




RDMA技术概述与背景
在当今数据中心与高性能计算领域,传统网络通信模式已成为制约系统性能提升的主要瓶颈。在传统的TCP/IP网络通信中,数据发送需要经过多次缓冲拷贝——从应用层缓冲区到内核态缓冲区,再到网卡缓冲区,接收端则反向重复这一过程。这种数据流通路径不仅增加了CPU负载,还导致了显著通信延迟。更为关键的是,在这种通信模式下,远端节点的CPU必须参与几乎所有的数据传输过程,即使这些操作与其核心计算任务无关。

远程直接内存访问(Remote Direct Memory Access,RDMA)技术正是为了解决上述问题而诞生的革新性网络通信方案。RDMA的核心思想很直观:允许一台计算机直接访问另一台计算机的内存,而无需远程计算机操作系统的介入。这种直接访问机制通过专用硬件(通常是RDMA网卡)实现,完全绕过了远程节点的CPU和内核协议栈,从而实现了真正意义上的“零拷贝”数据传输。
从技术演进角度看,RDMA最初源于InfiniBand架构,主要应用于高性能计算(HPC)领域。随着数据中心对低延迟、高吞吐需求的不断增长,RDMA技术开始向以太网迁移,衍生出了RoCE(RDMA over Converged Ethernet)和iWARP(Internet Wide Area RDMA Protocol)两种主流变种。这一演进极大地降低了RDMA的部署成本,推动了其在普通数据中心的普及。
RDMA的三大技术优势使其在现代计算架构中占据关键地位:
-
极低延迟:通过绕过远程CPU和内核协议栈,RDMA将通信延迟从传统的数十微秒降低到微秒甚至亚微秒级别。
-
极低CPU开销:本地CPU只需初始化操作,远程CPU完全不参与数据传输,释放了宝贵的计算资源用于实际业务处理。
-
高带宽:现代RDMA网卡已支持400Gbps甚至更高带宽,满足了大数据、AI训练等数据密集型应用的需求。
为了直观理解RDMA与传统网络的区别,想象一个现实生活中的类比:传统网络通信如同通过邮局寄送包裹,你需要将物品打包、填写邮寄单、经过多个中转站,最后由收件人拆包;而RDMA则像是直接给了你对方仓库的钥匙,你可以直接存取物品,无需惊动仓库管理员。这一根本性差异使得RDMA成为构建下一代高性能数据中心和算力基础设施的关键技术。
RDMA技术原理与架构设计
硬件架构与核心组件
RDMA的硬件架构建立在智能网卡(Smart NIC)的基础上,这种网卡不仅具备标准网络接口功能,还集成了专用于RDMA操作的处理器和内存控制器。RDMA网卡的核心任务是直接处理内存访问请求,而不需要主机的CPU介入。从系统架构角度看,一个完整的RDMA子系统包含以下几个关键组件:
-
队列对(Queue Pair,QP):RDMA通信的基本抽象,由发送队列(Send Queue)和接收队列(Receive Queue)组成。应用程序通过向这些队列提交工作请求(Work Request)来发起RDMA操作。
-
完成队列(Completion Queue,CQ):用于记录已完成的RDMA操作。当工作请求被处理完毕后,网卡会在相应的CQ中放置一个完成队列条目(Completion Queue Entry,CQE),通知应用程序数据操作已经完成。
-
保护域(Protection Domain,PD):安全隔离机制,确保只有授权的QP才能访问特定的内存区域。PD包含了内存注册(Memory Registration)信息,这是RDMA安全模型的基石。
下面的序列图展示了RDMA Write操作的核心流程:
