




 本文提出了一种新的知识蒸馏方法,不直接模仿大模型的输出,而是学习其层间关系,通过量化指标FSP矩阵,使学生模型快速学习到解题流程,实现快速优化、网络最小化和迁移学习。
本文提出了一种新的知识蒸馏方法,不直接模仿大模型的输出,而是学习其层间关系,通过量化指标FSP矩阵,使学生模型快速学习到解题流程,实现快速优化、网络最小化和迁移学习。
A Gift from Knowledge Distillation:Fast Optimization, Network Minimization and Transfer Learning 论文阅读
概述
上一篇博客中的FitNets,本文作者是这么分析的:

作者打了个比方,对于人类,老师教学生做题时,一个中间的结果并不重要,我们更应该学习的是解题流程。
这也是本文的核心idea,不拟合大模型的输出,而是去拟合大模型层与层之间的关系,这才是我要转移和蒸馏的知识!
Method
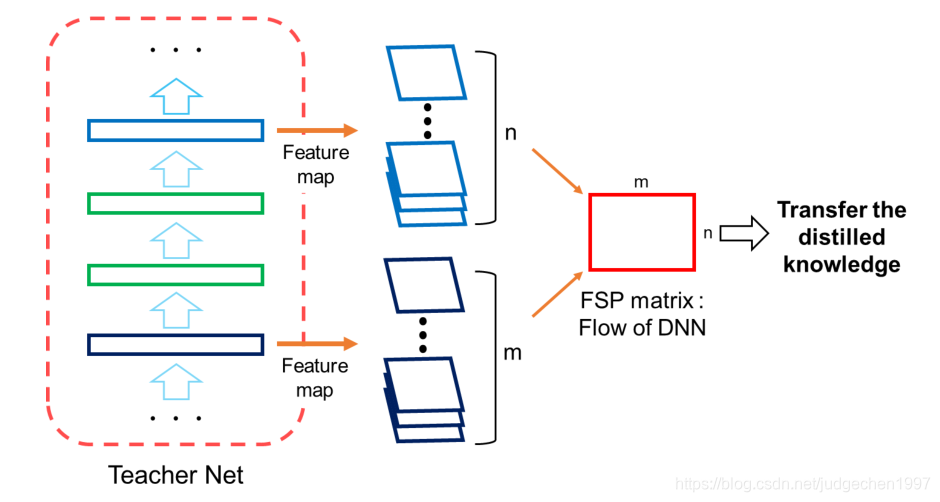
这个关系是用层与层之间的内积(点乘)来定义。假如说甲层有 M 个输出通道,乙层有 N 个输出通道,就构建一个 M*N 的矩阵来表示这两层间的关系。
