
val uadf = new MyUADF
b、注册自定义方法,并获取表达式的返回值
val UADF: UserDefinedAggregateFunction = spark.udf.register(函数名,uadf)
c、使用自定义方法
df.select(UADF(输入列)).show()
"强类型":只用在DSL的语法中
// 1. 创建df
val frame: DataFrame = spark.read.json("input/people.json")
// 2. 将df转换成ds
val ds: Dataset[People] = frame.as[People]
// 3. 创建自定义的UADF对象
val udaf = new MyUADF
// 4. 将对象转化为一个列
val column: TypedColumn[People, Long] = udaf.toColumn
// 5. 调用自定义函数
ds.select(column).show()
--3、如何选择强类型和弱类型自定义方法
当自定义的方法中,考虑数据作为一个对象进行传输时,需要考虑使用强类型自定义函数
- 弱类型自定聚合函数
object SparkSQL2_udaf {
def main(args: Array[String]): Unit = {
val sparkConf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("udaf")
val spark: SparkSession = SparkSession.builder().config(sparkConf).getOrCreate()
import spark.implicits._
// 创建dataframe
val rdd: RDD[User] = spark.sparkContext.makeRDD(
List(User("scala", 20), User("spark", 15), User("context", 30)))
val frame: DataFrame = rdd.toDF()
// a、注册自定义的uadf
val udaf = new MyUDAF
// b、注册自定义函数,并获取返回值。
val UADF: UserDefinedAggregateFunction = spark.udf.register("myUADF",udaf)
// 方式1:使用与mysql语法
spark.sql("select myUADF(age) from User").show()
// 方式2: 使用与DSL语法
frame.select(UADF('age)).show()
}
// 1. 需求:求年龄的平均值
class MyUDAF extends UserDefinedAggregateFunction{
// 方法1:输入数据的类型,将年龄一个一个给传进来
override def inputSchema: StructType = {
StructType(Array(StructField("age",IntegerType)))
}
// 方法2:缓冲区的数据类型,数据的类型,需要记录年龄的总和,次数,可以存放到一个map集合中
// 关于数据的格式有:LongType
override def bufferSchema: StructType = {
StructType(Array(
StructField("totalAge",IntegerType),
StructField("count",IntegerType)))
}
// 方法3:结果数据的数据类型,返回值的数据类型
override def dataType: DataType = IntegerType
// 方法4:数据是否安全
override def deterministic: Boolean = true
// 方法5:缓冲区初始化,就是给缓冲区的每个值设定一个初始值
override def initialize(buffer: MutableAggregationBuffer): Unit = {
buffer(0)=0
buffer(1)=0
}
// 方法6:更新缓冲区
override def update(buffer: MutableAggregationBuffer, input: Row): Unit = {
buffer(0) = buffer.getInt(0) + input.getInt(0)
buffer(1) = buffer.getInt(1) + 1
}
// 方法7:因为是多executor执行,合并所有分区的数据
override def merge(buffer1: MutableAggregationBuffer, buffer2: Row): Unit = {
buffer1(0) = buffer1.getInt(0) + buffer2.getInt(0)
buffer1(1) = buffer1.getInt(1) + buffer2.getInt(1)
}
// 方法8:计算最后的结果
override def evaluate(buffer: Row): Any = {
buffer.getInt(0) / buffer.getInt(1)
}
}
case class User (name:String,age :Int)
}
- 解析:
buffer(0) = buffer.getInt(0) + input.getInt(0)
buffer(0): 理解为设置索引位置为0的值
buffer.getInt(0) :获取索引为0位置的数据
- 强类型自定义的函数
object SparkSQL5_UADF {
def main(args: Array[String]): Unit = {
val sparkConf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("UADF")
val spark: SparkSession = SparkSession.builder().config(sparkConf).getOrCreate()