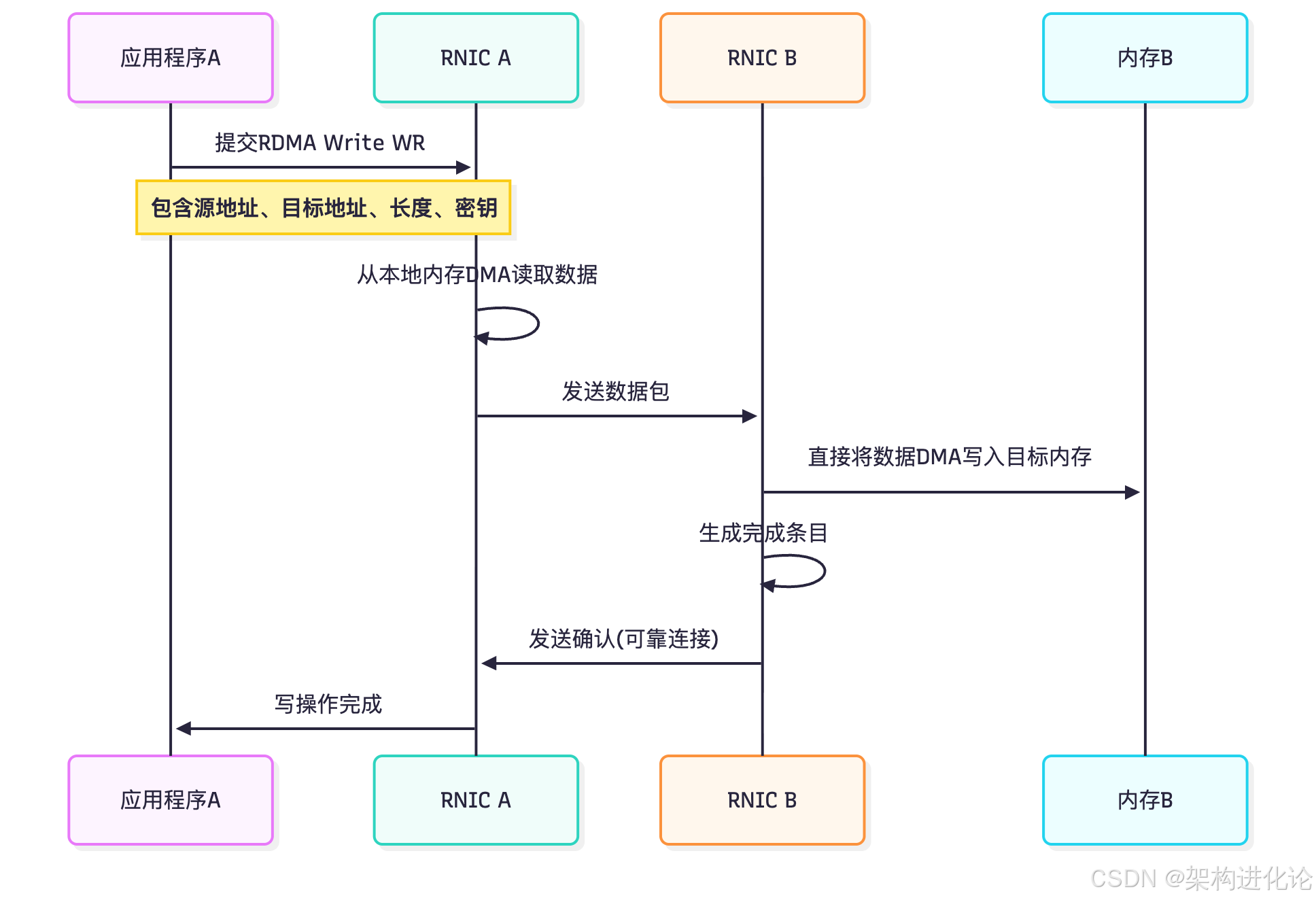
内存注册与保护机制
内存注册是RDMA架构中至关重要的安全与性能基础。在应用程序使用RDMA访问远程内存前,必须先将目标内存区域“注册”到RDMA网卡。这一过程包含两个关键操作:首先,系统会锁定物理内存页,防止它们被换出到磁盘;其次,网卡会建立虚拟地址到物理地址的映射表,并存储在自己的缓存中。
内存注册的同时会生成一个内存密钥(Memory Key),它由虚拟地址、长度和访问权限组成。任何远程访问请求必须提供匹配的内存密钥才能执行操作。这种机制确保了只有被授权的远程节点才能访问特定的内存区域,提供了安全保障。
然而,内存注册也是一把双刃剑:它虽然带来了安全和性能优势,但也是一项高开销操作,通常需要微秒级时间。因此,高性能RDMA应用通常会采用内存池技术,预先注册好内存区域,避免在关键路径上进行注册/注销操作。
RDMA通信模型与传输模式
RDMA支持三种不同的传输模式,每种模式在可靠性、连接性和消息大小上各有特点:
-
可靠连接(Reliable Connection,RC):保证消息的按序交付,支持所有RDMA原语,包括Send/Recv、RDMA Read/Write和原子操作。适用于需要高可靠性的点对点通信。
-
不可靠连接(Unreliable Connection,UC):不保证消息的按序交付,支持Send/Recv和RDMA Write,但不支持RDMA Read。适用于对延迟极其敏感但能容忍少量丢包的应用。
-
不可靠数据报(Unreliable Datagram,UD):支持一对多通信,但单次消息大小受限(通常4KB),且不保证可靠性。主要用于组播和广播场景。
RDMA操作原语
RDMA定义了两类核心原语,满足了不同场景下的通信需求:
-
消息语义(Message Semantics):包含Send/Recv这对原语,类似于传统Socket编程中的发送接收模型。接收方必须预先发布接收请求,指定存储传入数据的缓冲区。当发送方执行Send操作时,数据会被传输到接收方预先指定的位置。
-
内存语义(Memory Semantics):包括RDMA Read和RDMA Write两种操作,实现了真正的远程直接内存访问。这些操作是单向的——只需要发起方的参与,不需要远程CPU的介入。内存语义是RDMA性能优势的主要来源。
下面的表格对比了三种主要RDMA传输模式的特性和支持的操作:
表:RDMA传输模式及特性对比
| 特性 | 可靠连接(RC) | 不可靠连接(UC) | 不可靠数据报(UD) |
|---|---|---|---|
| 连接方式 | 点对点 | 点对点 | 一对多 |
| 可靠性 | 可靠,按序交付 | 不可靠,可能乱序 | 不可靠,可能乱序 |
| 最大传输单元 | 2GB | 2GB | 4KB |
| Send/Recv | 支持 | 支持 | 支持 |
| RDMA Write | 支持 | 支持 | 不支持 |
| RDMA Read | 支持 | 不支持 | 不支持 |
| 原子操作 | 支持 | 不支持 | 不支持 |
RDMA技术演进与实现方式
InfiniBand:原生RDMA技术
InfiniBand(IB)是最早实现RDMA技术的网络架构,从设计之初就为RDMA提供了原生支持。InfiniBand采用完全独立的网络协议栈,包括物理层、链路层、网络层和传输层,与传统的以太网架构有根本性区别。InfiniBand网络需要专用的IB网卡、IB交换机和IB线缆,形成了一个封闭但高性能的生态系统。
