




在当今的互联网时代,分布式系统已成为支撑各类在线服务的基石。从电商平台的秒杀活动到金融系统的交易处理,从社交媒体的实时推送到物联网的海量数据处理,无不依赖于稳定可靠的分布式系统。然而,分布式系统面临着一个根本性挑战:如何在多个独立的节点之间维持数据的一致性?
想象这样一个场景:你在电商平台购买商品时,库存显示仅剩1件。如果同时有多个用户发起购买请求,而系统无法保证库存数据的一致性,就可能导致超卖现象——多个用户都成功下单,但实际库存无法满足所有订单。这种数据不一致的情况会严重影响用户体验和平台信誉。
分布式一致性正是为了解决这类问题而诞生的核心技术。本文将深入探讨分布式一致性的演进历程、核心算法原理,并通过生活化案例和代码示例,揭示现代分布式系统如何实现高效可靠的一致性保障。
分布式一致性的基础理论
一致性的定义与分类
在分布式系统中,一致性指的是多个数据副本之间保持相同状态的特性。根据严格程度的不同,一致性可以分为多个级别:
-
强一致性:任何读写操作都能看到最新写入的数据
-
弱一致性:系统不保证立即看到最新写入的数据
-
最终一致性:保证如果没有新的更新,最终所有访问都将返回最后更新的值
CAP理论的启示
CAP理论由Eric Brewer提出,指出分布式系统最多只能同时满足一致性(Consistency)、可用性(Availability)和分区容错性(Partition tolerance)这三个特性中的两个。(扩展阅读:分布式系统数据一致性演进:从ACID到BASE的理论突破与实践创新、高可用系统架构设计实践:从设计到运营的全方位保障)
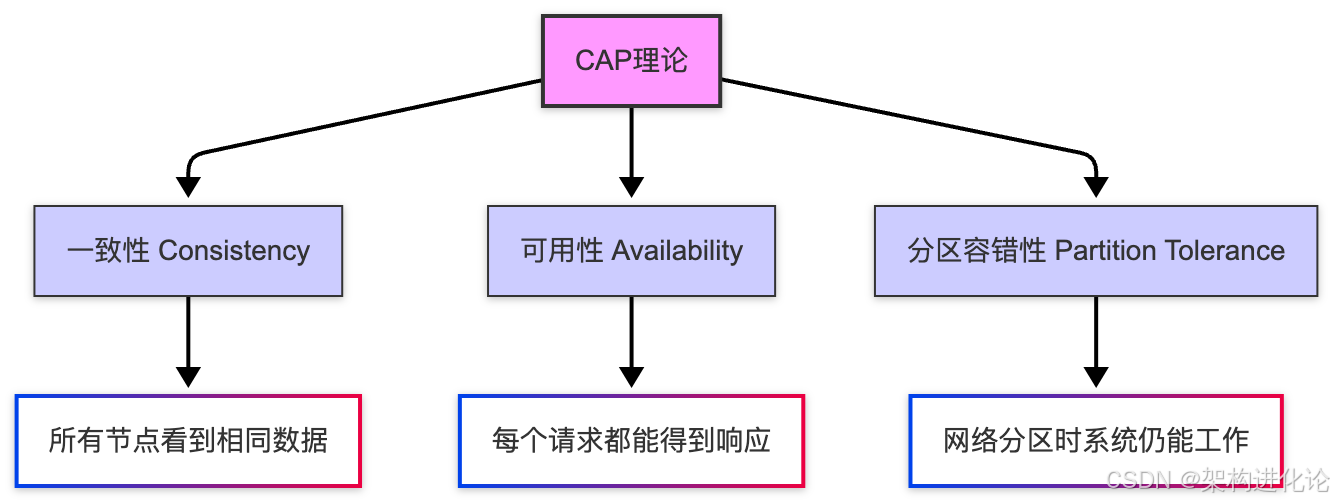
在实际系统设计中,由于网络分区不可避免,我们必须在一致性和可用性之间做出权衡。这一认识催生了多种不同的一致性算法和架构模式。
传统分布式一致性算法的演进
两阶段提交(2PC):早期的一致性尝试
两阶段提交是最早的分布式一致性协议之一,它通过协调者(Coordinator)和参与者(Participant)的交互来保证事务的原子性。
/**
* 两阶段提交协议示例
* 模拟分布式事务提交过程
*/
public class TwoPhaseCommit {
// 第一阶段:准备阶段
public boolean preparePhase(List<Participant> participants, Transaction transaction) {
List<Boolean> prepareResults = new ArrayList<>();
for (Participant participant : participants) {
try {
// 向每个参与者发送准备请求
boolean canCommit = participant.prepare(transaction);
prepareResults.add(canCommit);
} catch (Exception e) {
// 如果任何参与者准备失败,记录失败
prepareResults.add(false);
}
}
// 检查所有参与者是否都准备就绪
return prepareResults.stream().allMatch(result -> result);
}
// 第二阶段:提交阶段
public void commitPhase(List<Participant> participants,
Transaction transaction,
boolean shouldCommit) {
for (Participant participant : participants) {
try {
if (shouldCommit) {
participant.commit(transaction);
} else {
participant.rollback(transaction);
}
} catch (Exception e) {
// 处理提交/回滚失败的情况
System.err.println("操作失败: " + e.getMessage());
}
}
}
// 执行两阶段提交
public void executeTransaction(List<Participant> participants,
Transaction transaction) {
// 第一阶段:准备
boolean allPrepared = preparePhase(participants, transaction);
// 第二阶段:根据准备结果决定提交或回滚
commitPhase(participants, transaction, allPrepared);
}
}
/**
* 参与者接口定义
*/
interface Participant {
boolean prepare(Transaction transaction);
void commit(Transaction transaction);
void rollback(Transaction transaction);
}2PC的局限性:
-
同步阻塞:在准备阶段,所有参与者都需要等待其他节点的响应
-
单点故障:协调者故障会导致整个系统阻塞
-
数据不一致:在特定故障场景下可能产生数据不一致
Paxos算法:理论上的突破
Leslie Lamport提出的Paxos算法是分布式一致性领域的里程碑。它通过提案、承诺和接受三个阶段,在异步网络中实现了共识。
/**
* Paxos算法简化实现
* 包含提案者、接受者和学习者三种角色
*/
public class PaxosAlgorithm {
private String currentValue = null;
private long promisedId = 0L;
