




在当今的互联网应用中,数据一致性是所有架构师必须面对的核心挑战。想象一下这样的场景:当你在电商平台下单时,库存的扣减、订单的创建、支付的处理必须在同一个逻辑单元中完成——要么全部成功,要么全部失败。这种“全有或全无”的特性,正是事务处理要解决的根本问题。
事务隔离级别作为数据库系统的核心特性,直接影响着系统的并发性能和数据一致性。在这篇文章中,我们将深入探讨事务隔离级别的架构设计,从基础理论到创新实践,从问题起源到解决方案,为您呈现一幅完整的技术演进图景。(扩展阅读:MySQL事务隔离级别:从并发困境到架构革新、MySQL事务日志深度解析:Undo Log与Redo Log的协同设计奥秘)
事务基础与ACID特性
事务的本质
事务是数据库管理系统中的逻辑工作单位,它包含了一系列的操作,这些操作要么全部执行,要么全部不执行。事务的四大特性(ACID)构成了现代数据库系统的理论基础:
-
原子性(Atomicity):事务中的所有操作要么全部完成,要么全部不完成
-
一致性(Consistency):事务执行前后,数据库必须保持一致状态
-
隔离性(Isolation):并发事务之间相互隔离,互不干扰
-
持久性(Durability):事务完成后,对数据库的修改是永久性的
隔离性的重要性
隔离性之所以复杂,是因为它需要在两个相互矛盾的目标之间找到平衡:一方面要保证数据的一致性,另一方面又要最大化系统的并发性能。没有适当的隔离机制,就会出现各种数据异常问题。
并发事务的典型问题
在深入探讨隔离级别之前,我们需要理解在没有适当隔离机制时会出现哪些问题。让我们通过一个银行转账的案例来具体说明。

脏读(Dirty Read)
场景:用户A向用户B转账100元,事务执行过程中,B查询余额看到了A未提交的转账,但随后A的事务回滚了。
// 脏读示例代码
public class DirtyReadExample {
private Connection conn;
public void transfer(String fromAccount, String toAccount, BigDecimal amount) {
try {
conn.setAutoCommit(false);
// 减少转出账户余额
String sql1 = "UPDATE accounts SET balance = balance - ? WHERE account_id = ?";
PreparedStatement pstmt1 = conn.prepareStatement(sql1);
pstmt1.setBigDecimal(1, amount);
pstmt1.setString(2, fromAccount);
pstmt1.executeUpdate();
// 此时另一个事务读取了转出账户的余额,看到了未提交的修改
// 但如果这个事务回滚,另一个事务就读到了不存在的数据
// 增加转入账户余额
String sql2 = "UPDATE accounts SET balance = balance + ? WHERE account_id = ?";
PreparedStatement pstmt2 = conn.prepareStatement(sql2);
pstmt2.setBigDecimal(1, amount);
pstmt2.setString(2, toAccount);
pstmt2.executeUpdate();
conn.commit();
} catch (SQLException e) {
try {
conn.rollback();
} catch (SQLException ex) {
ex.printStackTrace();
}
}
}
}不可重复读(Non-repeatable Read)
场景:用户A在事务中两次查询账户余额,在两次查询之间,用户B完成了向A的转账并提交,导致A两次查询结果不一致。
// 不可重复读示例代码
public class NonRepeatableReadExample {
