




 FitNets是一种深度模型压缩方法,通过利用教师网络的中间层特征指导学生网络训练,使学生网络在保持轻量化的同时,深度增加且性能优秀。此方法在ICLR2015年提出,旨在解决深层网络优化难题。
FitNets是一种深度模型压缩方法,通过利用教师网络的中间层特征指导学生网络训练,使学生网络在保持轻量化的同时,深度增加且性能优秀。此方法在ICLR2015年提出,旨在解决深层网络优化难题。
概述
在Hinton教主挖了Knowledge Distillation这个坑后,另一个大牛Bengio立马开始follow了,在ICLR2015发表了文章FitNets: Hints for Thin Deep Nets
有一个背景是,可能那时候残差网络还没出来,deeper网络不好优化,所以teacher没那么深,而利用teacher的hint辅助训练student,可以把student网络做的更深:

motivation是,引导帮助训练一个deeper and thinner student,既轻量化又有不错的表现
核心idea在于,不仅仅是将teacher的输出作为knowledge,在一些中间隐含层的表达上,student也要向teacher学习:

由于teacher和student在一些隐含层的尺寸是不对应的,需要使用额外的参数建立二者间的映射:

Method
HINT-BASED TRAINING
Student网络整体是要比teacher小的。但作者发现,student可以适当的比teacher更深一点,有助于取得更好的表现。为了更好的训练这种thin deep net,作者提出了一个概念:hint
Hint定义是:teacher的隐含层输出,用来引导student的学习过程。类似的又从student中选择一个隐含层叫做guided layer,我们希望guided layer能预测出与hint layer相近的输出。
(文章中,hint/guided layer好像都是选在网络的正中间……)
在student的学习过程中,loss定义如下:

vvv 是特征输出 ,rrr 是针对teacher student的隐含层尺寸不一致而设计的regressor,期望student的guided layer经过这个regressor后,与hint layer相近。
其中,为了减少参数,regressor不是FC,而是conv的形式。使用k1×k2k_1\times k_2k1×k2的kernel,将student Ng,1×Ng,2N_{g,1}\times N_{g,2}Ng,1×Ng,2的feature,回归到teacher Nh,1×Nh,2N_{h,1}\times N_{h,2}Nh,1×Nh,2 的feature (Ng,i−ki+1=Nh,iN_{g,i}-k_i+1=N_{h,i}Ng,i−ki+1=Nh,i)
FITNET STAGE-WISE TRAINING
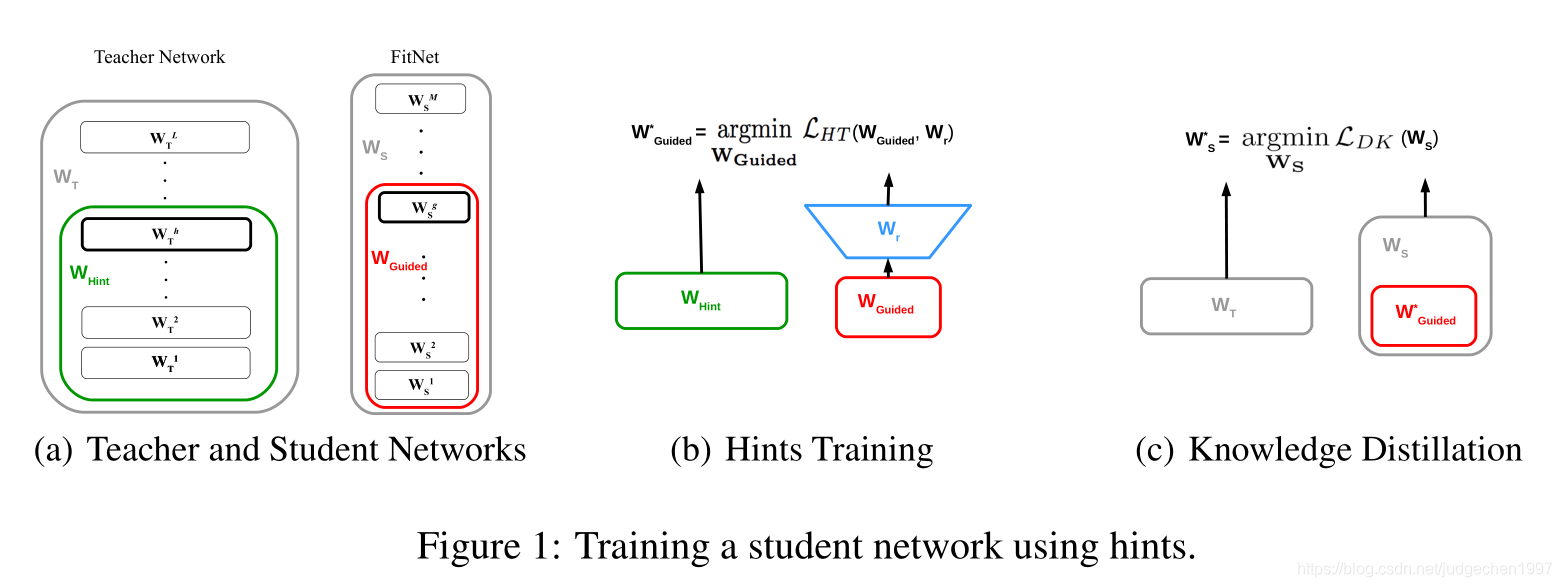
上图一个细节是,student 相比于teacher是thin and deep
(注:图最右边不是LDKL_{DK}LDK,应该是LKDL_{KD}LKD,代表Hinton定义的知识蒸馏训练联合loss)
在训练时,先是用hint-based training,基于上一节的LHTL_{HT}LHT进行监督,诱导student在隐含层输出与teacher相近的特征表达。而训练完的模型作为一个pretrained model,再用hinton之前的方法,让student同时学习hard label&soft target

