




 本文介绍了JVM初始化过程中的_call_stub_entry和call_stub函数,详细解析了_call_stub_entry如何存储函数入口地址,以及在生成CallStub函数指针时的角色。在初始化链路中,stubRoutines_initl负责例程初始化,generate_call_stub函数生成首地址,而pc()函数用于获取例程的起始位置。同时,文章还探讨了JVM堆、代码段和数据段,以及ip和bp寄存器在函数调用中的作用。
本文介绍了JVM初始化过程中的_call_stub_entry和call_stub函数,详细解析了_call_stub_entry如何存储函数入口地址,以及在生成CallStub函数指针时的角色。在初始化链路中,stubRoutines_initl负责例程初始化,generate_call_stub函数生成首地址,而pc()函数用于获取例程的起始位置。同时,文章还探讨了JVM堆、代码段和数据段,以及ip和bp寄存器在函数调用中的作用。
在总结_call_stub_entry之前,先再次回顾下Java主函数调用必须经过的call_stub()函数,展开后得到的结构如下:
static CallStub call_stub()
{
return (CallStub)(castable_address(_call_stub_entry));
}
CallStub是自定义类型的函数指针,有八个参数,call_stub()最后返回的就是这么一个函数指针变量类型。castable_address则是一个函数,接收一个地址类型address变量,并将其转换为基本类型unsigned int,最后返回出去:
inline address_word castable_address(address x)
{
return address_word(x);
}
由此来看,_call_stub_entry是一个address类型,也就是标识的是某个内存地址,CallStub函数指针存放了这一地址后,相当于CallStub函数指针指向了某一个函数的入口,这样就可以调用函数了。_call_stub_entry在JVM初始化时就已经存放了某一个函数的入口地址,由generate_call_stub()函数完成首地址的生成。
初始化链路
JVM在初始化时就要对_call_stub_entry进行内存地址赋值,初始化过程中,从main()函数开始,整个初始化链路是这样的:
java.c:main()
java_md.c:LoadJavaVM()
jni.c:JNI_CreateJavaVM()
Threads.c:create_vm()
init.c:init_globals()
StubRoutines.cpp:stubRoutines_initl()
StubRoutines.cpp:initializel()
stubGenerator_x86_x32.cpp:StubGenerator_generate()
stubGenerator_x86_x32.cpp:StubCodeGenerator()
stubGenerator_x86_x32.cpp:generate_initial()
可与看到,在初始化链路中,stubRoutines_initl()负责例程的初始化,例程在上一篇日志里讲过,就是JVM初始化时写好的一些机器指令,为了实现特定的动作,例如函数调用与返回,异常处理等例程,CallStub函数指针里也有一个entry_point例程,它就是JVM调用Java方法时的入口,调用Java方法都必须先执行entry_point例程。
再往后走,链路的最后调用了generate_initial()函数,对_call_stub_entry变量进行初始化,来看看generate_initial()函数中都做了哪些事情:
void generate_initial() {
// Generates all stubs and initializes the entry points
// This platform-specific settings are needed by generate_call_stub()
create_control_words();
// entry points that exist in all platforms Note: This is code
// that could be shared among different platforms - however the
// benefit seems to be smaller than the disadvantage of having a
// much more complicated generator structure. See also comment in
// stubRoutines.hpp.
StubRoutines::_forward_exception_entry = generate_forward_exception();
StubRoutines::_call_stub_entry =
generate_call_stub (StubRoutines::_call_stub_return_address);
//下面源码省略....
}
在generate_initial()函数中看到了_call_stub_entry变量,它的初始化是得到genetate_call_stub()函数的返回值,该函数会产生一个首地址,赋值给_call_stub_entry进行初始化,产生首地址的过程比较复杂,一步一步慢慢来看它的源码,接着是看genetate_call_stub()函数:
address generate_call_stub(address& return_address) {
StubCodeMark mark(this, "StubRoutines", "call_stub");
address start = __ pc(); // 当前函数的入口地址
assert(frame::entry_frame_call_wrapper_offset == 2, "adjust this code");
bool sse_save = false;
const Address rsp_after_call(rbp, -4 * wordSize);
//下面源码省略....
}
第二行一个address类型的变量start,通过pc()函数获得首地址,保存的是当前这个例程的机器码起始位置。