private Connection conn;
public void checkBalance(String accountId) {
try {
conn.setAutoCommit(false);
// 第一次查询余额
BigDecimal balance1 = getBalance(accountId);
System.out.println("第一次查询余额: " + balance1);
// 在此期间,另一个事务修改了该账户余额并提交
// 第二次查询余额
BigDecimal balance2 = getBalance(accountId);
System.out.println("第二次查询余额: " + balance2);
// 两次查询结果不一致 - 不可重复读
if (!balance1.equals(balance2)) {
System.out.println("检测到不可重复读!");
}
conn.commit();
} catch (SQLException e) {
// 处理异常
}
}
private BigDecimal getBalance(String accountId) throws SQLException {
String sql = "SELECT balance FROM accounts WHERE account_id = ?";
PreparedStatement pstmt = conn.prepareStatement(sql);
pstmt.setString(1, accountId);
ResultSet rs = pstmt.executeQuery();
return rs.next() ? rs.getBigDecimal("balance") : BigDecimal.ZERO;
}
}幻读(Phantom Read)
场景:银行系统统计账户数量,第一次查询有100个账户,在统计过程中有新账户开户并提交,第二次查询变成了101个账户。
// 幻读示例代码
public class PhantomReadExample {
private Connection conn;
public void accountStatistics() {
try {
conn.setAutoCommit(false);
// 第一次查询账户数量
int count1 = getAccountCount();
System.out.println("第一次查询账户数量: " + count1);
// 在此期间,另一个事务创建了新账户并提交
// 第二次查询账户数量
int count2 = getAccountCount();
System.out.println("第二次查询账户数量: " + count2);
// 两次查询结果不一致 - 幻读
if (count1 != count2) {
System.out.println("检测到幻读!");
}
conn.commit();
} catch (SQLException e) {
// 处理异常
}
}
private int getAccountCount() throws SQLException {
String sql = "SELECT COUNT(*) as count FROM accounts";
Statement stmt = conn.createStatement();
ResultSet rs = stmt.executeQuery(sql);
return rs.next() ? rs.getInt("count") : 0;
}
}传统事务隔离级别详解
SQL标准定义了四个事务隔离级别,用于解决上述并发问题。让我们通过架构图来理解它们之间的关系。
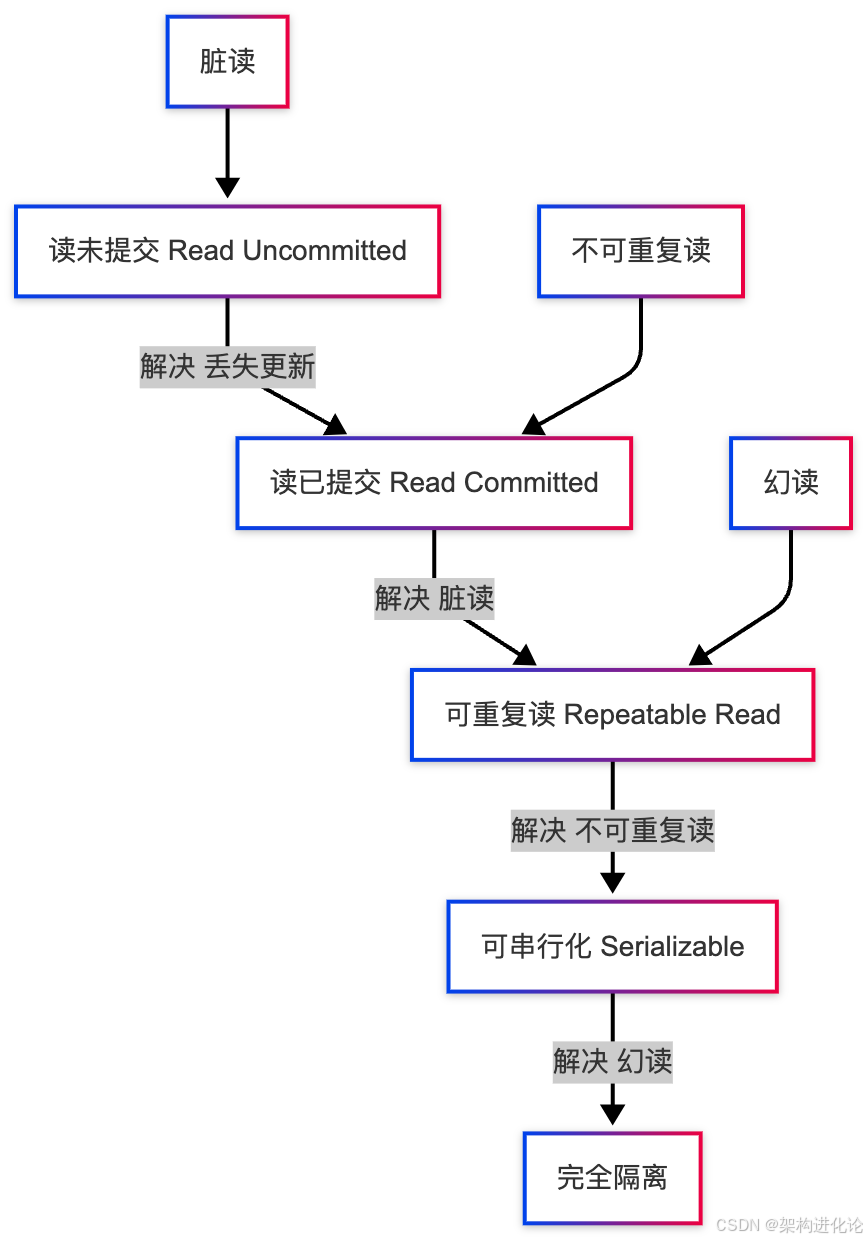
读未提交(Read Uncommitted)
这是最低的隔离级别,允许事务读取其他事务未提交的更改。
架构特点:
-
无读锁机制