private long acceptedId = 0L;
private String acceptedValue = null;
/**
* 准备阶段:提案者向接受者发送准备请求
* @param proposalId 提案ID
* @return 是否承诺接受该提案
*/
public synchronized boolean prepare(long proposalId) {
if (proposalId > promisedId) {
promisedId = proposalId;
return true;
}
return false;
}
/**
* 接受阶段:提案者发送接受请求
* @param proposalId 提案ID
* @param value 提案值
* @return 是否接受该提案
*/
public synchronized boolean accept(long proposalId, String value) {
if (proposalId >= promisedId) {
promisedId = proposalId;
acceptedId = proposalId;
acceptedValue = value;
return true;
}
return false;
}
/**
* 学习阶段:学习者获取已接受的提案
* @return 已接受的提案值
*/
public synchronized String learn() {
return acceptedValue;
}
}
/**
* Paxos提案者实现
*/
class Proposer {
private List<PaxosAlgorithm> acceptors;
private long proposalId;
public Proposer(List<PaxosAlgorithm> acceptors) {
this.acceptors = acceptors;
this.proposalId = System.currentTimeMillis();
}
public String propose(String value) {
int retryCount = 0;
while (retryCount < 3) { // 最多重试3次
// 阶段1:准备请求
int promiseCount = 0;
for (PaxosAlgorithm acceptor : acceptors) {
if (acceptor.prepare(proposalId)) {
promiseCount++;
}
}
// 如果获得多数派承诺,进入阶段2
if (promiseCount > acceptors.size() / 2) {
int acceptCount = 0;
for (PaxosAlgorithm acceptor : acceptors) {
if (acceptor.accept(proposalId, value)) {
acceptCount++;
}
}
// 如果获得多数派接受,提案成功
if (acceptCount > acceptors.size() / 2) {
return value;
}
}
// 增加提案ID并重试
proposalId++;
retryCount++;
}
throw new RuntimeException("无法达成共识");
}
}Raft算法:可理解性的突破
由于Paxos算法难以理解和实现,Diego Ongaro和John Ousterhout提出了Raft算法,通过分解问题、减少状态空间来提高可理解性。
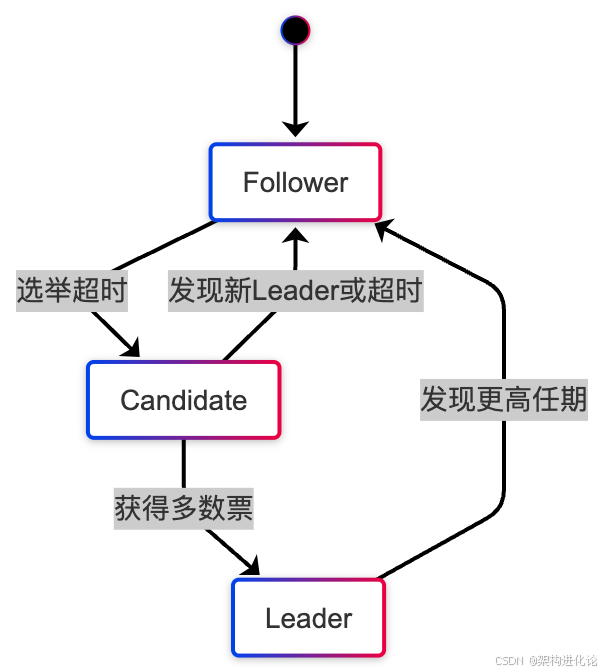
现代分布式一致性架构的创新设计
基于Raft的分布式键值存储系统
让我们通过一个具体的例子来理解现代分布式一致性架构的设计思路。我们将构建一个基于Raft的分布式键值存储系统。
/**
* Raft节点状态机
* 管理节点的状态转换和日志复制
*/
public class RaftNode {
// 节点状态
public enum State {
FOLLOWER, CANDIDATE, LEADER
}
private State state = State.FOLLOWER;
private long currentTerm = 0L;
private String votedFor = null;
private List<LogEntry> log = new ArrayList<>();
private long commitIndex = 0L;
private long lastApplied = 0L;
// 领导者需要维护的易失性状态
private Map<String, Long> nextIndex = new HashMap<>();
private Map<String, Long> matchIndex = new HashMap<>();
private String nodeId;
private List<String> peerNodes;
private volatile long lastHeartbeatTime = System.currentTimeMillis();
public RaftNode(String nodeId, List<String> peerNodes) {
this.nodeId = nodeId;
this.peerNodes = peerNodes;
}
/**
* 处理请求投票RPC
*/
public synchronized VoteResult requestVote(VoteRequest request) {
// 如果请求的任期小于当前任期,拒绝投票