import spark.implicits._
// 1. 创建df
val frame: DataFrame = spark.read.json("input/people.json")
// 2. 将df转换成ds
val ds: Dataset[People] = frame.as[People]
// 3. 创建自定义的UADF对象
val udaf = new MyUADF
// 4. 将对象转化为一个列
val column: TypedColumn[People, Long] = udaf.toColumn
// 5. 调用自定义函数
ds.select(column).show()
}
/*
需求:统计平均年龄
1. 自定义类,继承与extends Aggregator
2. 指定Aggregator的泛型,分别是:
[-IN, BUF, OUT]
-IN: 指输入的数据类型,和java中 ? super IN相同,指传入的参数类型为IN类型或是IN的父类类型
BUF:指缓冲区的数据类型
OUT:指输出的数据类型
此时-IN:是指原表的一条数据,因为已经是被封装成了一个对象,所以是People
BUF:(对象的年龄,次数),(Int,Int)
OUT:(平均年龄),(Int)
*/
case class People(var name:String, var age : Long)
case class avgAGE (var sumAge: Long,var count:Long)
class MyUADF extends Aggregator[People,avgAGE,Long]{
// 方法1:初始化缓冲区的值
override def zero: avgAGE = {
avgAGE(0L,0L)
}
// 方法2:将数据添加到缓冲区
override def reduce(b: avgAGE, a: People): avgAGE = {
b.sumAge += a.age
b.count += 1
b
}
// 方法3:合并缓冲区,两两进行合并
override def merge(b1: avgAGE, b2: avgAGE): avgAGE = {
b1.count = b1.count + b2.count
b1.sumAge =b1.sumAge + b2.sumAge
b1
}
// 方法4:计算最后的结果
override def finish(reduction: avgAGE): Long = {
reduction.sumAge / reduction.count
}
// 方法5:固定写法,输入的编码器
override def bufferEncoder: Encoder[avgAGE] = Encoders.product
// 方法6:固定的写法,输入的解码器
override def outputEncoder: Encoder[Long] = Encoders.scalaLong
}
}
2.6 数据的加载和保存
数据加载和保存的方式有很多种方式,根据不同的需求,主要有以下几种:
--方式1:通用的数据加载和保存方式
--方式2:parquet
--方式3:JSON
--方式4:CSV
--方式5:Mysql
--方式6:Hive
2.6.1 通用的数据加载和保存方式
--什么是通用的方式?
指使用相同的API,根据不同的参数,读取和保存不同格式的数据。
-- 说明:
SparkSQL默认读取和保存的文件格式是parquet。
2.6.1.1 读取数据
--1. 通用的数据加载方式[默认为parquet格式]
方式:spark.read.load(pat:String)
--2. 读取不同格式的数据,可以对不同的数据格式进行设定
方式:spark.read.format("数据格式":string).load(path:String)
说明:
a、format("数据格式":string):数据格式可以是:"csv"、"mysql"、"json"、"jdbc"、"textFile"、"orc"
b、数据的路径
--3. 还可以加option,导入一些参数
方式:spark.read.format("…")[.option("…")].load("…")
在"jdbc"格式下需要传入JDBC相应参数,url、user、password和dbtable
我们前面都是使用read API 先把文件加载到 DataFrame然后再查询,其实,我们也可以直接在文件上进行查询: "文件格式.`文件路径`"
// 情况1:直接load
spark.read.load("input/users.parquet").show()
// 情况2:指定文件格式
spark.read.format("json").load("input/people.json").show()
// 情况3:使用文件格式.`文件路径`方式
spark.sql("select * from json.`input/people.json`").show()
-- 因为在实际生产情况下,json文件的数据格式的场景是非常多的,Spark对于json文件格式要求如下:
1. JSON文件的格式要求整个文件满足JSON的语法规则
2. Spark读取文件默认是以行为单位进行读取
3. Spark读取JSON文件时,要求文件中的每一行满足JSON格式
4. 如果文件格式不正确,那么不会发生错误,而是解析结果不是我们预期的结果。
2.6.1.2 保存数据
1. 保存的方法:
spark.write.save(path:String)
2. 默认的保存格式为parquet格式
3. 如果想要指定保存的格式,增加format方法,在format的方法中指定形参数据保存的格式
frame.write.format("json")save("output")
4. 如果保存的路径已经存在,那么会报错:output already exists
5. 如果文件路径已经存在时不能创建,那么在实际的生产的情况下,岂不是会生成很多小文件?