-
最高并发性能
-
数据一致性最差
适用场景:
-
对数据准确性要求不高的统计场景
-
需要最高性能的只读查询
读已提交(Read Committed)
大多数数据库的默认隔离级别,只允许读取已提交的数据。
架构特点:
-
使用短期读锁
-
解决脏读问题
-
仍存在不可重复读和幻读
// 读已提交隔离级别示例
public class ReadCommittedExample {
public void readCommittedOperation() {
Connection conn = null;
try {
conn = dataSource.getConnection();
// 设置隔离级别为读已提交
conn.setTransactionIsolation(Connection.TRANSACTION_READ_COMMITTED);
conn.setAutoCommit(false);
// 第一次查询 - 只能看到已提交的数据
BigDecimal balance1 = getAccountBalance(conn, "account123");
// 即使其他事务在此修改了数据但未提交,这里的查询也不会看到
// 第二次查询 - 可能看到其他已提交事务的修改
BigDecimal balance2 = getAccountBalance(conn, "account123");
conn.commit();
} catch (SQLException e) {
// 处理异常
} finally {
// 关闭连接
}
}
}可重复读(Repeatable Read)
保证在同一个事务中多次读取同一数据的结果是一致的。
架构特点:
-
使用长期读锁
-
解决脏读和不可重复读
-
仍可能存在幻读
可串行化(Serializable)
最高的隔离级别,完全隔离事务,如同串行执行。
架构特点:
-
使用范围锁
-
解决所有并发问题
-
性能最低
现代数据库的创新隔离级别
传统的隔离级别在性能和一致性之间难以兼顾,这促使了新一代隔离级别的诞生。
快照隔离(Snapshot Isolation)
快照隔离通过多版本并发控制(MVCC)实现(扩展阅读:MVCC架构演进与创新设计:从并发冲突到多版本管理),每个事务看到的是数据库在某个时间点的快照。
架构原理:
-
为每个数据项维护多个版本
-
读操作不阻塞写操作
-
写操作不阻塞读操作
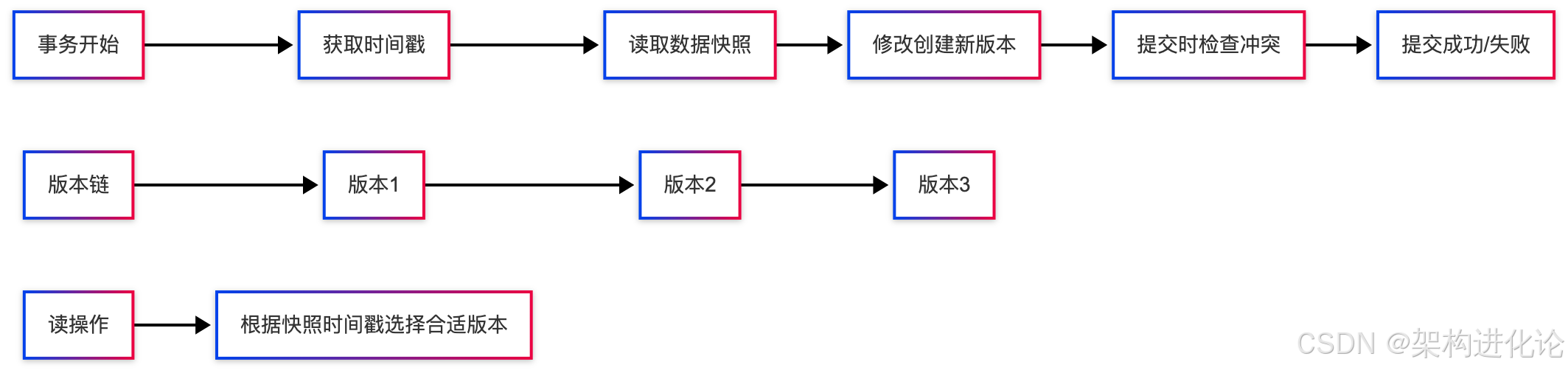
多版本并发控制(MVCC)深度解析
MVCC是现代数据库系统的核心技术,让我们通过代码示例来理解其实现原理。
// 简化的MVCC实现示例
public class MVCCDatabase {
// 数据版本存储
private Map<String, List<DataVersion>> dataVersions = new ConcurrentHashMap<>();
// 事务管理
private AtomicLong transactionIdGenerator = new AtomicLong(0);
public class DataVersion {
private long versionId; // 版本ID
private Object data; // 数据内容
private long createdTxId; // 创建该版本的事务ID
private long expiredTxId; // 使该版本过期的事务ID
public DataVersion(long versionId, Object data, long createdTxId) {
this.versionId = versionId;
this.data = data;
this.createdTxId = createdTxId;
this.expiredTxId = Long.MAX_VALUE; // 初始为未过期
}
// 检查该版本对指定事务是否可见