if (request.getTerm() < currentTerm) {
return new VoteResult(currentTerm, false);
}
// 如果请求的任期更大,转换为追随者
if (request.getTerm() > currentTerm) {
currentTerm = request.getTerm();
state = State.FOLLOWER;
votedFor = null;
}
// 检查日志是否至少一样新
boolean logIsOk = request.getLastLogTerm() > getLastLogTerm() ||
(request.getLastLogTerm() == getLastLogTerm() &&
request.getLastLogIndex() >= getLastLogIndex());
// 如果还没有投票且日志足够新,则投票
if ((votedFor == null || votedFor.equals(request.getCandidateId())) && logIsOk) {
votedFor = request.getCandidateId();
return new VoteResult(currentTerm, true);
}
return new VoteResult(currentTerm, false);
}
/**
* 处理追加条目RPC(心跳和日志复制)
*/
public synchronized AppendEntriesResult appendEntries(AppendEntriesRequest request) {
// 重置心跳计时器
lastHeartbeatTime = System.currentTimeMillis();
// 如果请求任期小于当前任期,拒绝
if (request.getTerm() < currentTerm) {
return new AppendEntriesResult(currentTerm, false);
}
// 如果请求任期更大,转换为追随者
if (request.getTerm() > currentTerm) {
currentTerm = request.getTerm();
state = State.FOLLOWER;
votedFor = null;
}
// 检查日志一致性
if (request.getPrevLogIndex() >= log.size() ||
(request.getPrevLogIndex() >= 0 &&
log.get((int)request.getPrevLogIndex()).getTerm() != request.getPrevLogTerm())) {
return new AppendEntriesResult(currentTerm, false);
}
// 追加新条目
if (request.getEntries() != null && !request.getEntries().isEmpty()) {
// 删除冲突的条目
int index = (int) request.getPrevLogIndex() + 1;
for (LogEntry entry : request.getEntries()) {
if (index < log.size()) {
if (log.get(index).getTerm() != entry.getTerm()) {
// 删除从这个位置开始的所有条目
log = new ArrayList<>(log.subList(0, index));
}
}
if (index >= log.size()) {
log.add(entry);
}
index++;
}
}
// 更新提交索引
if (request.getLeaderCommit() > commitIndex) {
commitIndex = Math.min(request.getLeaderCommit(), log.size() - 1);
// 应用已提交的日志条目
applyCommittedEntries();
}
return new AppendEntriesResult(currentTerm, true);
}
/**
* 启动选举超时检测
*/
public void startElectionTimeout() {
Thread electionThread = new Thread(() -> {
Random random = new Random();
while (true) {
try {
// 随机选举超时时间(150-300ms)
long timeout = 150 + random.nextInt(150);
Thread.sleep(timeout);
synchronized (this) {
long now = System.currentTimeMillis();
// 如果超过选举超时时间没有收到心跳,开始选举
if (now - lastHeartbeatTime > timeout && state != State.LEADER) {
startElection();
}
}
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
break;
}
}
});
electionThread.setDaemon(true);
electionThread.start();
}
/**
* 开始领导者选举
*/
private void startElection() {
state = State.CANDIDATE;
currentTerm++;
