






 Kafka 2.2之前,Controller请求与数据请求混在一起,可能导致管理类请求处理延迟。2.2版本开始,Controller请求与数据请求分开处理,提高效率。0.11版本引入异步Zookeeper API,提升写入性能。建议高负载环境下,将Controller与Zookeeper部署在同一机器上,避免Zookeeper压力过大。
Kafka 2.2之前,Controller请求与数据请求混在一起,可能导致管理类请求处理延迟。2.2版本开始,Controller请求与数据请求分开处理,提高效率。0.11版本引入异步Zookeeper API,提升写入性能。建议高负载环境下,将Controller与Zookeeper部署在同一机器上,避免Zookeeper压力过大。
Controller在版本上的改进
(一)在Kafka2.2之前
网络处理模型:Kafka Server在启动时会初始化SocketServer、KafkaApis和KafkaRequestHandlerPool对象,这也是Server网络处理模型的主要组成部分。Kafka Server的网络处理模型也是基于Java NIO机制实现的,实现模式与Reactor模式类似。
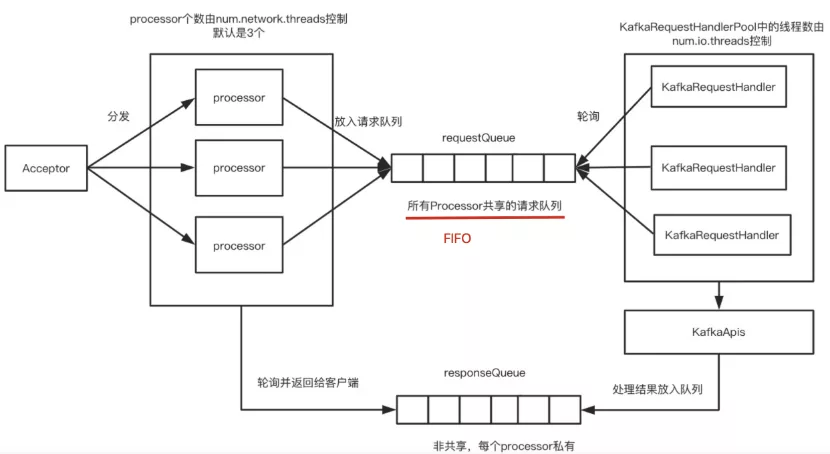
如上图,所有请求共享一个requestQueue队列。
问题:当前Broker对入站请求类型不做任何优先级处理。
不论是PRODUCE请求、FETCH请求还是Controller类的请求。对Controller发送的消息非常不公平,因为这个类请求应该优先级更高。
这就可能造成一个问题:即clients发送的数据类请求积压导致controller推迟了管理类请求的处理。设想这样的场景。假设controller向broker广播了leader发生变更。于是新leader开始接收clients端请求,而同时老leader所在的broker由于出现了数据类请求的积压使得它一直忙于处理这些请求而无法处理controller发来的LeaderAndIsrRequest请求,因此这是就会出现“双主”的情况——也就是所谓的脑裂。