public boolean isVisibleTo(long transactionId) {
return createdTxId <= transactionId && expiredTxId > transactionId;
}
}
public class Transaction {
private long transactionId;
private long startTimestamp;
private boolean committed = false;
private Set<String> writeSet = new HashSet<>(); // 写入集合
public Transaction() {
this.transactionId = transactionIdGenerator.incrementAndGet();
this.startTimestamp = System.currentTimeMillis();
}
// 读取数据
public Object read(String key) {
List<DataVersion> versions = dataVersions.get(key);
if (versions == null) return null;
// 查找对当前事务可见的最新版本
for (int i = versions.size() - 1; i >= 0; i--) {
DataVersion version = versions.get(i);
if (version.isVisibleTo(this.transactionId)) {
return version.data;
}
}
return null;
}
// 写入数据
public void write(String key, Object data) {
writeSet.add(key);
List<DataVersion> versions = dataVersions.computeIfAbsent(key, k -> new ArrayList<>());
// 创建新版本
DataVersion newVersion = new DataVersion(
System.currentTimeMillis(), data, this.transactionId);
versions.add(newVersion);
}
// 提交事务
public boolean commit() {
// 检查写冲突
if (!checkWriteConflicts()) {
return false;
}
// 更新版本可见性
updateVersionVisibility();
this.committed = true;
return true;
}
private boolean checkWriteConflicts() {
// 实现写冲突检测逻辑
return true;
}
private void updateVersionVisibility() {
// 更新过期事务ID
for (String key : writeSet) {
List<DataVersion> versions = dataVersions.get(key);
if (versions != null && versions.size() >= 2) {
// 设置前一个版本过期
DataVersion previousVersion = versions.get(versions.size() - 2);
previousVersion.expiredTxId = this.transactionId;
}
}
}
}
}写倾斜与更新丢失的解决方案
即使使用MVCC,仍然存在写倾斜和更新丢失的问题。让我们探讨现代解决方案。
乐观锁机制
// 乐观锁实现示例
public class OptimisticLockExample {
public boolean transferWithOptimisticLock(String fromAccount, String toAccount,