(不过这里我有些疑问就是,虽然学习到了相近的feature表征方式,但是那个统一feature尺度的regressor在第二步训练时并不会用到,这样输出的两个特征还是有一些差距的。这种强行回归的方式总感觉不够优雅。
再者,这样的一个方式仅仅是用做初始化模型,这让我有点怀疑其作用能有多大。可不可以设计一个联合的训练方式嘛???在学习hard label、soft target的同时,对中间一些层也进行hint-based约束会更有效嘛?看看之后的论文有没有和我类似的想法)
好吧,在实验部分,作者表明自己做了联合优化hint和classification target(指hard label?)的实验,但效果不好,或者说没找到一个合适的方式来进行联合训练:

对于联合优化hint&soft target,作者认为不好学习……那上一个不是train了,只是效果不好嘛???有点懵……

实验结果
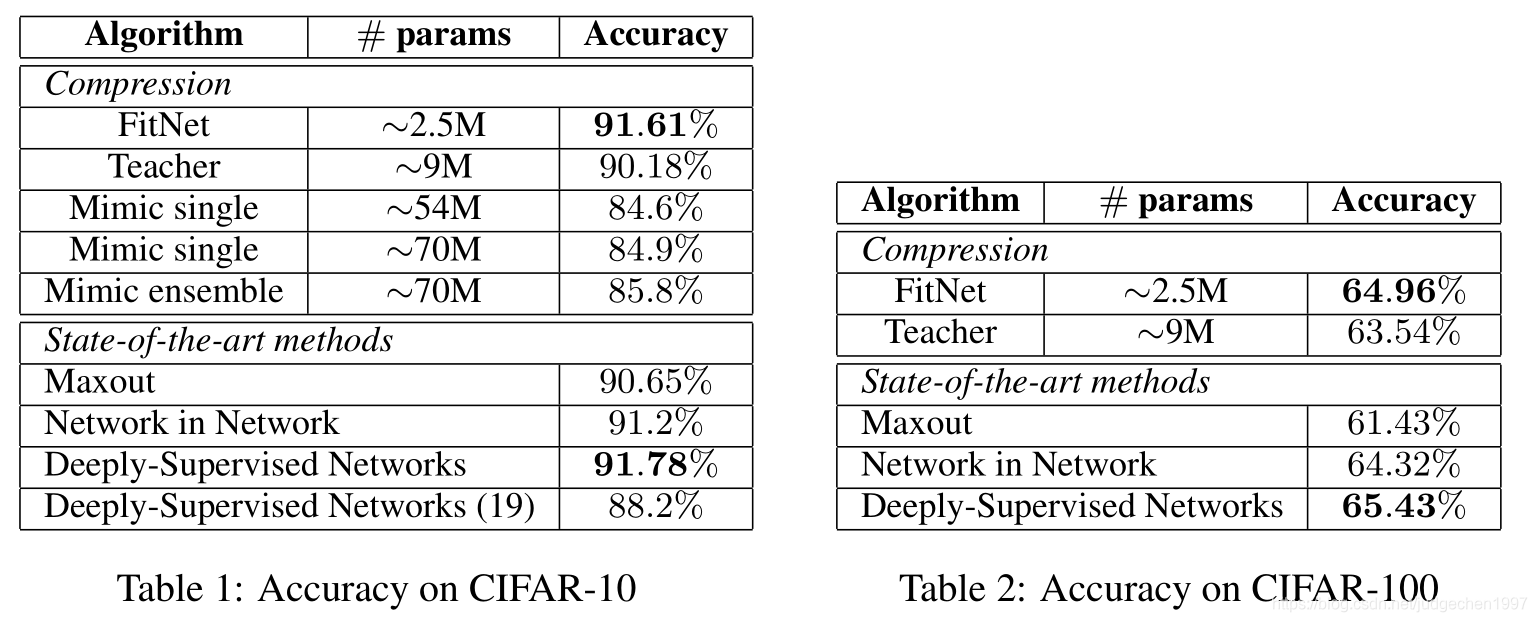
实验结果上,student比teacher参数少,效果比teacher还要好,有点东西啊。
不过这种效果好也许是网络更深导致的,作者为什么没有设计一个同样配置的网络,不使用hint,甚至不使用soft target作为对比???可能是作者认为student效果已经逼近state-of-the-art,单纯训一个和student相同配置的网络没这效果??
(好吧后来仔细看了论文,可能那时候没有resnet,deep网络不好优化,这篇论文motivation就是为了更好的优化deepper网络!!!)

















 2010
2010

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