在InfiniBand架构中,RDMA操作通过通道适配器(Channel Adapter)执行——主机端称为主机通道适配器(HCA),交换机端称为目标通道适配器(TCA)。InfiniBand HCA通常具有极高的性能指标,延迟可低至百纳秒级别,支持多达数百万的队列对。
然而,InfiniBand的主要劣势在于部署成本高且与现有以太网基础设施不兼容。这些因素限制了InfiniBand的应用范围,使其主要集中于高性能计算、金融交易等对延迟极其敏感的特定领域。
RoCE:融合以太网上的RDMA
RoCE(RDMA over Converged Ethernet)技术诞生于2010年,旨在将RDMA的性能优势引入到标准以太网环境中。RoCE有两个主要版本:RoCEv1和RoCEv2。
-
RoCEv1:基于以太网链路层实现,在以太网帧头中使用0x8915作为类型标识,仅在二层网络内有效。
-
RoCEv2:将RDMA协议封装在UDP/IP数据包中,这使得RoCEv2可以跨越三层网络路由,大大提升了可扩展性。
RoCE的关键技术依赖是无损以太网,需要以太网交换机支持优先级流控制(PFC)和增强传输选择(ETS)等数据中心桥接(DCB)特性。这些机制确保了RDMA流量在以太网上传输时能够实现零丢包,这是保证RDMA性能的关键。
在实际应用中,中国移动与华为合作的客服分布式云系统项目展示了RoCE技术的巨大价值。通过部署“基于RoCE无损以太网的客服分布式云系统”,他们实现了智能话务交互延迟降低约200毫秒,整体性能提升30%以上。这一案例证明了RoCE在企业级应用中能够带来的实质性改进。
iWARP:基于TCP的RDMA实现
iWARP(Internet Wide Area RDMA Protocol)是第三种RDMA实现方式,由IETF标准定义。与RoCE不同,iWARP将RDMA协议封装在标准的TCP数据包中,完全兼容现有IP网络基础设施。
从技术架构看,iWARP在TCP之上构建了直接数据放置协议(DDP)和标记TCP协议(MPA),实现了绕过内核的零拷贝数据传输。由于基于TCP,iWARP天然支持路由和广域网部署,不需要特殊的网络设备。
然而,TCP协议的复杂性导致iWARP网卡设计更为复杂,成本和功耗也相对较高。同时,TCP的拥塞控制机制和重传逻辑也使得iWARP在延迟表现上通常不如InfiniBand和RoCE。因此,iWARP在市场上的应用相对较少,主要用于特定的广域网RDMA场景。
技术对比与应用场景
表:三种RDMA实现方式对比
| 特性 | InfiniBand | RoCE | iWARP |
|---|---|---|---|
| 网络架构 | 专用网络 | 以太网 | 以太网/IP |
| 协议基础 | InfiniBand协议 | UDP/IP | TCP/IP |
| 部署成本 | 高 | 中等 | 中等 |
| 延迟性能 | 最优 | 优 | 良 |
| 可扩展性 | 局域网 | 局域网/园区 | 广域网 |
| 配置复杂度 | 高 | 中 | 低 |
| 市场占有率 | 高性能计算 | 企业/云数据中心 | 特定应用 |
根据上表的对比,三种RDMA技术各有适合的应用场景:
-
InfiniBand最适合延迟极其敏感的高性能计算环境,如超级计算机、AI训练集群。
-
RoCE在通用数据中心中具有最佳平衡点,特别是在已有无损以太网基础设施的环境中。
-