BigDecimal amount) {
Connection conn = null;
try {
conn = dataSource.getConnection();
conn.setAutoCommit(false);
// 读取账户信息,包括版本号
String querySql = "SELECT balance, version FROM accounts WHERE account_id = ?";
// 读取转出账户
PreparedStatement queryStmt1 = conn.prepareStatement(querySql);
queryStmt1.setString(1, fromAccount);
ResultSet rs1 = queryStmt1.executeQuery();
rs1.next();
BigDecimal fromBalance = rs1.getBigDecimal("balance");
int fromVersion = rs1.getInt("version");
// 读取转入账户
PreparedStatement queryStmt2 = conn.prepareStatement(querySql);
queryStmt2.setString(1, toAccount);
ResultSet rs2 = queryStmt2.executeQuery();
rs2.next();
BigDecimal toBalance = rs2.getBigDecimal("balance");
int toVersion = rs2.getInt("version");
// 检查余额是否足够
if (fromBalance.compareTo(amount) < 0) {
conn.rollback();
return false;
}
// 更新转出账户(带版本检查)
String updateSql = "UPDATE accounts SET balance = balance - ?, version = version + 1 " +
"WHERE account_id = ? AND version = ?";
PreparedStatement updateStmt1 = conn.prepareStatement(updateSql);
updateStmt1.setBigDecimal(1, amount);
updateStmt1.setString(2, fromAccount);
updateStmt1.setInt(3, fromVersion);
int affectedRows1 = updateStmt1.executeUpdate();
// 更新转入账户(带版本检查)
PreparedStatement updateStmt2 = conn.prepareStatement(updateSql);
updateStmt2.setBigDecimal(1, amount);
updateStmt2.setString(2, toAccount);
updateStmt2.setInt(3, toVersion);
int affectedRows2 = updateStmt2.executeUpdate();
// 检查是否更新成功
if (affectedRows1 == 1 && affectedRows2 == 1) {
conn.commit();
return true;
} else {
conn.rollback();
return false; // 版本冲突,需要重试
}
} catch (SQLException e) {
// 处理异常
try { if (conn != null) conn.rollback(); } catch (SQLException ex) {}
return false;
} finally {
// 关闭连接
}
}
}分布式事务隔离的创新设计
