




 本文详细介绍了JVM中的锁机制,从自旋锁到重量级锁的膨胀过程。当轻量级锁加锁失败,经过自旋锁尝试后,会升级为重量级锁,利用mutexlock实现互斥。此外,还提到了锁消除技术,通过逃逸分析来优化性能,减少不必要的同步操作。
本文详细介绍了JVM中的锁机制,从自旋锁到重量级锁的膨胀过程。当轻量级锁加锁失败,经过自旋锁尝试后,会升级为重量级锁,利用mutexlock实现互斥。此外,还提到了锁消除技术,通过逃逸分析来优化性能,减少不必要的同步操作。
目录
接着上一篇,偏向锁失效后JVM让线程去申请轻量级锁,轻量级锁就是一种乐观思想,举个例子,在写入数据时会先判断这个期间有没有其他线程修改过这个数据,具体方式是读出版本号or时间戳,如果没有,就可以加锁,进行写入修改,否则继续重复读出数据,比较,再写入,轻量级锁就是这么个思想,使用的也是CAS操作。如果轻量级锁获取失败,证明有多个线程在同时竞争这个对象,这时候临界区线程竞争激烈,如果想要保证数据完整性,就要采用更重量级别的锁,从偏向锁到轻量级锁,再到后面的重量级锁锁,都是一个锁膨胀过程。
锁膨胀
锁膨胀过程我打算还是回到偏向锁开始,当一个线程成功进入临界区访问资源时,会在自己的Java对象头中Mark Word中记录线程的id,让锁处于偏向状态,偏向该线程,这样当下一次有线程试图获取锁时,JVM先检查对象头中Mark Word里是否存有该线程的id,如果有,则直接进入,不需要任何同步操作。如果Mark Word中没有该线程的id,那么就要分两种情况判断,如果偏向锁标志位还是为1,证明偏向锁仍然有效,并没有多个线程同时竞争,只是当前访问临界区的线程不是之前偏向的线程,这时只要用一次CAS操作将对象头Mark Word中线程id指向当前请求的线程计科。如果偏向锁标志位为0,说明偏向锁已经失效,有多个线程进行了竞争,锁已经膨胀为轻量级锁。轻量级锁加锁时通过CAS操作尝试修改Java对象头,首先在Mark Word中保存当前线程的指针,然后将lock标志位修改为00;解锁则将biased_lock标志位设置为0,lock标志位设置为01,如果加锁或设置无锁状态时CAS操作失败,具体体现在线程进行CAS操作时,期待的值不是原本的Mark Word,而是一个指针,如果该指针指向当前线程,则说明这个线程已经获得了该锁,否则表明发生了竞争,锁膨胀为重量级锁。
自旋锁
不过,在膨胀为重量级锁前,JVM还会做一些挣扎,因为线程阻塞后再被唤醒对性能消耗还是挺大的,为了减少大量线程频繁上下文切换的情况,在线程锁膨胀前,会做几轮空循环,看看能不能尽快进入临界区,如果做了几轮空循环(也就是自旋)后,线程能够成功获得锁,那么线程就可以继续执行,否则几轮自旋操作后还没能获得锁,线程就真的被挂起了。通常自旋的次数为10次,
自旋锁的目的是希望线程能尽快获得锁,减少程序中线程阻塞的次数,但是否能优化性能是要分场景的,对于多线程占用锁时长很短的场景下,一个线程自旋后能够获得锁的几率很大,的确能大大减少线程被挂起的次数,让整个程序执行的更加连贯。但是,如果在多线程需要对数据进行长时间操作的场进下,因为线程占用锁的时间较长,即使其他线程进行自旋等待,也可能无法获得锁,这样就会浪费占用的CPU,最后还是要被挂起。
重量级锁
