




 本文介绍了决策树学习的基本概念,包括决策树的生成过程、划分选择准则(如信息熵、信息增益、增益率和基尼指数)、剪枝处理、连续与缺失值处理等,并对比了单变量与多变量决策树。
本文介绍了决策树学习的基本概念,包括决策树的生成过程、划分选择准则(如信息熵、信息增益、增益率和基尼指数)、剪枝处理、连续与缺失值处理等,并对比了单变量与多变量决策树。
决策树
决策树学习是一种逼近离散值目标函数的方法,在这种方法中学习到的函数被表示为一棵决策树。
4.1 基本流程
决策树的生成是一个递归过程:
以下3种情况会导致递归返回
1) 当前节点包含的样本全属于同一类别;
2) 当前属性集为空或所有样本在所有的属性上取值心痛,无法划分;
3) 当前节点包含的样本集为空;

一般一颗决策树包含:一个根节点、若干个内部节点和若干个叶子节点:
* 每个非叶节点表示一个特征属性测试。
* 每个分支代表这个特征属性在某个值域上的输出。
* 每个叶子节点存放一个类别。
* 每个节点包含的样本集合通过属性测试被划分到子节点中,根节点包含样本全集。4.2 划分选择
愿景:随着划分的进行,希望决策树的分支节点“纯度purity”越来越高!
1. 纯度(purity)
对于一个分支结点,如果该结点所包含的样本都属于同一类,那么它的纯度为1,而我们总是希望纯度越高越好,也就是尽可能多的样本属于同一类别。
2. 信息熵(information entropy)
假定当前样本集合D中第k类样本所占的比例为pk(k=1,,2,...,|y|),则D的信息熵定义为:
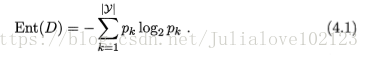
显然,Ent(D)值越小,D的纯度越高。因为0<=pk<= 1,故log2 pk<=0,Ent(D)>=0. 极限情况下,考虑D中样本同属于同一类,则此时的Ent(D)值为0(取到最小值)。当D中样本都分别属于不同类别时,Ent(D)取到最大值log2 |y|.
3. 信息增益(information gain)
信息增益准则对可取值数目较多的属性有所偏好;
假定离散属性a有V个可能的取值{a1,a2,...,aV}. 若使用a对样本集D进行分类,则会产生V个分支结点,记Dv为第v个分支结点包含的D中所有在属性a上取值为av的样本。不同分支结点样本数不同,我们给予分支结点不同的权重:|Dv|/|D|, 该权重赋予样本数较多的分支结点更大的影响、由此,用属性a对样本集D进行划分所获得的信息增益定义为:
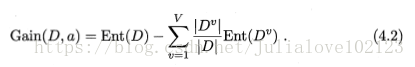
其中,Ent(D)是数据集D划分前的信息熵,∑v=1 |Dv|/|D|·Ent(Dv)可以表示为划分后的信息熵。“前-后”的结果表明了本次划分所获得的信息熵减少量,也就是纯度的提升度。显然,Gain(D,a) 越大,获得的纯度提升越大,此次划分的效果越好。
4. 增益率(gain ratio)
增益率准则对可取值数目较少的属性有所偏好;基于信息增益的最优属性划分原则——信息增益准则,对可取值数据较多的属性有所偏好。C4.5算法使用增益率替代信息增益来选择最优划分属性,增益率定义为:
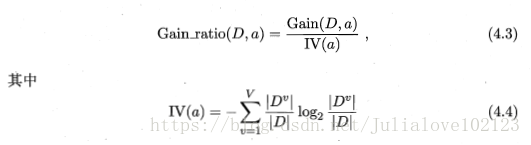
称为属性a的固有值。属性a的可能取值数目越多(即V越大),则IV(a)的值通常会越大。这在一定程度上消除了对可取值数据较多的属性的偏好。
事实上,增益率准则对可取值数目较少的属性有所偏好,C4.5算法并不是直接使用增益率准则,而是先从候选划分属性中找出信息增益高于平均水平的属性,再从中选择增益率最高的。
5. 基尼指数(Gini index)
CART决策树算法使用基尼指数来选择划分属性,基尼指数定义为:

可以这样理解基尼指数:从数据集D中随机抽取两个样本,其类别标记不一致的概率。Gini(D)越小,纯度越高。
属性a的基尼指数定义:

4.3 剪枝处理
剪枝(pruning)是决策树算法对付过拟合(太依赖训练样本)的主要手段,剪枝的策略有两种如下:
* 预剪枝(prepruning):在构造的过程中先评估,再考虑是否分支。
* 后剪枝(post-pruning):在构造好一颗完整的决策树后,自底向上,评估分支的必要性。一般情况下,后剪枝的欠拟合风险小,泛化能力优于预剪枝;
后剪枝开销比预剪枝大得多;
4.4连续与缺失值
- 1)连续值处理
对于连续值的属性,若每个取值作为一个分支则显得不可行,因此需要进行离散化处理,常用的方法为二分法,基本思想为:给定样本集D与连续属性α,二分法试图找到一个划分点t将样本集D在属性α上分为≤t与>t。
* 首先将α的所有取值按升序排列,所有相邻属性的均值作为候选划分点(n-1个,n为α所有的取值数目)。
* 计算每一个划分点划分集合D(即划分为两个分支)后的信息增益。
* 选择最大信息增益的划分点作为最优划分点。- 2)缺失值处理
假定为样本集中的每一个样本都赋予一个权重,根节点中的权重初始化为1,则定义:

在属性值缺失的情况下需要解决两个问题:
(1)如何选择划分属性。
解决方法:通过在样本集D中选取在属性α上没有缺失值的样本子集,计算在该样本子集上的信息增益,最终的信息增益等于该样本子集划分后信息增益乘以样本子集占样本集的比重:
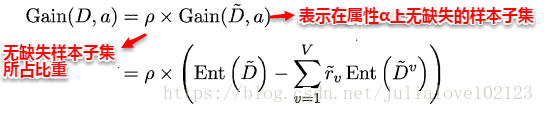
(2)给定划分属性,若某样本在该属性上缺失值,如何划分到具体的分支上。
解决方法:若该样本子集在属性α上的值缺失,则将该样本以不同的权重(即每个分支所含样本比例)划入到所有分支节点中。该样本在分支节点中的权重变为:

4.5 多变量决策树
相比于ID3、C4.5、CART这种单变量决策树(分支时只用一个属性),多变量决策树在分支时用的是多个属性的加权组合,来个直观的图(以下),这个是单变量决策树学习出来的划分边界,这些边界都是与坐标轴平行的,多变量决策树的划分边界是倾斜于坐标轴的。
决策树算法:

------*-*---------------------------------------------------------------------------------------------------------*-*----
更多详细内容请关注公众号:目标检测和深度学习

-------…^-^……----------------------------------------------------------------------------------------------------------…^-^……--


















 1150
1150

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