votedFor = nodeId;
// 向其他节点请求投票
int voteCount = 1; // 自己的一票
VoteRequest request = new VoteRequest(currentTerm, nodeId,
getLastLogIndex(), getLastLogTerm());
for (String peer : peerNodes) {
// 异步发送投票请求
sendVoteRequest(peer, request, result -> {
synchronized (RaftNode.this) {
if (result.isVoteGranted() && state == State.CANDIDATE) {
voteCount++;
// 如果获得多数票,成为领导者
if (voteCount > (peerNodes.size() + 1) / 2) {
becomeLeader();
}
}
}
});
}
}
/**
* 转换为领导者状态
*/
private void becomeLeader() {
state = State.LEADER;
// 初始化nextIndex和matchIndex
for (String peer : peerNodes) {
nextIndex.put(peer, (long) log.size());
matchIndex.put(peer, 0L);
}
// 开始发送心跳
startHeartbeat();
}
/**
* 启动心跳机制
*/
private void startHeartbeat() {
Thread heartbeatThread = new Thread(() -> {
while (state == State.LEADER) {
try {
// 向所有追随者发送心跳
for (String peer : peerNodes) {
sendHeartbeat(peer);
}
Thread.sleep(50); // 每50ms发送一次心跳
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
break;
}
}
});
heartbeatThread.setDaemon(true);
heartbeatThread.start();
}
// 其他辅助方法...
private long getLastLogIndex() {
return log.isEmpty() ? 0 : log.size() - 1;
}
private long getLastLogTerm() {
return log.isEmpty() ? 0 : log.get(log.size() - 1).getTerm();
}
private void applyCommittedEntries() {
while (lastApplied < commitIndex) {
lastApplied++;
LogEntry entry = log.get((int) lastApplied);
// 应用状态机
applyToStateMachine(entry);
}
}
private void applyToStateMachine(LogEntry entry) {
// 将日志条目应用到状态机
// 在实际系统中,这会更新键值存储等
}
}
/**
* 日志条目类
*/
class LogEntry {
private long term;
private String command;
public LogEntry(long term, String command) {
this.term = term;
this.command = command;
}
// getter和setter方法...
}
/**
* 投票请求和响应类
*/
class VoteRequest {
private long term;
private String candidateId;
private long lastLogIndex;
private long lastLogTerm;
// 构造函数、getter和setter...
}
class VoteResult {
private long term;
private boolean voteGranted;
// 构造函数、getter和setter...
}分布式键值存储的实现
基于上述Raft实现,我们可以构建一个完整的分布式键值存储系统:
/**
* 分布式键值存储服务
* 基于Raft共识算法保证一致性
*/
public class DistributedKVStore {
private RaftNode raftNode;
private Map<String, String> kvStore = new HashMap<>();
public DistributedKVStore(String nodeId, List<String> peerNodes) {
this.raftNode = new RaftNode(nodeId, peerNodes);
this.raftNode.startElectionTimeout();
}
/**
* 写入键值对
* 只有领导者可以处理写请求
*/
public boolean put(String key, String value) {
// 检查当前节点是否是领导者
if (!raftNode.isLeader()) {
// 如果不是领导者,可以将请求重定向到领导者
throw new NotLeaderException("当前节点不是领导者");
}
// 创建日志条目