解决方案:使用mode,指定模式
方法:mode(形参)
形参:saveMode: SaveMode,数据类型是一个枚举类
枚举类的对象有:
a、Append:追加,如果原文件目录或表存在,那么在原路径下进行生产一个新的文件
b、Overwrite:重写,如果原文件目录或表存在,那么将原路径下的文件进行直接覆盖
c、ErrorIfExists:默认值,如果原文件目录存在,则报错
d、Ignore:如果原文件目录或表存在,那么不报错,但是也不保存数据
frame.write.mode("Overwrite").format("json").save("output")
2.6.2 CSV
//读取文件
val frame: DataFrame = spark.read.format("csv")
.option("sep", ";")
.option("inferSchema", "true")
.option("header", "true")
.load("input/people.csv")
frame.show()
// 保存数据
frame.write.mode("Append").format("json").save("output")
2.6.3 MySQL
- 方式1:使用option的方式进行参数配置
//从MYsql中读取数据
val frame: DataFrame = spark.read.format("jdbc")
.option("url", "jdbc:mysql://hadoop105:3306/mysql")
.option("driver", "com.mysql.jdbc.Driver")
.option("user", "root")
.option("password", "123456")
.option("dbtable", "db")
.load()
// 保存到数据库中
frame.write.format("jdbc")
.option("url", "jdbc:mysql://hadoop105:3306/mysql")
.option("driver", "com.mysql.jdbc.Driver")
.option("user", "root")
.option("password", "123456")
.option("dbtable", "db1")
.mode("Append").save()
- 方式2:使用jdbc的方法
// 创建连接
val props: Properties = new Properties()
props.setProperty("user", "root")
props.setProperty("password", "123456")
val df: DataFrame = spark.read
.jdbc("jdbc:mysql://hadoop105:3306/mysql", "db", props)
df.show()
// 将数据保存到Mysql中
val rdd: RDD[Int] = spark.sparkContext.makeRDD(List(1,2,3,6))
val frame: DataFrame = rdd.toDF("id")
frame.write.mode("Append").jdbc("jdbc:mysql://hadoop105:3306/mysql", "db2", props)
2.6.4 Hive
1. Spark中内嵌了hive。
val sparkConf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("Hive")
val spark: SparkSession = SparkSession
.builder()
.enableHiveSupport() // 支持hive
.config(sparkConf)
.getOrCreate()
// 创建表
// spark.sql("create table aa (id int)")
// 查询表
// spark.sql("show tables").show()
spark.sql("load data local inpath 'input/id.text' into table aa")
spark.sql("select * from aa ").show()
2. 外置Hive
步骤:
a、导入依赖
b、将hive
c、取消tez引擎
d、代码实现,访问hive中的表
- 导入依赖
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_2.12</artifactId>
<version>2.4.5</version>
</dependency>
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-exec</artifactId>
<version>3.1.2</version>
</dependency>
- 将hive-site.xml文件拷贝到项目的resources目录中,代码实现
val sparkConf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("hive")
val spark: SparkSession = SparkSession.builder().enableHiveSupport().config(sparkConf).getOrCreate()
spark.sql("show databases").show()
spark.stop()
三、项目实战
3.1 数据准备