当线程尝试多次申请轻量级锁失败,且自旋也未能获得锁后,就会膨胀成为重量级锁,重量级锁就是用mutexlock来实现的互斥锁,是一种悲观锁,即悲观地认为每次操作数据时都会被其他线程修改,以防万一就都先上锁,这样别的线程试图访问这一临界区资源时就会阻塞,直到获得锁。锁升级为重量级锁把Mark Word中的lock标志位设置为10,biased_lock标志位为0,JVM检查到锁是重量级锁后,会把线程阻塞,等其他线程释放锁后,再唤醒阻塞的线程。
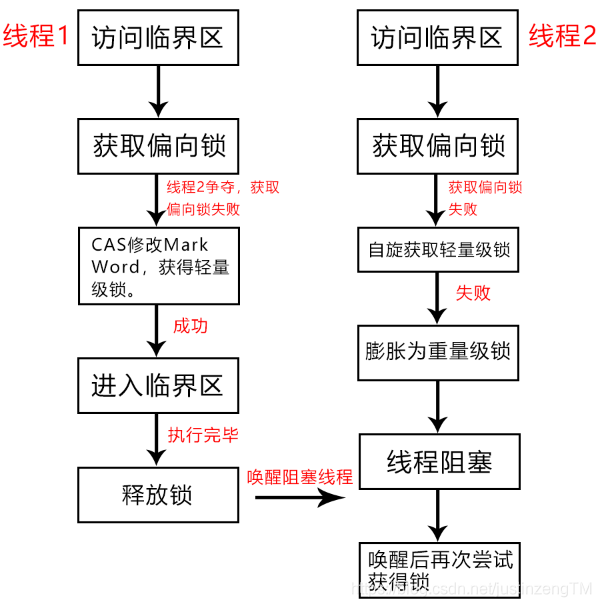
总的来说从偏向锁膨胀到重量级锁的过程如上图所示。
锁消除
我们知道Java程序是一边执行一边编译的,在JVM即时编译过程中会去扫描这些代码,做逃逸分析,看看那些对象是线程安全的,那么对于这些对象的访问就不用做同步操作,减少锁带来的性能损失。逃逸分析具体有对线程的逃逸分析和对方法的逃逸分析,拿方法逃逸举例,JVM检测某个对象在方法中被定义之后,会不会作为参数被外部方法引用,如果不会,表示该对象是线程安全的,那对象不会逃逸到方法之外,那么对该变量的访问就可以不做同步操作。事实上JVM就是这么做,在程序中对于一些不存在竞争的代码段,减少同步操作可以提升执行速度,用逃逸分析来得出那些不存在竞争的代码段,然后消除一些锁操作。逃逸分析可以用参数-XX:+EscapeAnalysis来开启,然后参数-XX:+EliminateLocks来开启锁消除,来看一个例子:
public class EliminateLockDemo {
public static void main(String[] args) {
StringBuffer buffer = new StringBuffer();
String s1, s2;
long startTime = System.currentTimeMillis();
for(int i=0; i<100000; i++) {
s1 = "dali";
s2 = "haitang";
buffer.append(s1);
buffer.append(s2);
buffer.toString();
}
long endTime = System.currentTimeMillis();
System.out.println("耗时: " + (endTime-startTime) + "ms");
}
}
程序很简单,就是不停地拼接字符串,因为append()方法是同步操作,所以程序会产生大量加锁释放锁如果我们带有参数:
-XX:+DoEscapeAnalysis –XX:-EliminateLocks
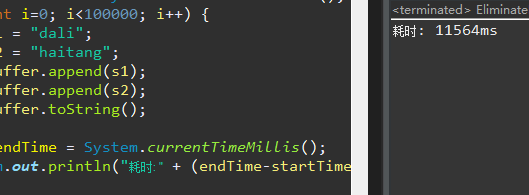
来执行程序,也就是关闭了锁消除,执行时产生大量同步操作,耗费的时间也相对较多:
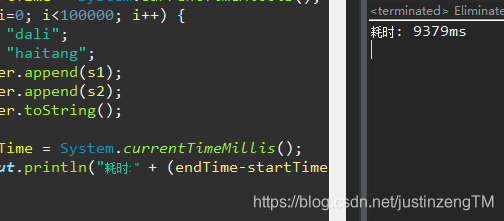
而如果我们用–XX:+EliminateLocks打开锁消除,执行时间就有了较可观的提升:

















 9万+
9万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









