




多模态大语言模型与灾难性遗忘的挑战
在人工智能领域的迅猛发展中,多模态大语言模型(Multimodal Large Language Models, MLLMs)已成为最具前景的研究方向之一,它融合了视觉、语言等多种模态信息,展现出强大的跨模态理解与生成能力。然而,当我们将这些模型适配到具体下游任务时,一个长期困扰深度学习领域的问题——灾难性遗忘(Catastrophic Forgetting)变得尤为突出。简单来说,灾难性遗忘是指模型在学习新任务时,突然且严重地丧失先前学到的知识或技能的现象。这种现象在人类学习中极为罕见——一个学会骑自行车的人不会在学会开车后突然忘记如何骑车——但对现有人工智能系统却构成了巨大挑战。
马毅团队提出的EMT框架(Evaluating MulTimodality)正是针对这一关键问题进行的开创性研究,其论文《Investigating the Catastrophic Forgetting in Multimodal Large Language Models》首次系统性地评估了多模态大语言模型中的灾难性遗忘现象。该研究揭示了即使冻结视觉编码器参数,仅微调语言部分,MLLMs仍会快速丧失其在预训练阶段获得的基本能力,这一发现对实际应用具有重要意义。
想象一下,当我们精心训练一个能够准确描述医学影像的辅助诊断模型后,为了提升其对罕见病例的识别能力,我们使用一批专业数据对其进行微调,结果却发现这个模型突然忘记了如何识别常见病症——这正是灾难性遗忘在现实世界可能造成的严重影响。在自动驾驶、医疗诊断、工业检测等安全关键领域,这种遗忘现象可能导致严重后果,因此对它的深入理解和有效缓解变得至关重要。
EMT评估框架:揭示MLLMs灾难性遗忘的系统方法
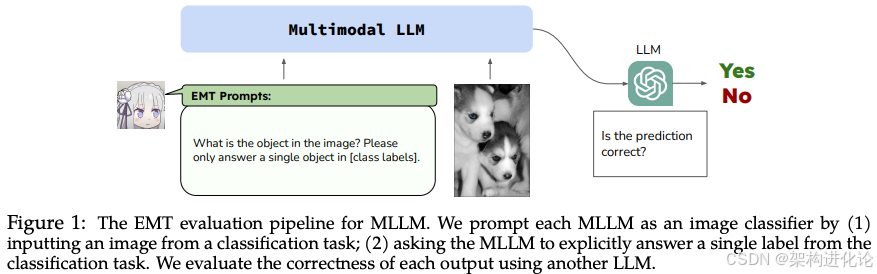
EMT框架的构建与设计原理
EMT框架的核心创新在于其简洁而高效的评估方法论——将多模态大语言模型视为图像分类器进行处理,通过系统化的评估流程量化灾难性遗忘的程度。这种设计的巧妙之处在于,它规避了生成任务中评估的复杂性,利用分类任务的客观指标直接衡量模型性能的变化。
具体来说,EMT框架的构建包含三个关键步骤:
-
基准性能建立:在微调前,使用预训练的MLLMs在标准图像分类数据集(如ImageNet)上进行评估,获取模型在各类别上的初始准确率
-
可控微调过程:按照标准流程在目标数据集上对MLLM进行微调,同时保持实验条件的严格可控
-
遗忘程度量化:微调后,再次在相同的标准分类数据集上评估模型,比较微调前后性能差异,精确计算遗忘程度
为了更直观地理解EMT框架的评估流程,以下流程图展示了其核心工作过程:
评估指标与理论创新
EMT框架采用了一系列严谨的指标来评估灾难性遗忘,其中平均准确率下降(Average Accuracy Drop)是最核心的指标之一,计算公式如下:
其中, 和
分别表示微调前后模型在第i个类别上的准确率,N为类别总数。该值越大,表明灾难性遗忘越严重。
除了准确率下降外,EMT还关注知识保留率(Knowledge Retention Rate)和跨任务泛化差距(Cross-task Generalization Gap)等重要指标,从多角度全面刻画模型的遗忘模式。
研究中一个令人惊讶的发现是:早期阶段的微调实际上有助于提升模型在其他图像数据集上的性能,这表明适度的微调可以增强文本和视觉特征的对齐效果。然而,随着微调过程的深入,模型开始出现幻觉(hallucination)现象,产生与输入图像不相关的输出,导致泛化能力显著下降。这一发现揭示了灾难性遗忘的复杂本质——它不是简单的性能衰退,而是模型内部表征结构的重构过程。
灾难性遗忘的深度观察与关键发现
EMT评估结果与遗忘模式分析
通过EMT框架对多个开源MLLMs(包括LLaVA、InstructBLIP等)进行的系统评估揭示了几个关键现象。研究发现,几乎所有被评估的MLLMs在标准图像分类任务上都未能保持与其视觉编码器相同的性能水平。即使视觉编码器保持冻结状态,仅训练连接视觉与语言模式的投影层,模型仍然会出现显著的灾难性遗忘。
进一步的分析表明,灾难性遗忘呈现出明显的任务相关性和层级性。具体而言:
-
低级视觉任务(如边缘检测、颜色识别)的遗忘程度相对较低
-
高级语义任务(如场景理解、关系推理)的遗忘更为显著
-
跨模态对齐能力表现出最高的脆弱性,即使视觉和语言特征本身得以保留,它们之间的关联也会迅速退化
以下表格展示了EMT评估中观察到的典型遗忘模式:
| 模型能力类型 | 遗忘程度 | 恢复难度 | 对下游任务影响 |
|---|---|---|---|
| 低级视觉特征 | 低 | 易 | 有限 |
| 高级语义理解 | 中高 | 中等 | 显著 |
| 跨模态对齐 | 高 | 难 | 严重 |
| 复杂推理能力 | 很高 | 极难 | 极其严重 |
灾难性遗忘的机制解析
为什么即使视觉编码器保持冻结,MLLMs仍然会出现灾难性遗忘?论文通过一系列消融研究揭示了这一现象的内在机制。关键在于语言主导的行为模式(Language-Dominant Behavior Pattern)——随着微调进行,模型逐渐依赖语言模态中的统计规律,而非视觉证据,来生成回答。