(二)在Kafka 2.2
将控制器发送的请求与普通数据类请求分开处理,源码SocketServer.scala#startup()->KafkaServer.scala。
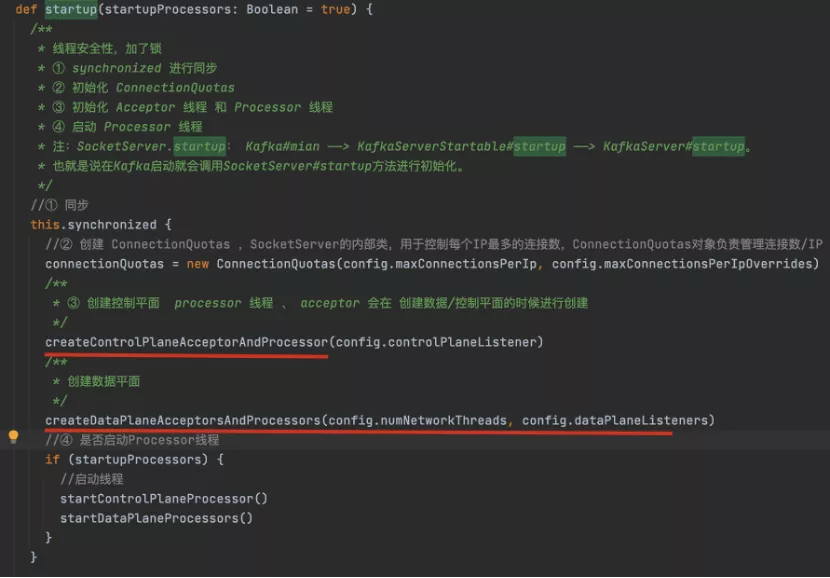
在0.11版本上也做了大的改进,具体如下。
关于Controller的架构改进
Kafka中的一台Broker充当Controller的角色,此台Broker不仅对生产者消费者提供服务,还要协调整个集群的管理工作。如果使用0.11版本之前的Kafka而且分区很多时,建议将几台机器配置为只能成为Controller(当然这里需要修改源码,编译)。
(一)0.11版本之前
同步操作Zookeeper使用同步的API,性能差。当Broker宕机,大量主题分区发生变更时,自动恢复时间长。Controller是一个分区一个分区进行写入的,对于分区数很多的集群来说,这无疑是个巨大的性能瓶颈。
(二)0.11 版本
异步操作Zookeeper使用async API,写入提升了10倍。
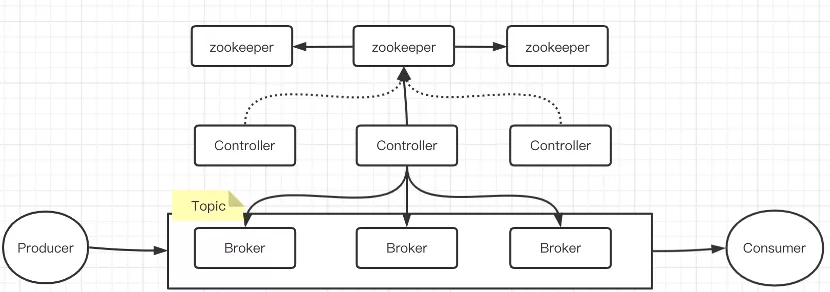
如果机器性能较好,可以将Zookeeper和Controller部署在相同的机器。Kafka对Zookeeper写请求比较少。
注意:消费方式有基于Zookeeper消费和基于Broker消息。基于Zookeeper消费,就是将消费位移提交到Zookeeper上,这种方式对Zookeeper有大量写操作。不要将Zookeeper和其他机器共用。
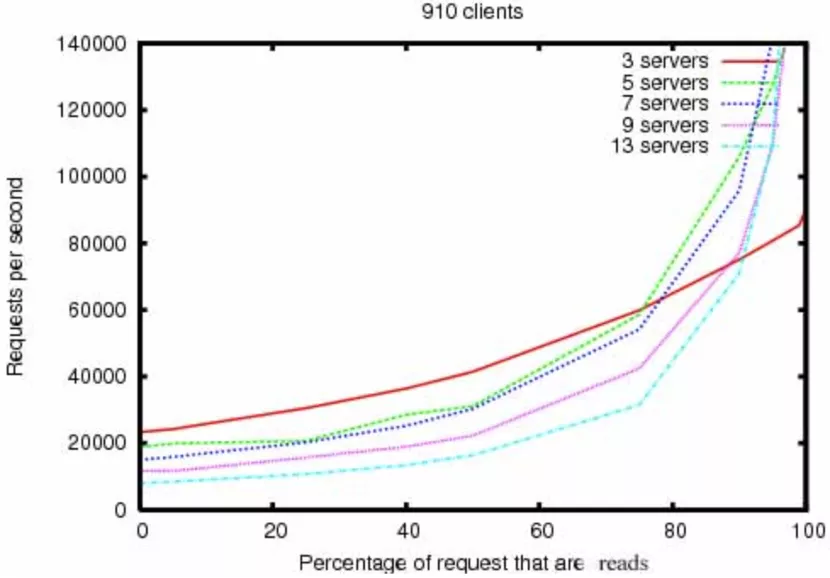
Zookeeper官网上有对读写占比的压测说明:
国内最大最权威的 Kafka中文社区 ,在这里你可以结交各大互联网Kafka大佬以及近2000+Kafka爱好者,一起实现知识共享,实时掌控最新行业资讯,免费加入中~



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









