




 本文详细介绍了LightGBM的数据压缩策略,包括连续变量分箱、互斥特征捆绑(EFB)和基于梯度的单边采样(GOSS)。通过等宽分箱和EFB算法实现数据降维,而GOSS则用于样本下采样,以提高计算效率。LightGBM的决策树优化包括直方图优化算法和leaf wise tree growth策略,有效提升模型训练速度和精度。
本文详细介绍了LightGBM的数据压缩策略,包括连续变量分箱、互斥特征捆绑(EFB)和基于梯度的单边采样(GOSS)。通过等宽分箱和EFB算法实现数据降维,而GOSS则用于样本下采样,以提高计算效率。LightGBM的决策树优化包括直方图优化算法和leaf wise tree growth策略,有效提升模型训练速度和精度。
目录
2、leaf wise tree growth叶子节点优先生长决策
2、互斥特征捆绑(Exclusive Feature Bunding,EFB)
3、基于梯度的单边采样 (Grandient-based One-Side Sampling ,GOSS )
LightGBM的数据压缩策略介绍
LightGBM的数据压缩策略LightGBM建模过程总共会进行三方面的数据压缩,根据实际建模顺序,会现在全样本上连续变量分箱(连续变量离散化),然后同时带入离散特征和离散后的连续变量进行离散特征捆绑(合并)降维,最终在每次构建一颗树之前进行样本下采样。其中连续变量的分箱就是非常简单的等宽分箱,并且具体箱体的数量可以通过超参数进行人工调节;而离散特征的降维,则是采用了一种所谓的互斥特征捆绑(Exclusive Feature Bundling, EFB)算法,该算法也是由LGBM首次提出,该方法的灵感来源于独热编码的逆向过程,通过把互斥的特征捆绑到一起来实现降维,这种方法能够很好的克服传统降维方法带来的信息大量损耗的问题,并且需要注意的是,输入EFB进行降维的特征,即包括原始离散特征,也包括第一阶段连续变量离散化之后的特征;在这一系列数据压缩之后,LGBM在每次迭代(也就是每次训练一颗决策树模型)的时候,还会围绕训练数据集进行下采样,此时的下采样不是简单的随机抽样,而是一种名为基于梯度的单边采样(Gradient-based One-Side Sampling, GOSs)的方法,和EFB类似,这种方法能够大幅压缩数据,但同时又不会导致信息的大量损失。不难发现,最终输入到每颗决策树进行训练的数据,实际上是经过大幅压缩后的数据,这也是LGBM计算高效的根本原因之一。
LightGBM决策树建模优化方法
1、直方图优化算法
高效表示分裂前后的节点的核心数据,且父子节点可以通过直方图减法直接计算,从而加速数据集分裂的计算过程: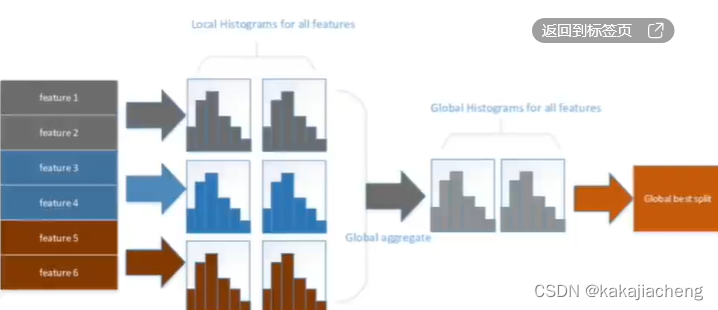
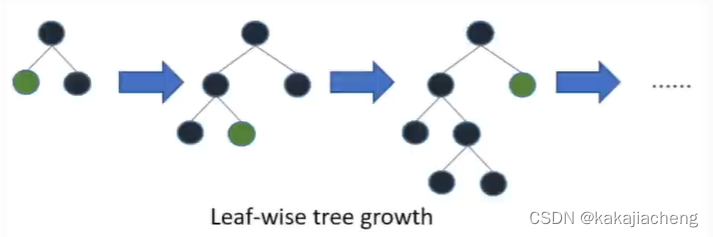
2、leaf wise tree growth叶子节点优先生长决策
XGboost是一次生长一层也就是Level-wise tree growth,生长过程如下: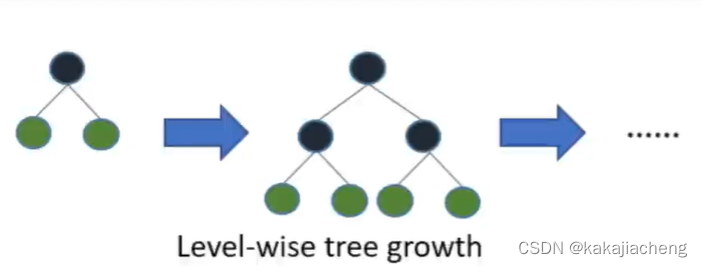
但是针对叶子节点优先分裂,可以理解为深度优先的“有偏”决策 生长。
优点:大幅提升每颗树的收敛速度,提升迭代速率。
劣势:每棵树计算更加复杂,且数据压缩后易出现过拟合的,但是可以通过设置树的深度来优化。
1、连续变量分箱
1.1 等宽分箱