String command = String.format("PUT %s %s", key, value);
LogEntry entry = new LogEntry(raftNode.getCurrentTerm(), command);
// 将条目复制到大多数节点
boolean success = raftNode.replicateEntry(entry);
if (success) {
// 提交后应用到状态机
kvStore.put(key, value);
}
return success;
}
/**
* 读取键值对
* 为了线性一致性,领导者需要验证自己仍然是领导者
*/
public String get(String key) {
// 对于读操作,也需要确保线性一致性
if (raftNode.isLeader()) {
// 领导者需要确认自己仍然是领导者
if (!raftNode.verifyLeadership()) {
throw new NotLeaderException("当前节点不再是领导者");
}
} else {
throw new NotLeaderException("当前节点不是领导者");
}
return kvStore.get(key);
}
/**
* 处理客户端请求
*/
public String handleRequest(String request) {
String[] parts = request.split(" ");
String operation = parts[0];
try {
switch (operation) {
case "GET":
if (parts.length < 2) {
return "ERROR: 缺少键";
}
String value = get(parts[1]);
return value != null ? value : "NULL";
case "PUT":
if (parts.length < 3) {
return "ERROR: 缺少键或值";
}
boolean success = put(parts[1], parts[2]);
return success ? "OK" : "ERROR: 操作失败";
default:
return "ERROR: 不支持的操作";
}
} catch (NotLeaderException e) {
return "REDIRECT " + raftNode.getLeaderAddress();
}
}
}创新的一致性架构模式
多Raft组架构
为了提升系统的可扩展性,现代分布式系统通常采用多Raft组架构,将数据分片到多个Raft组中。
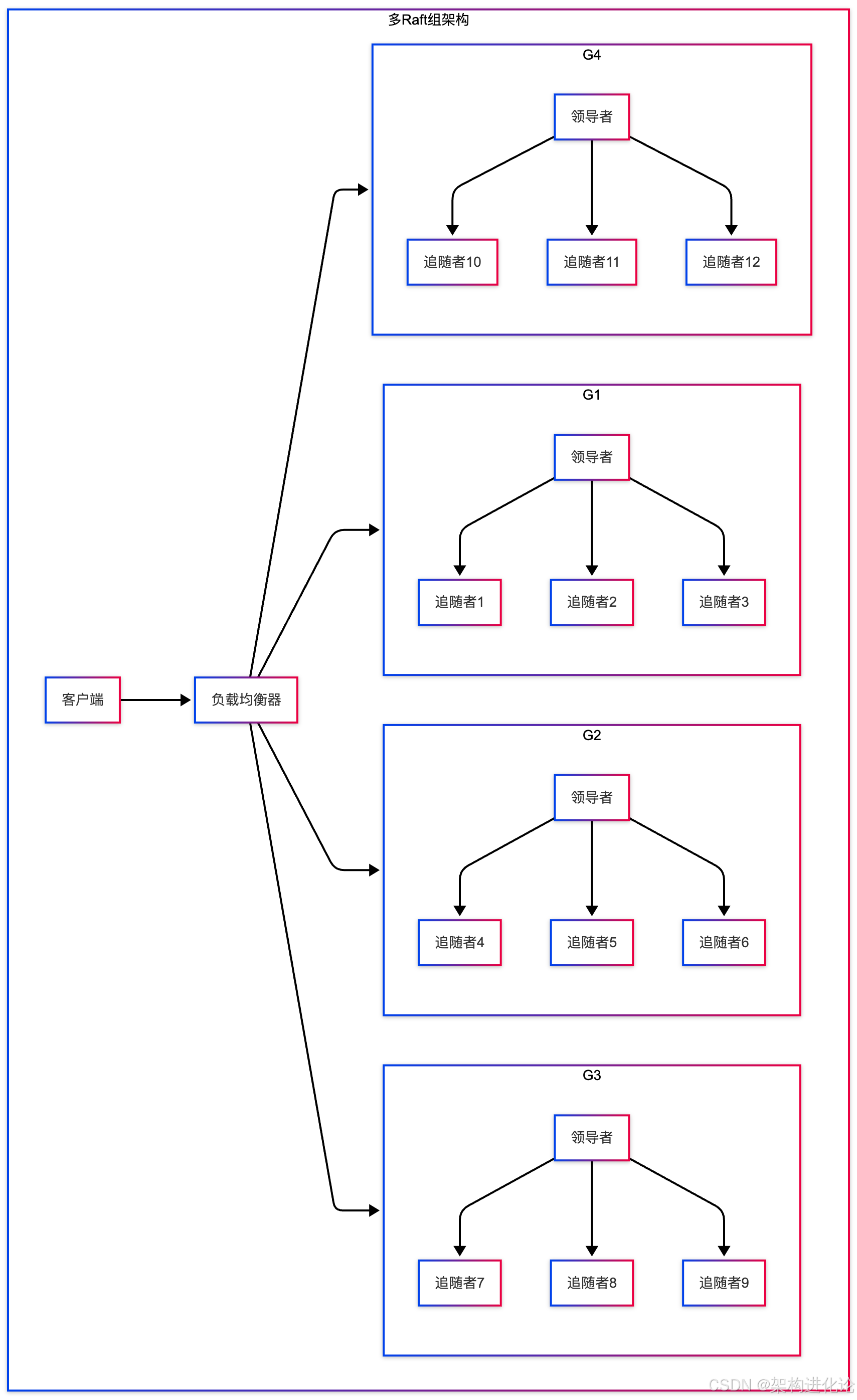
基于时钟的乐观并发控制
在某些场景下,我们可以使用基于时钟的乐观并发控制来提升性能,同时保证一定程度的一致性。
/**
* 基于向量时钟的版本控制
* 用于检测并发更新冲突
*/
public class VectorClock {
private final Map<String, Long> clocks;
public VectorClock() {
this.clocks = new HashMap<>();
}
public VectorClock(Map<String, Long> initialClocks) {
this.clocks = new HashMap<>(initialClocks);
}
/**
* 递增指定节点的时钟
*/
public VectorClock increment(String nodeId) {
Map<String, Long> newClocks = new HashMap<>(clocks);
newClocks.put(nodeId, clocks.getOrDefault(nodeId, 0L) + 1);
return new VectorClock(newClocks);
}
/**
* 比较两个向量时钟的关系
* @return 1: this > other, -1: this < other, 0: 并发冲突
*/
public int compareTo(VectorClock other) {
boolean thisGreater = false;
boolean otherGreater = false;
// 收集所有涉及的节点
Set<String> allNodes = new HashSet<>();
allNodes.addAll(this.clocks.keySet());
allNodes.addAll(other.clocks.keySet());
for (String node : allNodes) {
long thisTime = this.clocks.getOrDefault(node, 0L);
long otherTime = other.clocks.getOrDefault(node, 0L);
if (thisTime > otherTime) {
thisGreater = true;
} else if (thisTime < otherTime) {
otherGreater = true;
}
}
if (thisGreater && !otherGreater) {
return 1; // this > other
} else if (!thisGreater && otherGreater) {
return -1; // this < other
} else if (thisGreater && otherGreater) {
return 0; // 并发冲突
} else {
return 1; // 相等,认为this >= other