这种现象类似于人类的确认偏差(Confirmation Bias)——当模型接收到一个新图像时,它会基于最近微调数据中的语言模式“猜测”答案,而不是仔细“观察”图像内容。例如,一个在医疗数据上微调的模型可能会忽略图像实际内容,而直接生成与疾病相关的描述,这就是典型的幻觉现象。
从参数更新的角度来看,即使投影层只占模型总参数的很小一部分(通常<1%),它们在跨模态推理中扮演着关键枢纽角色。微调过程中,这些参数的变化会扭曲整个视觉-语言对齐空间,导致预训练阶段建立的丰富关联被简化或覆盖。
早期微调的正向效应与过度微调的风险
有趣的是,研究发现了灾难性遗忘过程中的一个非线性阶段——在微调初期,模型不仅在目标任务上表现提升,在部分原始任务上也展现出改进迹象。这一阶段的微调实际上起到了细化对齐(Refined Alignment)的作用,增强了文本和视觉特征的协调性。
这类似于一个学生在学习一门新学科初期,发现这门新知识反而帮助他更好地理解了已学课程。然而,随着微调继续,过度 specialization(过度专门化)开始出现,模型逐渐丧失通用性,表现出强烈的任务偏见。
这一发现指出了微调时机(Fine-tuning Timing)的重要性——适度的早期微调可能对模型有益,而过度微调则导致不可逆的遗忘。在实际应用中,这提示我们可以探索早期停止(Early Stopping)策略或选择性微调(Selective Fine-tuning)方法来平衡新任务学习和旧知识保留。
超越评估:针对灾难性遗忘的创新解决方案
参数高效微调与自适应选择机制
随着对灾难性遗忘机制的深入理解,研究者提出了多种创新解决方案。AdaDARE-γ是一种典型的高效适应方法,它通过自适应参数选择从微调模型中识别并保留最任务相关的参数,同时控制任务特定信息注入,平衡预训练知识的保留与新能力的获取。
以下是AdaDARE-γ核心参数选择机制的简化代码实现:
import torch
import torch.nn as nn
class AdaDAREGamma:
def __init__(self, model, gamma=0.3):
"""
AdaDARE-γ 初始化
Args:
model: 预训练模型
gamma: 信息注入控制因子,平衡新旧知识
"""
self.model = model
self.gamma = gamma
self.original_params = {name: param.clone() for name, param in model.named_parameters()}
def adaptive_parameter_selection(self, finetuned_params, threshold_ratio=0.1):
"""
自适应参数选择机制
Args:
finetuned_params: 微调后的模型参数
threshold_ratio: 参数变化阈值比例,控制选择敏感度
Returns:
selected_params: 选中的参数掩码,标识需要保留的变更
"""
selected_params = {}
for name, param in finetuned_params.items():
if name in self.original_params:
# 计算参数变化量
delta = param - self.original_params[name]
delta_norm = torch.norm(delta)
# 基于变化幅度和重要性选择参数
if delta_norm > threshold_ratio * torch.norm(self.original_params[name]):
selected_params[name] = delta
return selected_params
def controlled_knowledge_injection(self, selected_deltas):
"""
受控知识注入策略
Args:
selected_deltas: 选中的参数变化量
Returns:
updated_params: 更新后的模型参数
"""
updated_params = {}
for name, original_param in self.original_params.items():
if name in selected_deltas:
# 控制新知识注入强度
updated_params[name] = original_param + self.gamma * selected_deltas[name]
else:
updated_params[name] = original_param
return updated_params
这种方法的关键在于,它不要求重新训练过程,而是智能地融合预训练和微调模型的参数,在保留大部分预训练知识的同时,选择性吸收新任务所需的能力。实验证明,AdaDARE-γ能在保持98.2%预训练效果的同时,达到98.7%标准微调在新任务上的性能。