lightGBM连续变量分箱实现简单的等宽分箱,通过设置max_bin值来确定分箱数,例如连续变量取值范围是[0,10],设置max_bin=2,则bin0=[0,5]和bin1=[5,10],XGboost是通过分位数分箱,不是等宽分箱。
1.2 手动示例
import pandas as pd
import numpy as np
from sklearn.preprocessing import KBinsDiscretizer
# 创建数据集
data = {
'x1': [1.2, 3.0, 2.6, 3.3, 2.2, 2.5, 1.3, 2.0, 1.9, 2.9],
'x2': [4.6, 5.4, 3.8, 6.1, 3.4, 4.4, 5.0, 2.6, 4.0, 3.7],
'x3': [1, 1, 0, 1, 1, 1, 1, 0, 1, 1],
'x4': [0, 0, 1, 0, 0, 1, 0, 1, 0, 1],
'y': [1, 0, 1, 0, 1, 1, 0, 0, 1, 1]
}
df = pd.DataFrame(data)
# 提取连续变量列
continuous_cols = ['x1', 'x2']
# 定义等宽分箱器
max_bin = 3
kbins = KBinsDiscretizer(n_bins=max_bin, encode='ordinal', strategy='uniform')
# 对连续变量进行分箱
binned_cols = ['x1_binned', 'x2_binned']
df_binned = pd.DataFrame(kbins.fit_transform(df[continuous_cols]), columns=binned_cols)
# 将分箱结果合并到原数据集
df_final = pd.concat([df, df_binned], axis=1)
print(df_final)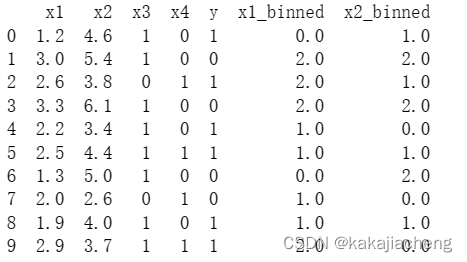
如示例所示的等宽分箱区间划分实际情况,如x1值域区间[1.2,3.3]若设置max_bin=3,则分箱深度为(3.3-1.2)/3=0.7,分箱区间则为{ [1.2,1.9) , [1.9,2.6) , [2.6,3.3] }。binned值为{ 0 , 1 , 2 }。至此,第一阶段对数据的连续变量采用的分箱处理完成。
2、互斥特征捆绑(Exclusive Feature Bunding,EFB)
离散特征降维,LGBM采用互斥特征捆绑的降维方法,本节研究背景、原理、及示例代码。
2.1 EFB算法提出背景
根据论文《A Highly Efficient Gradient Boosting Decision Tree (2017) 》中说明,原始GBDT树训练时,需要使用到全量的数据计算信息增益,从而找到决策树节点最佳分支节点,但缺点是耗费算力和时间,在传统基础上提出的欠采样会使得模型训练不稳定和PCA降维会由冗余信息导致信息丢失。因此,LightGBM日出单边采样的GOSS对样本数量进行压缩,EFB来进行特征捆绑,这两者的结合能够同时兼顾精度和效率。后续还提出了直方图的数据压缩优化。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 9766
9766




 到【灌水乐园】发言
到【灌水乐园】发言