在微服务和分布式架构成为主流的今天,事务隔离面临着新的挑战。让我们探讨分布式环境下的创新解决方案。
分布式事务的挑战
在分布式系统中,传统的事务隔离机制面临以下挑战:
-
网络分区和延迟
-
时钟不同步
-
节点故障
-
数据分片
全局时钟与时间戳排序
// 基于时间戳的分布式事务排序
public class TimestampOrderingCoordinator {
private VectorClock vectorClock = new VectorClock();
private Map<String, Transaction> pendingTransactions = new ConcurrentHashMap<>();
public class DistributedTransaction {
private String transactionId;
private long timestamp;
private Map<String, Object> readSet = new HashMap<>();
private Map<String, Object> writeSet = new HashMap<>();
private TransactionStatus status = TransactionStatus.PENDING;
public boolean validate() {
// 验证读写冲突
for (String key : readSet.keySet()) {
DataVersion latestVersion = getLatestCommittedVersion(key);
if (latestVersion.getTimestamp() > this.timestamp) {
return false; // 存在冲突
}
}
return true;
}
}
public boolean commitTransaction(DistributedTransaction transaction) {
synchronized (this) {
// 获取全局时间戳
long commitTimestamp = vectorClock.getNextTimestamp();
transaction.setTimestamp(commitTimestamp);
// 验证事务
if (!transaction.validate()) {
return false; // 验证失败,中止事务
}
// 执行提交
return doCommit(transaction);
}
}
}两阶段提交与Paxos协议
在分布式系统中,确保所有节点对事务提交达成一致是关键技术挑战。
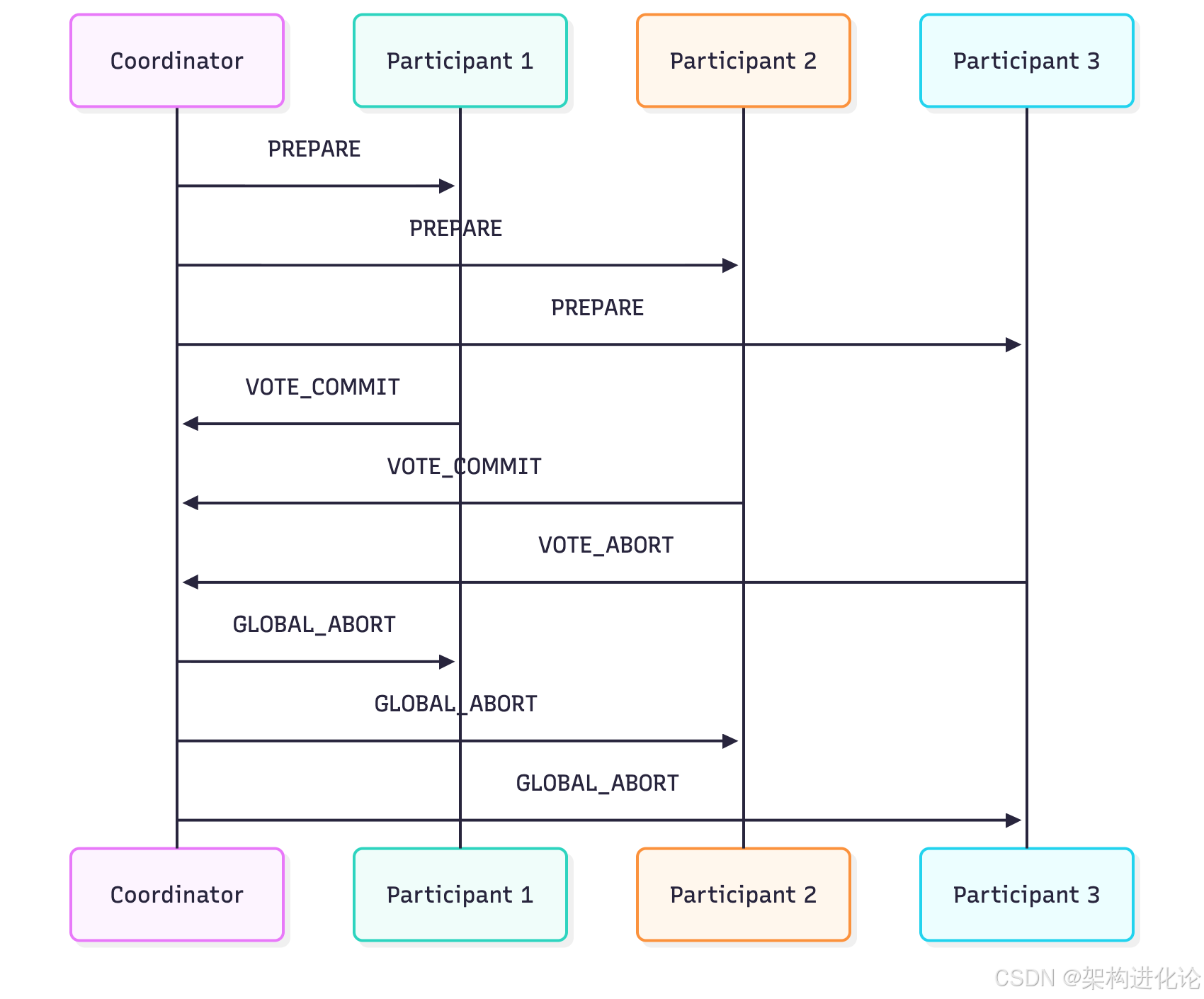
新一代混合隔离级别设计
基于对传统和现代隔离级别的深入分析,我们提出一种创新的混合隔离级别设计。
自适应隔离级别
// 自适应隔离级别管理器
public class AdaptiveIsolationManager {
private Map<IsolationContext, IsolationLevel> isolationCache = new ConcurrentHashMap<>();
public enum IsolationContext {
HIGH_CONCURRENCY_READ,
CONSISTENT_READ,
CRITICAL_WRITE,
ANALYTICAL_QUERY
}
public IsolationLevel determineAppropriateLevel(IsolationContext context,
WorkloadCharacteristics workload) {
// 基于上下文和工作负载特征动态选择隔离级别
switch (context) {
case HIGH_CONCURRENCY_READ:
return workload.isLowConflict() ?