}
}
/**
* 解决冲突 - 使用应用特定的逻辑
*/
public static <T> T resolveConflict(T value1, VectorClock clock1,
T value2, VectorClock clock2) {
int comparison = clock1.compareTo(clock2);
if (comparison >= 0) {
// clock1 >= clock2,选择value1
return value1;
} else {
// clock1 < clock2,选择value2
return value2;
}
}
}
/**
* 带版本控制的键值存储
*/
public class VersionedKVStore {
private Map<String, VersionedValue> store = new HashMap<>();
public static class VersionedValue {
private final String value;
private final VectorClock clock;
public VersionedValue(String value, VectorClock clock) {
this.value = value;
this.clock = clock;
}
// getter方法...
}
/**
* 写入键值对,处理可能的冲突
*/
public void put(String key, String value, VectorClock clientClock) {
VersionedValue current = store.get(key);
if (current == null) {
// 新键,直接写入
store.put(key, new VersionedValue(value, clientClock));
} else {
// 检查冲突
int comparison = clientClock.compareTo(current.clock);
if (comparison >= 0) {
// 没有冲突或客户端时钟更新,接受写入
store.put(key, new VersionedValue(value, clientClock));
} else {
// 检测到冲突,需要解决
// 在实际系统中,这里可能会调用应用特定的冲突解决逻辑
System.out.println("检测到写冲突,键: " + key);
// 简单的解决策略:选择时钟更新的值
// 更复杂的系统可能提供应用层回调来处理冲突
if (comparison < 0) {
// 服务端数据更新,拒绝写入
throw new ConflictException("写入冲突,服务端有更新的数据");
}
}
}
}
/**
* 读取键值对及其版本信息
*/
public VersionedValue get(String key) {
return store.get(key);
}
}实际应用案例与性能优化
电商库存管理的一致性保障
让我们回到文章开头提到的电商库存问题,看看如何用分布式一致性技术解决它。
/**
* 分布式库存管理系统
* 使用Raft保证库存数据的一致性
*/
public class DistributedInventory {
private DistributedKVStore kvStore;
public DistributedInventory(String nodeId, List<String> peerNodes) {
this.kvStore = new DistributedKVStore(nodeId, peerNodes);
}
/**
* 扣减库存
* 使用分布式事务保证一致性
*/
public boolean deductInventory(String productId, int quantity) {
// 构建库存键
String inventoryKey = "inventory:" + productId;
try {
// 读取当前库存
String currentStr = kvStore.get(inventoryKey);
int currentInventory = currentStr != null ? Integer.parseInt(currentStr) : 0;
// 检查库存是否充足
if (currentInventory < quantity) {
return false; // 库存不足
}
// 扣减库存
int newInventory = currentInventory - quantity;
boolean success = kvStore.put(inventoryKey, String.valueOf(newInventory));
if (success) {
// 记录库存变更日志
String logKey = "inventory_log:" + System.currentTimeMillis();
String logValue = String.format("产品:%s, 扣减:%d, 剩余:%d",
productId, quantity, newInventory);
kvStore.put(logKey, logValue);
}
return success;
} catch (NumberFormatException e) {
System.err.println("库存数据格式错误: " + e.getMessage());
return false;
} catch (Exception e) {