-- 我们这次 Spark-sql 操作中所有的数据均来自 Hive,首先在 Hive 中创建表,,并导入数据。一共有3张表: 1张用户行为表,1张城市表,1 张产品表
//修改hadoop的用户
System.setProperty("HADOOP_USER_NAME", "atguigu")
val sparkConf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("pro")
val spark: SparkSession = SparkSession.builder().enableHiveSupport().config(sparkConf).getOrCreate()
spark.sql("use spark_sql")
spark.sql("show databases").show()
spark.sql(
"""
|CREATE TABLE `user_visit_action`(
| `date` string,
| `user_id` bigint,
| `session_id` string,
| `page_id` bigint,
| `action_time` string,
| `search_keyword` string,
| `click_category_id` bigint,
| `click_product_id` bigint,
| `order_category_ids` string,
| `order_product_ids` string,
| `pay_category_ids` string,
| `pay_product_ids` string,
| `city_id` bigint)
|row format delimited fields terminated by '\t'
""".stripMargin)
spark.sql("load data local inpath 'input/user_visit_action.txt' into table user_visit_action")
spark.sql(
"""
|CREATE TABLE `product_info`(
| `product_id` bigint,
| `product_name` string,
| `extend_info` string)
|row format delimited fields terminated by '\t'
""".stripMargin)
spark.sql("load data local inpath 'input/product_info.txt' into table product_info")
spark.sql(
"""
|CREATE TABLE `city_info`(
| `city_id` bigint,
| `city_name` string,
| `area` string)
|row format delimited fields terminated by '\t'
""".stripMargin)
spark.sql("load data local inpath 'input/city_info.txt' into table city_info")
spark.stop()
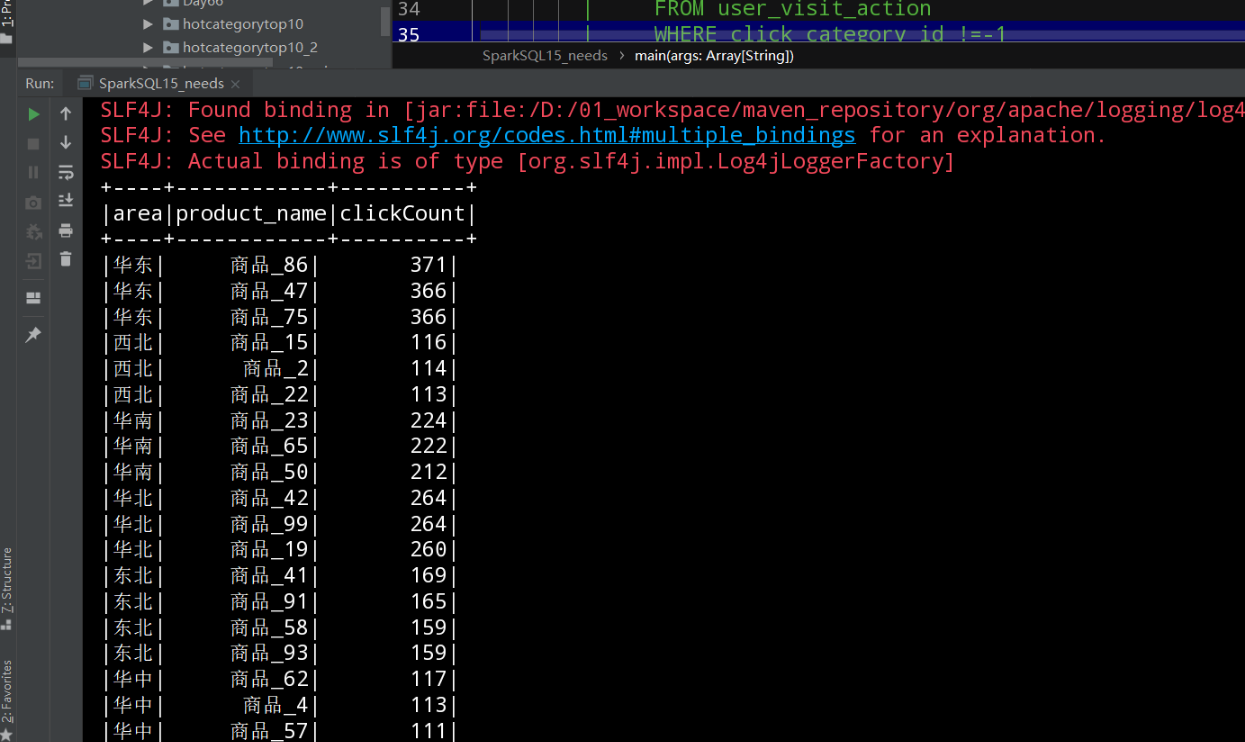
3.2 需求 : 各区域热门商品 Top3
3.2.1 需求
--这里的热门商品是从点击量的维度来看的,计算各个区域前三大热门商品,并备注上每个商品在主要城市中的分布比例,超过两个城市用其他显示
| *地区* | *商品名称* | *点击次数* | *城市备注* |
|---|---|---|---|
| *华北* | 商品A | 100000 | 北京21.2%,天津13.2%,其他65.6% |
| *华北* | 商品P | 80200 | 北京63.0%,太原10%,其他27.0% |
| *华北* | 商品M | 40000 | 北京63.0%,太原10%,其他27.0% |
| *东北* | 商品J | 92000 | 大连28%,辽宁17.0%,其他 55.0% |
3.2.2 需求分析
SELECT t4.area,t4.product_name,t4.clickCount
FROM (
SELECT t3.area,t3.product_name,t3.clickCount,
RANK() over(partition by t3.area order by clickCount DESC ) as click_rank
FROM (
SELECT t2.area,t2.product_name,count(*) as clickCount
FROM (
SELECT t1.city_id,pro.product_name ,city.city_name ,city.area
FROM (
select *
FROM user_visit_action
WHERE click_category_id !=-1
)t1 join product_info pro
on pro.product_id = t1.click_product_id
join city_info city
on t1.city_id = city.city_id
)t2
group by t2.area,t2.product_name
)t3
)t4
WHERE t4.click_rank <= 3
- 补充备注信息


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