多场景持续学习与统一表征对齐
针对现实世界中数据流天然具有多场景(multi-scenario)特性的挑战,研究者提出了Unifier方法(mUltimodal coNtInual learning with MLLMs From multi-scenarIo pERspectives),专门解决不同场景(如高空、水下、低空和室内)下的视觉差异导致的灾难性遗忘。
Unifier的核心思想是将不同场景的视觉信息解耦到不同的分支中,同时将它们投影到同一特征空间,并通过一致性约束保持跨场景视觉表示的稳定性。
Unifier方法在20步持续学习后仍能保持85.2%的F1分数,显著高于传统LoRA和模型裁剪方法,同时遗忘率最低。这一改进源于其对视觉差异的显式建模,而非仅关注参数效率。
基于提示学习与正向迁移的方法
另一种应对灾难性遗忘的思路是利用提示学习(Prompt Tuning)技术。Fwd-Prompt(Prompt Tuning with Positive Forward Transfer)方法通过将提示梯度投影到残差空间,最小化任务间干扰,同时投影到预训练子空间以重用预训练知识。
这种方法的关键发现是:不同的输入嵌入间存在较大差异,导致模型学习旧任务和预训练任务的无关信息,进而引起灾难性遗忘和负向前向迁移(Negative Forward Transfer)。Fwd-Prompt通过解耦这两个因素,实现了在更新更少参数且不需要旧样本的情况下,取得最先进的性能。
双流记忆系统与错误感知学习
受人类认知机制启发,ViLoMem框架引入了双流记忆系统,分别编码视觉分心模式和逻辑推理错误,使MLLMs能够从成功和失败的经验中学习。这种设计模拟了人类大脑中语义记忆的处理方式,通过分别但协调的表征流保存视觉和抽象知识。
ViLoMem遵循生长-精炼(grow-and-refine)原则,逐步积累和更新多模态语义知识——保持稳定、可泛化的策略,同时避免灾难性遗忘。在六个多模态基准测试上的实验表明,ViLoMem一致提高了pass@1准确率,并显著减少了重复的视觉和逻辑错误。
未来发展方向与挑战
尽管EMT框架及相关解决方案在理解和缓解灾难性遗忘方面取得了显著进展,多模态大语言模型的持续学习仍然面临诸多挑战和未来研究方向。
基础问题与机制研究
从理论基础来看,我们需要更深入地理解灾难性遗忘的根本原因。当前研究主要集中在现象观察和经验性解决方案,对遗忘的内在机制理论理解仍然不足。未来研究可能需要探索:
-
MLLMs中知识表征的拓扑结构如何在不同任务间发生变化
-
不同架构组件(视觉编码器、投影层、LLM)对遗忘的相对贡献度
-
任务相似性与遗忘程度之间的量化关系
-
跨模态对齐中的关键瓶颈及其对遗忘的敏感度
类人学习机制的探索
从生物启发视角,人类学习机制中的记忆巩固(Memory Consolidation)和知识重组(Knowledge Reorganization)过程为AI研究提供了丰富灵感。未来可能的研究方向包括:
-
睡眠式回放(Sleep-like Replay)机制,在训练间隙模拟记忆巩固过程
-
渐进课程学习(Gradual Curriculum Learning),模仿人类从易到难的学习过程
-
弹性-稳定性平衡(Plasticity-Stability Balance)的动态调节,类似人类大脑中神经可塑性的调节机制
实用系统与评估框架
从应用角度,我们需要开发更贴近实际场景的持续学习系统和评估框架:
-
更全面的评估基准:除了EMT的图像分类评估,需要涵盖多样下游任务(如VQA、描述生成、推理等)的评估体系
-
实时适应能力:针对边缘计算场景的轻量级持续学习方案,使模型能适应不断变化的用户需求
-
个性化与通用性平衡:如何在保持模型通用能力的同时,实现用户特定适配而不导致遗忘
-
道德与安全考量:持续学习过程中的安全边界确保,防止模型通过不断学习偏离原始设计目标
结论
《Investigating the Catastrophic Forgetting in Multimodal Large Language Models》论文及其提出的EMT评估框架,为理解和解决多模态大语言模型中的灾难性遗忘问题提供了关键见解和方法论基础。通过系统性的评估和深入的机制分析,该研究揭示了即使冻结视觉编码器,MLLMs仍会因投影层参数更新和语言主导的行为模式而产生显著遗忘。
随着AdaDARE-γ、Unifier、Fwd-Prompt和ViLoMem等创新方法的出现,我们在平衡模型稳定性与可塑性方面拥有了更多有效工具。这些方法从参数选择、场景解耦、提示学习和双流记忆等不同角度,为灾难性遗忘问题提供了多样化的解决方案。
未来,随着对灾难性遗忘机制的进一步理解和新技术不断涌现,我们有望构建出真正具备持续学习能力的多模态智能系统,能够在不断变化的环境中积累知识、适应新任务,同时保留已有能力,最终实现更通用、更可靠的人工智能。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