System.err.println("扣减库存失败: " + e.getMessage());
return false;
}
}
/**
* 批量扣减库存
* 保证多个商品库存扣减的原子性
*/
public boolean batchDeductInventory(Map<String, Integer> inventoryMap) {
// 在实际系统中,这里需要实现分布式事务
// 可以使用两阶段提交或其他分布式事务协议
// 简化实现:逐个扣减,不保证原子性
for (Map.Entry<String, Integer> entry : inventoryMap.entrySet()) {
if (!deductInventory(entry.getKey(), entry.getValue())) {
// 如果任何一个扣减失败,需要回滚已扣减的库存
// 简化实现中直接返回失败
return false;
}
}
return true;
}
/**
* 查询库存
*/
public int queryInventory(String productId) {
try {
String inventoryKey = "inventory:" + productId;
String value = kvStore.get(inventoryKey);
return value != null ? Integer.parseInt(value) : 0;
} catch (NumberFormatException e) {
System.err.println("库存数据格式错误: " + e.getMessage());
return 0;
}
}
}性能优化策略
在实际生产环境中,分布式一致性系统需要各种优化来提升性能:
批量处理与流水线
/**
* 批量日志复制优化
* 减少RPC调用次数,提升吞吐量
*/
public class BatchReplicator {
private final RaftNode raftNode;
private final List<LogEntry> pendingEntries = new ArrayList<>();
private final int batchSize;
private final long batchTimeoutMs;
public BatchReplicator(RaftNode raftNode, int batchSize, long batchTimeoutMs) {
this.raftNode = raftNode;
this.batchSize = batchSize;
this.batchTimeoutMs = batchTimeoutMs;
}
/**
* 批量提交日志条目
*/
public CompletableFuture<Boolean> replicateBatch(List<LogEntry> entries) {
if (entries.isEmpty()) {
return CompletableFuture.completedFuture(true);
}
// 如果单一批次就很大,直接复制
if (entries.size() >= batchSize) {
return raftNode.replicateEntries(entries);
}
// 否则加入待处理队列
synchronized (pendingEntries) {
pendingEntries.addAll(entries);
// 如果达到批量大小,立即发送
if (pendingEntries.size() >= batchSize) {
List<LogEntry> toSend = new ArrayList<>(pendingEntries);
pendingEntries.clear();
return raftNode.replicateEntries(toSend);
}
}
// 设置超时发送
CompletableFuture<Boolean> future = new CompletableFuture<>();
scheduleBatchSend(future);
return future;
}
private void scheduleBatchSend(CompletableFuture<Boolean> future) {
new Thread(() -> {
try {
Thread.sleep(batchTimeoutMs);
List<LogEntry> toSend;
synchronized (pendingEntries) {
toSend = new ArrayList<>(pendingEntries);
pendingEntries.clear();
}
if (!toSend.isEmpty()) {
boolean result = raftNode.replicateEntries(toSend).get();
future.complete(result);
} else {
future.complete(true);
}
} catch (Exception e) {
future.completeExceptionally(e);
}
}).start();
}
}读写分离与一致性级别
/**
* 可调节的一致性级别
* 根据业务需求平衡一致性和性能
*/
public class TunableConsistency {
public enum ConsistencyLevel {
STRONG, // 强一致性,只从领导者读取
EVENTUAL, // 最终一致性,可以从任何节点读取
BOUNDED_STALENESS // 有限过期,允许读取稍旧的数据
}