iWARP主要用于需要跨越广域网的RDMA应用,虽然应用较少,但在特定场景下不可替代。
RDMA实践应用与代码示例
RDMA在分布式系统中的应用
RDMA技术已在多个分布式系统领域展现出革命性的影响,特别是在分布式存储、分布式键值系统和AI训练集群中:
-
分布式存储系统:传统分布式存储系统受限于网络延迟,往往采用粗粒度的数据分布和复制策略。利用RDMA的低延迟特性,系统可以实现细粒度的数据访问模式。例如,基于RDMA的分布式内存文件系统(如RNFS)通过结合RDMA与非易失性内存(NVM),实现了接近本地性能的远程文件访问。这类系统通常采用主从架构,Master节点负责元数据管理,Slave节点存储实际数据,客户端通过RDMA Read/Write直接访问Slave节点上的数据。
-
分布式键值系统:键值存储系统对延迟极其敏感,传统的基于TCP/IP的实现方式中,GET/PUT操作需要多次穿越内核协议栈。采用RDMA后,特别是利用RDMA Read原语,客户端可以直接从服务器内存中读取键值数据,完全绕过远程CPU。研究表明,这种设计可以将延迟从几十微秒降低到几微秒。
-
AI训练集群:现代大规模AI训练(如万卡集群)中,GPU间通信时间往往成为整体训练速度的瓶颈。通过RDMA与GPU Direct技术结合,GPU可以直接与其他节点的GPU进行数据交换,不需要通过主机内存中转。这一优化对于分布式训练速度提升至关重要,也是当前AI基础设施的关键技术。
RDMA编程实例详解
以下将通过一个简化的RDMA通信示例,展示如何使用Verbs API建立连接并进行数据通信。RDMA Verbs API是RDMA编程的基础接口,类似于Socket API之于网络编程。
服务端初始化代码
服务端的首要任务是创建监听通道,等待客户端连接:
#include <rdma/rdma_cma.h>
struct rdma_cm_id *listener = NULL;
struct rdma_event_channel *ec = NULL;
struct sockaddr_in addr;
// 创建事件通道,用于报告通信事件
ec = rdma_create_event_channel();
if (!ec) {
perror("rdma_create_event_channel");
exit(1);
}
// 创建RDMA标识,指定使用TCP语义
if (rdma_create_id(ec, &listener, NULL, RDMA_PS_TCP)) {
perror("rdma_create_id");
exit(1);
}
// 设置监听地址
memset(&addr, 0, sizeof(addr));
addr.sin_family = AF_INET;
addr.sin_addr.s_addr = htonl(INADDR_ANY);
addr.sin_port = htons(12345); // 监听端口
// 绑定地址到RDMA标识
if (rdma_bind_addr(listener, (struct sockaddr *)&addr)) {
perror("rdma_bind_addr");
exit(1);
}
// 开始监听,允许最多10个 pending 连接
if (rdma_listen(listener, 10)) {
perror("rdma_listen");
exit(1);
}
printf("RDMA服务端正在监听端口12345...\n");