IsolationLevel.READ_COMMITTED : IsolationLevel.REPEATABLE_READ;
case CONSISTENT_READ:
return workload.isReadHeavy() ?
IsolationLevel.SNAPSHOT_ISOLATION : IsolationLevel.REPEATABLE_READ;
case CRITICAL_WRITE:
return IsolationLevel.SERIALIZABLE;
case ANALYTICAL_QUERY:
return IsolationLevel.READ_UNCOMMITTED;
default:
return IsolationLevel.READ_COMMITTED;
}
}
public void monitorAndAdjust() {
// 监控系统性能和数据一致性,动态调整隔离级别
// 基于机器学习算法优化隔离级别选择
}
}基于机器学习的智能隔离
// 基于机器学习的隔离级别优化
public class MLIsolationOptimizer {
private IsolationModel predictionModel;
private FeatureExtractor featureExtractor;
public class IsolationFeatures {
private double conflictProbability;
private double readWriteRatio;
private double transactionLength;
private double dataHotspotFactor;
private double systemLoad;
}
public IsolationLevel predictOptimalLevel(IsolationFeatures features) {
// 使用训练好的模型预测最优隔离级别
return predictionModel.predict(features);
}
public void trainModel(List<TrainingExample> examples) {
// 基于历史性能数据训练模型
// 特征:工作负载特征
// 标签:实际表现最好的隔离级别
}
}实际应用案例与性能优化
电商平台事务隔离实践
让我们通过一个完整的电商案例来展示事务隔离级别的实际应用。
// 电商订单处理系统
public class OrderProcessingService {
private DataSource dataSource;
private AdaptiveIsolationManager isolationManager;
public OrderResult processOrder(OrderRequest request) {
Connection conn = null;
try {
conn = dataSource.getConnection();
// 根据业务上下文选择隔离级别
IsolationLevel level = isolationManager.determineAppropriateLevel(
IsolationContext.CRITICAL_WRITE, getCurrentWorkload());
conn.setTransactionIsolation(level.getJdbcLevel());
conn.setAutoCommit(false);
// 1. 检查库存
if (!checkInventory(conn, request.getItems())) {
conn.rollback();
return OrderResult.outOfStock();
}
// 2. 扣减库存
if (!reduceInventory(conn, request.getItems())) {
conn.rollback();
return OrderResult.inventoryConflict();
}
// 3. 创建订单
String orderId = createOrder(conn, request);
// 4. 处理支付
PaymentResult paymentResult = processPayment(conn, request, orderId);
if (!paymentResult.isSuccess()) {
conn.rollback();
return OrderResult.paymentFailed();
}
conn.commit();
return OrderResult.success(orderId);
} catch (SQLException e) {
// 处理异常和重试逻辑
try { if (conn != null) conn.rollback(); } catch (SQLException ex) {}
return handleOrderException(e);
} finally {
// 关闭连接
}
}
// 库存检查与扣减的详细实现
private boolean reduceInventory(Connection conn, List<OrderItem> items)
throws SQLException {
for (OrderItem item : items) {
// 使用乐观锁防止超卖
String sql = "UPDATE inventory SET quantity = quantity - ?, version = version + 1 " +