private RaftNode raftNode;
public TunableConsistency(RaftNode raftNode) {
this.raftNode = raftNode;
}
/**
* 根据一致性级别读取数据
*/
public String read(String key, ConsistencyLevel level) {
switch (level) {
case STRONG:
// 强一致性:只从领导者读取
if (!raftNode.isLeader()) {
throw new NotLeaderException("强一致性读取必须从领导者执行");
}
// 领导者需要确认自己仍然是领导者
raftNode.verifyLeadership();
return readFromLocal(key);
case EVENTUAL:
// 最终一致性:可以从任何节点读取
return readFromLocal(key);
case BOUNDED_STALENESS:
// 有限过期:确保数据不会太旧
return readWithBoundedStaleness(key);
default:
throw new IllegalArgumentException("不支持的一致性级别: " + level);
}
}
private String readWithBoundedStaleness(String key) {
long startTime = System.currentTimeMillis();
long maxStalenessMs = 1000; // 最大过期时间1秒
while (System.currentTimeMillis() - startTime < maxStalenessMs) {
String value = readFromLocal(key);
// 检查数据是否足够新
if (isDataFreshEnough(key)) {
return value;
}
// 等待数据更新
try {
Thread.sleep(10);
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
break;
}
}
// 超时后返回当前数据
return readFromLocal(key);
}
private boolean isDataFreshEnough(String key) {
// 检查数据是否在可接受的过期范围内
// 具体实现取决于系统设计
return true; // 简化实现
}
private String readFromLocal(String key) {
// 从本地存储读取数据
// 简化实现
return "value";
}
}未来发展趋势与挑战
新硬件环境下的一致性
随着新硬件技术的发展,如持久内存(PMem)、RDMA网络等,分布式一致性算法面临着新的机遇和挑战。
/**
* 基于持久内存的优化Raft实现
* 利用PMem特性减少日志复制的延迟
*/
public class PMemOptimizedRaft {
// 使用内存映射文件或PMem进行日志存储
private MappedByteBuffer logBuffer;
/**
* 使用持久内存加速日志写入
*/
public void appendEntry(LogEntry entry) {
// 直接将日志条目写入持久内存
byte[] entryBytes = serializeEntry(entry);
// 使用内存映射,避免系统调用开销
logBuffer.put(entryBytes);
// 强制刷盘(PMem可能不需要)
// logBuffer.force();
}
/**
* 批量日志复制,利用RDMA网络
*/
public void replicateBatchRDMA(List<LogEntry> entries, String targetNode) {
// 使用RDMA进行零拷贝网络传输
// 这可以显著减少CPU开销和延迟
// 简化实现,实际需要RDMA库支持
System.out.println("使用RDMA复制日志到: " + targetNode);
}
private byte[] serializeEntry(LogEntry entry) {
// 序列化日志条目
// 简化实现
return new byte[0];
}
}跨地域分布式系统的一致性
在全球分布的系统中,网络延迟成为主要挑战。我们需要专门的一致性算法来处理跨地域部署。
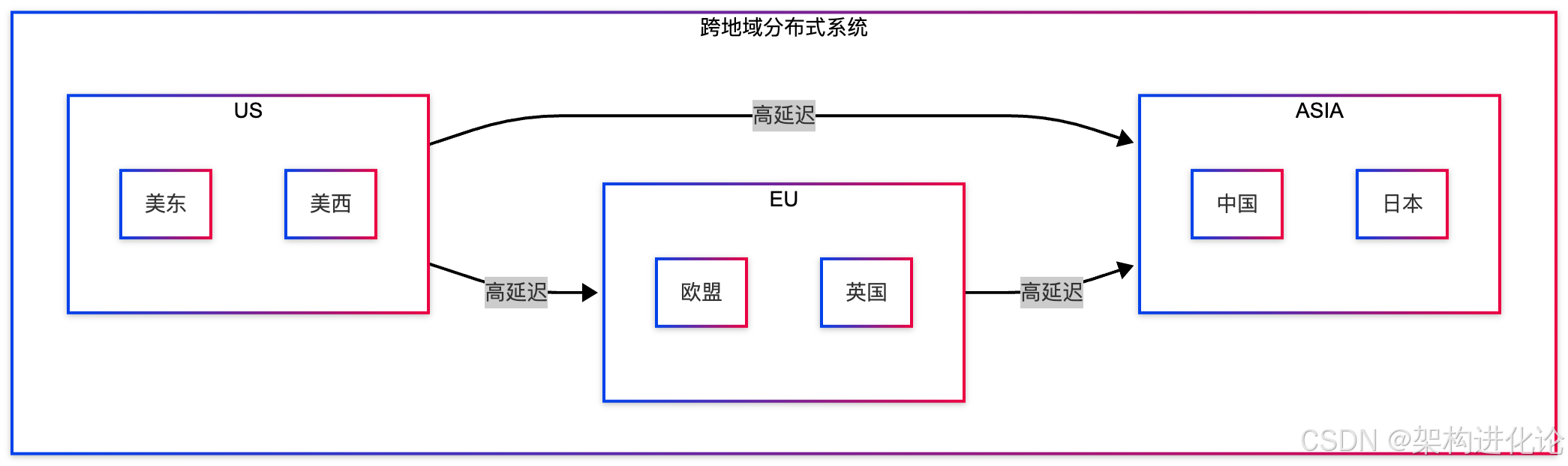
结论
分布式一致性是构建可靠分布式系统的核心技术。从早期的两阶段提交到现代的Raft算法,一致性技术经历了显著的演进。通过本文的探讨,我们可以看到:
-
理论指导实践:CAP理论、Paxos、Raft等理论基础为系统设计提供了重要指导
-
工程实现关键:算法的理论正确性不等于工程可行性,可理解性和可实现性同样重要
-
权衡的艺术:在一致性、可用性、性能之间需要根据业务需求进行合理权衡
-
持续创新:新硬件、新场景推动着一致性技术的持续演进
在实际系统设计中,没有“最好”的一致性方案,只有“最适合”的方案。理解各种一致性技术的原理、优缺点和适用场景,是设计高质量分布式系统的关键。
随着云计算、边缘计算、物联网等技术的发展,分布式一致性将继续面临新的挑战和机遇。作为架构师,我们需要持续学习、深入理解这些核心技术,才能设计出既可靠又高效的分布式系统。



















 169万+
169万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