客户端连接代码
客户端需要解析服务器地址并发起连接:
struct rdma_cm_id *conn = NULL;
struct rdma_event_channel *ec = NULL;
struct addrinfo *res;
// 解析服务器地址
struct addrinfo hints = {0};
hints.ai_family = AF_INET;
hints.ai_socktype = SOCK_STREAM;
if (getaddrinfo("server_hostname", "12345", &hints, &res)) {
perror("getaddrinfo");
exit(1);
}
// 创建事件通道和RDMA标识
ec = rdma_create_event_channel();
rdma_create_id(ec, &conn, NULL, RDMA_PS_TCP);
// 解析服务器RDMA地址
rdma_resolve_addr(conn, NULL, res->ai_addr, 2000);
资源设置与内存注册
连接建立后,双方需要创建保护域、完成队列、队列对等资源,并注册内存供远程访问:
struct ibv_pd *pd; // 保护域
struct ibv_cq *cq; // 完成队列
struct ibv_qp *qp; // 队列对
struct ibv_mr *mr; // 内存区域
// 获取保护域
pd = ibv_alloc_pd(conn->verbs);
if (!pd) {
perror("ibv_alloc_pd");
exit(1);
}
// 创建完成队列
cq = ibv_create_cq(conn->verbs, 100, NULL, NULL, 0);
if (!cq) {
perror("ibv_create_cq");
exit(1);
}
// 配置队列对属性
struct ibv_qp_init_attr qp_attr = {0};
qp_attr.send_cq = cq;
qp_attr.recv_cq = cq;
qp_attr.qp_type = IBV_QPT_RC; // 可靠连接
qp_attr.cap.max_send_wr = 100; // 发送队列深度
qp_attr.cap.max_recv_wr = 100; // 接收队列深度
qp_attr.cap.max_send_sge = 1; // 发送分散/聚集元素数量
qp_attr.cap.max_recv_sge = 1; // 接收分散/聚集元素数量
// 创建队列对
qp = ibv_create_qp(pd, &qp_attr);
if (!qp) {
perror("ibv_create_qp");
exit(1);
}
// 分配并注册内存
char *buffer = malloc(1024 * 1024); // 1MB缓冲区
if (!buffer) {
perror("malloc");
exit(1);
}
// 注册内存,允许远程读写
mr = ibv_reg_mr(pd, buffer, 1024 * 1024,
IBV_ACCESS_LOCAL_WRITE |
IBV_ACCESS_REMOTE_READ |
IBV_ACCESS_REMOTE_WRITE);
if (!mr) {
perror("ibv_reg_mr");
exit(1);
}
