






你用RAG时,怎么评估加入的检索信息是否能帮你提升下游任务的效果?如何判断哪些信息可能有用,哪些可能没用?怎样的信息是补充,怎样的信息是干扰?
如果是你,你会怎么解决这个问题?我想到的主要有几种方法:
-
怎么用就怎么评--端到端,一个个信息加进去训练完再去评估模型,再筛选出模型表现有提升的信息统一训一把。但成本太高,太低效;
-
靠经验,领域先验判断,较依靠人对业务的理解;
-
低成本提前推演。利用已有的LLM不重训,尝试不同检索信息加入是否能在测试集上表现变好,再筛选出最佳信息组合,训一版模型,成本较低,与目标应用也一致;
-
回到检索问题的本质,其实就是看检索出的doc是否包含目标输出的正确答案/答案片段,可以根据检索出的doc和groudtruth的匹配度作为query-doc的软标签训一个打分模型,后对doc进行打分,匹配度可以是文本相关性,也可以是精确匹配,根据实际任务调整,等价于搜索场景的相关性模型,若无现成的模型重训一个成本也较高;
实际上述几种方案会根据实际场景叠加使用。
让我们看看SIGIR2024的最佳短文《Evaluating Retrieval Quality in Retrieval-Augmented Generation》给出怎样的答案:
该文章提出了一种叫eRAG的方法:
-
检索模型R,根据query q检索出doc列表R_k,对每个doc d,和q一起输入下游目标应用的模型LLM M,得到输出,与标准答案y进行比较评估
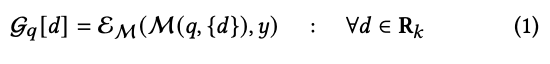
-
至于评估函数,则可以根据实际任务需求选择,precision、recall、F值、MAP、MRR,还是NDCG。
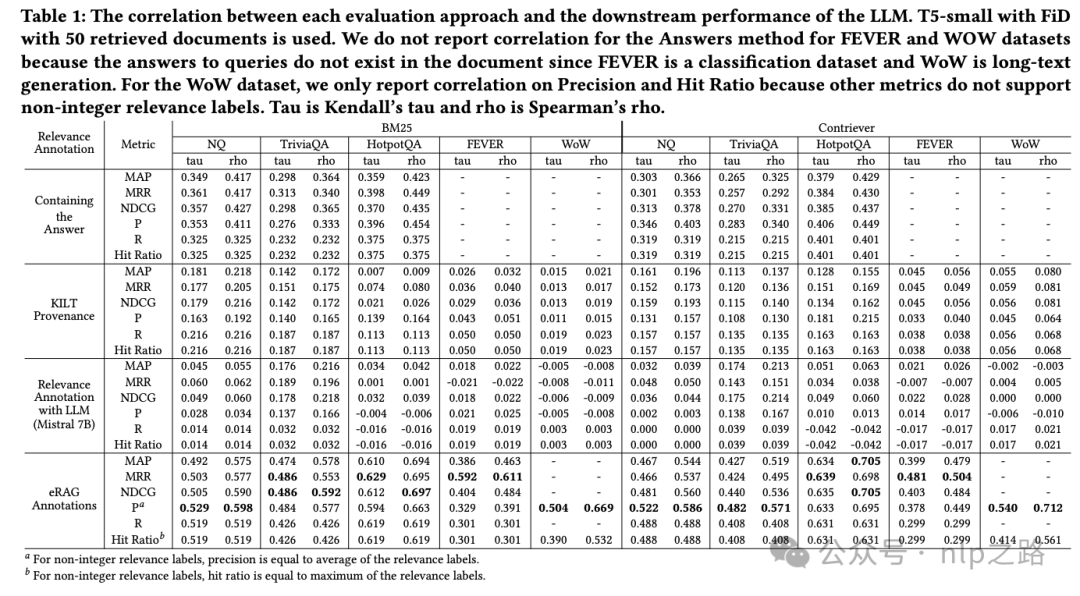
表述上有些许出入,但本质上就是一开始我们提的第三种解决方案,也是殊途同归了。
附录:
论文链接:https://arxiv.org/pdf/2404.13781
代码:https://github.com/alirezasalemi7/eRAG
欢迎微信扫码关注nlp之路,发送LLM领取奖品~


















 3709
3709

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