"WHERE product_id = ? AND quantity >= ? AND version = ?";
PreparedStatement stmt = conn.prepareStatement(sql);
stmt.setInt(1, item.getQuantity());
stmt.setString(2, item.getProductId());
stmt.setInt(3, item.getQuantity());
stmt.setInt(4, item.getVersion());
int affectedRows = stmt.executeUpdate();
if (affectedRows == 0) {
return false; // 库存不足或版本冲突
}
}
return true;
}
}性能监控与调优
建立完善的监控体系对于事务隔离级别的优化至关重要。
// 事务性能监控
public class TransactionMonitor {
private MetricsRegistry metrics = new MetricsRegistry();
public void monitorTransaction(TransactionInfo info) {
// 记录事务指标
metrics.counter("transactions.total").inc();
metrics.timer("transaction.duration").update(info.getDuration());
metrics.histogram("transaction.retries").update(info.getRetryCount());
// 隔离级别相关指标
metrics.counter("isolation.level." + info.getIsolationLevel()).inc();
if (info.hasConflicts()) {
metrics.counter("transactions.conflicts").inc();
}
// 基于监控数据动态调整策略
adjustIsolationStrategyBasedOnMetrics();
}
private void adjustIsolationStrategyBasedOnMetrics() {
double conflictRate = metrics.meter("transactions.conflicts").getFifteenMinuteRate();
double throughput = metrics.meter("transactions.committed").getFifteenMinuteRate();
if (conflictRate > 0.1) { // 冲突率超过10%
// 考虑提高隔离级别或优化业务逻辑
alertHighConflictRate(conflictRate);
}
if (throughput < 1000) { // 吞吐量过低
// 考虑降低隔离级别或优化索引
alertLowThroughput(throughput);
}
}
}未来发展趋势与展望
新硬件环境下的事务处理
随着新硬件技术的发展,事务隔离级别设计面临着新的机遇和挑战:
持久内存(PMEM)的影响:
-
减少日志开销
-
加速恢复过程
-
新的并发控制算法
RDMA网络:
-
减少分布式事务的网络开销
-
新的分布式共识算法
-
跨节点内存访问
人工智能驱动的事务优化
未来,AI技术将在事务优化中发挥越来越重要的作用:
// AI驱动的事务优化器
public class AITransactionOptimizer {
private ReinforcementLearningAgent rlAgent;
private TransactionWorkloadAnalyzer workloadAnalyzer;
public IsolationPolicy learnOptimalPolicy(WorkloadHistory history) {
// 使用强化学习学习最优的隔离级别策略
return rlAgent.learn(history);
}
public RealTimeAdjustment getRealTimeAdjustment(CurrentWorkload workload) {
// 基于当前工作负载实时调整事务策略
return rlAgent.getAction(workload.toState());
}
}区块链技术与事务隔离
区块链技术为事务隔离提供了新的思路:
-
不可变的数据版本历史
-
基于共识的冲突解决
-
去中心化的事务验证
结论
事务隔离级别的设计是数据库系统架构中的核心挑战,需要在数据一致性和系统性能之间找到最佳平衡点。从传统的基于锁的隔离级别,到现代的MVCC机制,再到分布式的创新解决方案,事务隔离技术一直在不断演进。
作为架构师,我们需要深入理解不同隔离级别的特性和适用场景,根据具体的业务需求和工作负载特征,选择合适的隔离策略。同时,要密切关注新技术发展,如持久内存、RDMA、AI优化等,这些技术将为事务处理带来新的突破。
未来的事务隔离设计将更加智能化、自适应化和细粒度化,能够根据实时工作负载动态调整策略,在保证数据一致性的同时最大化系统性能。这需要我们不断学习、实践和创新,才能在复杂多变的互联网应用场景中设计出优秀的事务处理架构。
事务隔离不是银弹,而是需要在理解业务、理解数据、理解系统的基础上做出的权衡决策。希望本文能够为您在这个重要领域的学习和实践提供有价值的参考和启发。



















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