其中 (i, j) 元是甲层第 i 个通道和 乙层第 j 个通道的内积(因此此方法需要甲乙两层 feature map 的形状相同):
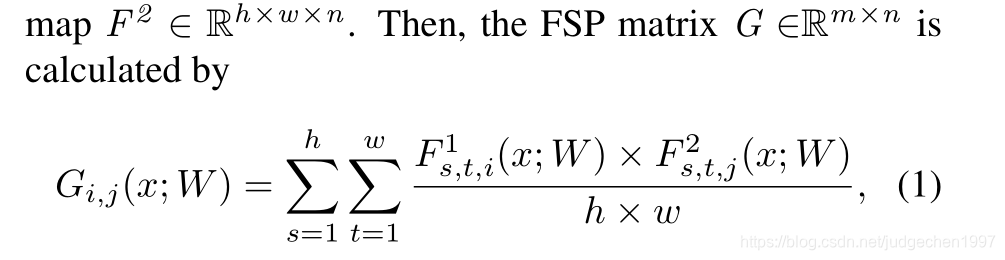
这样每两个层之间就可以得到一个代表knowledge的矩阵FSP:
FSP可以类比成一个解体流程和方法,因而又定义了一个loss:
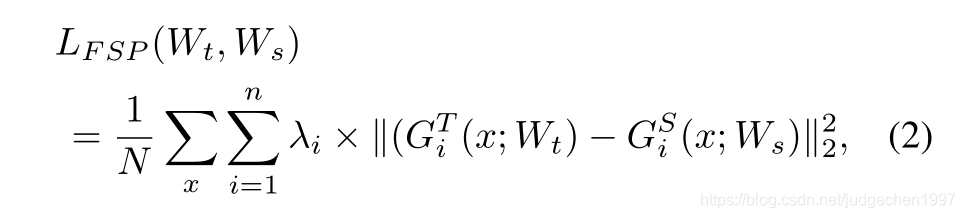
这样student就可以来学习teacher的这个流程,也就是一些层间关系的量化指标FSP:
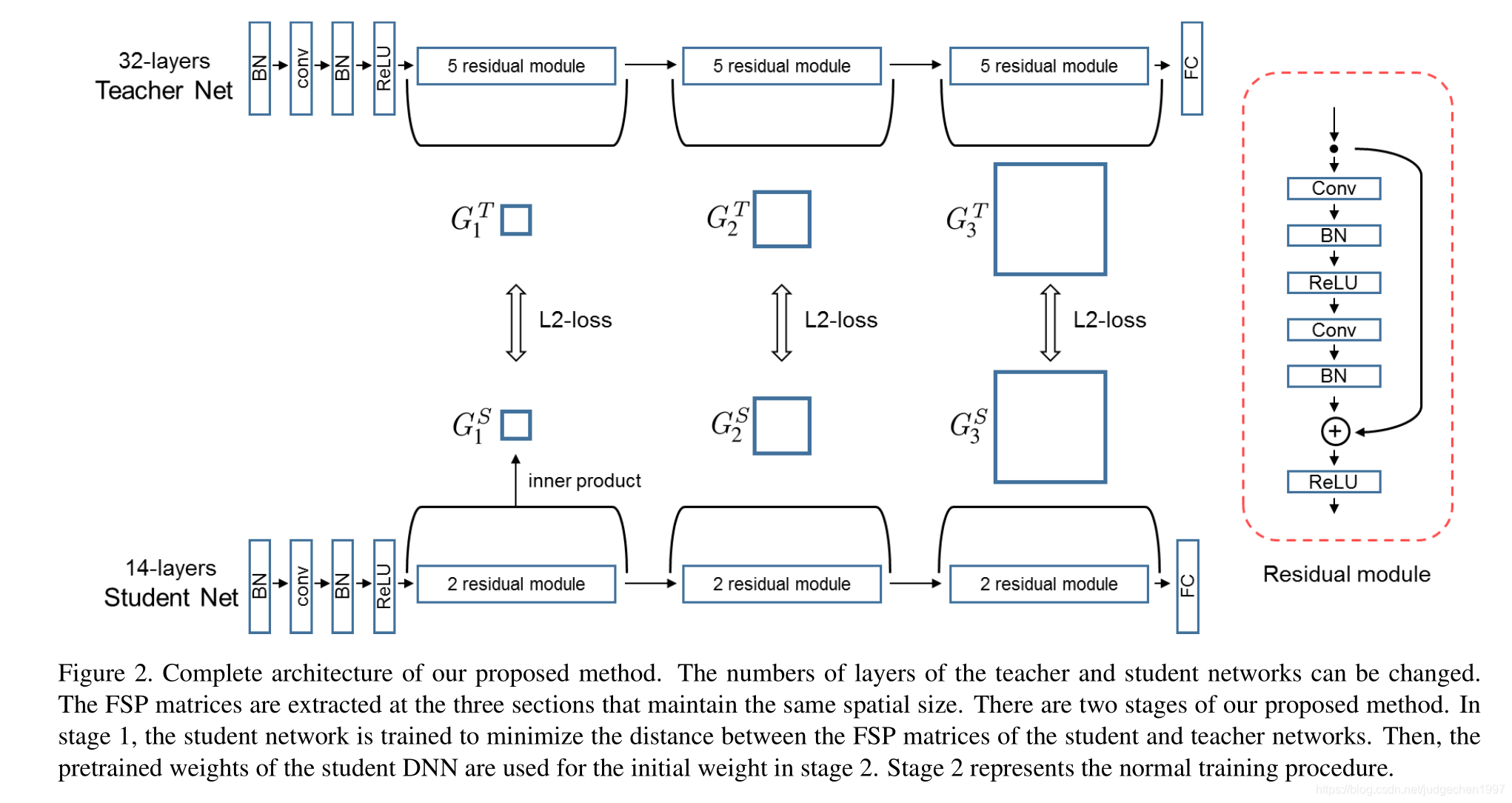
训练过程
训练的第一阶段:最小化教师网络FSP矩阵与学生网络FSP矩阵之间的L2 Loss,用来初始化学生网络的可训练参数。
训练的第二阶段:在目标任务的数据集上fine-tune学生网络。从而达到知识迁移、快速收敛、以及迁移学习的目的。
总结
这篇文章的做法不是直接学结果,而是学习得到这种结果的方法和过程,是一个不错的思路。
毕竟,授以鱼不如授以渔。


















 18万+
18万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