pc()函数
来看看pc()函数的结构:
address pc() const {
return _code_pos;
}
返回类型是address,即一个内存地址,对应的是一个例程,JVM会初始化很多例程,每一个例程都是存放在一片连续的内存区域中的,最开始第一个例程的起始位置假设为0,例程所占内存为16个字节,那么_pc()函数就会返回0给start,JVM初始化第二个例程时,_pc()函数就会返回16,假设例程大小也为16个字节,那么结束位置就是32,第三个例程在初始化时_pc()函数得到的返回值就是32,以此类推。
JVM的进程内存中分有几个部分,JVM堆,代码段和数据段等,所有的例程都会放在JVM堆里,所以JVM在初始化时会创建一个较大的堆内存区域,专门用来存放各种例程。每一个例程占用一片连续的区域,并且有一个对应的generate()函数,两个例程之间的内存区域也是相连的,当第一个例程对应的generate()函数执行完后,_code_pos变量的值就会自动增加,大小等于例程的大小,例如16,那么到第二个例程调用generate()函数时,得到的_pc()返回值就是16。每一个generate()函数中都会有address start = _pc();这段代码,start得到返回值_code_pos就是上一个例程的偏移量最后的位置,该位置也是下一个例程的开始位置。
generate_all_stub()入参
ok,generate_all_stub()函数继续往下走,设置完start变量的偏移量后,接下来就是一些变量定义,寻址:
const Address call_wrapper (rbp, 2 * wordSize);
const Address result (rbp, 3 * wordSize);
const Address result_type (rbp, 4 * wordSize);
const Address method (rbp, 5 * wordSize);
const Address entry_point (rbp, 6 * wordSize);
const Address parameters (rbp, 7 * wordSize);
const Address parameter_size(rbp, 8 * wordSize);
const Address thread (rbp, 9 * wordSize);
const Address r15_save(rbp, r15_off * wordSize);
const Address r14_save(rbp, r14_off * wordSize);
const Address r13_save(rbp, r13_off * wordSize);
const Address r12_save(rbp, r12_off * wordSize);
const Address rbx_save(rbp, rbx_off * wordSize);
可以看到,result、result_type、method、parameters甚至entry_point,都是前面CallStub函数指针里的参数,拿其中一行代码来看,const Address result (rbp, 3 * wordSize);表达的意思是result变量在JVM堆中的位置是 3 * wordSize(%rbp),在JVM为每一个Java方法分配的栈空间中,可以将其分为四个部分,存放变量的变量区,存放参数的入参区,ip代码段寄存器和bp栈基寄存器。
变量区和入参区
变量区保存的是该Java方法中的一些局部变量,存放的是变量的引用,也就是地址,要注意的是,方法栈空间的变量区不是一定会初始化的,如果调用的Java方法中没有使用到局部变量,那么JVM不会分配出变量区。入参区在数据入参的时候用到,假如一个方法中又调用到了另一个方法,而且需要传入参数,那么就会将参数压栈到入参区,入参区存在与调用者的方法栈中,被调用这可以从里面拿到压栈后的参数。举个例子讲一下调用者和被调用者的关系,假设main()方法里调用了run()方法,那么main()方法就是调用者,run()方法就是被调用者,main()方法压栈的参数存放在了main()方法的方法栈中,run()方法从main()方法栈中获取入参,如果run()方法里面又调用其他方法,那么其他方法就从run()方法的方法栈中获取入参。
ip和bp寄存器
ip是代码段寄存器,bp是栈的基地址寄存器(或者叫栈基寄存器),这两个寄存器在函数执行call add指令时就会自动压栈到栈顶位置,看个例子:
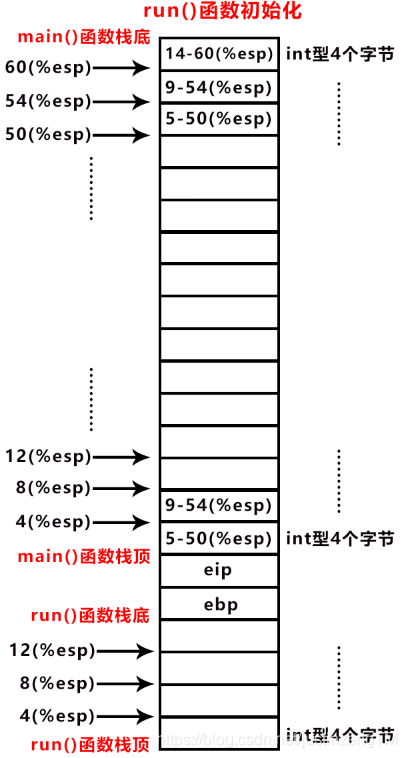
main()函数中调用run()函数时,会自动将eip和ebp寄存器压入main()函数的栈顶,ip代码段寄存器的作用就是为了让main()函数在执行完run()函数返回后,能继续执行main()函数下面的代码,具体做法就是在执行函数调用时,自动将eip压栈,待被调用函数执行完成后,eip出栈,恢复调用函数的执行位置。
bp栈基地址寄存器,作用就十分重要了,涉及到参数获取,例如一条指令movl8(%ebp) %eax,指的是从ebp寄存器向上偏移8个字节处获取参数数据,然后放到eax寄存器中。这里有一些地方需要注意的是,在JVM的栈空间中,内存地址从栈顶开始为低地址,向上分配,到栈底处为最高地址,例如还是上面那张图,main()函数栈底处为0(%esp),栈顶处为64(%esp),一共64字节内存空间,这是分配问题。还有一个是寻址问题,JVM在对数据进行寻址使用的是偏移量,用偏移量来确定数据的位置。拿回上面的图做例子,ebp寄存器的位置就是run()函数的栈底位置,那么它相对于run()栈底偏移量就是0,可以直接写成(%ebp),eip寄存器相对于run()函数栈底的位置是偏移了4个字节,所以用4(%ebp)表示,这是数据或变量通过被调用者栈底,也就是run()函数栈底来确定位置,还可以通过调用者的栈顶来确定数据的位置,一样的,如果取的数据在基准位置(例如ebp)的上方,也就是高地址位,那么指令前的数字就是正数,例如8(%ebp),意思是当前位置加上8个字节,相对的,如果位置在基准位置的下方,也就是低地址位,那么指令前的数字就是负数。


















 922
922

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