RDMA数据传输
内存注册后,客户端可以直接通过RDMA Write将数据写入服务器内存:
// 准备RDMA Write工作请求
struct ibv_sge sge;
sge.addr = (uintptr_t)local_buffer; // 本地数据地址
sge.length = data_length; // 数据长度
sge.lkey = local_mr->lkey; // 本地内存密钥
struct ibv_send_wr wr = {0};
wr.wr_id = 1; // 请求标识
wr.opcode = IBV_WR_RDMA_WRITE; // RDMA写操作
wr.sg_list = &sge;
wr.num_sge = 1;
wr.send_flags = IBV_SEND_SIGNALED; // 请求完成后发送信号
// 设置远程访问参数
wr.wr.rdma.remote_addr = (uintptr_t)remote_addr; // 远程内存地址
wr.wr.rdma.rkey = remote_rkey; // 远程内存密钥
struct ibv_send_wr *bad_wr;
if (ibv_post_send(qp, &wr, &bad_wr)) { // 提交工作请求
perror("ibv_post_send");
exit(1);
}
// 等待操作完成
struct ibv_wc wc;
int ret;
do {
ret = ibv_poll_cq(cq, 1, &wc);
} while (ret == 0);
if (wc.status != IBV_WC_SUCCESS) {
fprintf(stderr, "RDMA Write失败,状态码: %d\n", wc.status);
}
实际应用案例:智能客服系统
为了更具体展示RDMA的实际价值,让我们深入分析中国移动与华为合作的客服分布式云系统。这一系统面临的核心挑战是:在线营销服务业务规模快速增长,2016-2021年中国在线营销行业市场规模的年复合增长率约20%-30%,业务系统生产数据量和读写频率持续提升,对基础设施提出了极高要求。
传统基于TCP/IP的分布式系统在处理高并发请求时存在以下问题:
-
高CPU开销:数据处理过程中频繁的内核态-用户态切换消耗了大量CPU资源
-
网络延迟:多次数据拷贝和协议处理增加了请求响应时间
-
丢包敏感:传统以太网的随机丢包会导致重传,进一步增加延迟
通过部署“基于RoCE无损以太网的客服分布式云系统”,他们实现了:
-
智能话务交互延迟降低约200毫秒,显著改善用户体验
-
整体性能提升30%以上,提高了系统吞吐量
-
通过无损网络实现零丢包,保证了稳定性和可预测性
这一案例充分证明,RDMA技术不仅在高性能计算领域有价值,在企业级应用和普通数据中心同样能带来显著效益。
RDMA发展挑战与未来展望
技术挑战与局限性
尽管RDMA技术具有显著优势,但在实际部署和应用中仍面临多重挑战:
-
内存注册开销:如前所述,内存注册是一项高开销操作,虽然内存池技术可以缓解这一问题,但在动态内存分配频繁的场景中,仍然会影响性能。
-
编程复杂性:RDMA Verbs API比传统的Socket编程复杂得多,开发者需要深入理解硬件特性、内存管理和并发控制,学习曲线陡峭。
-
网络配置要求:特别是对于RoCE,需要无损网络环境支持,这要求交换机支持PFC和ECN等流控技术,增加了网络配置和管理的复杂度。
-
可扩展性问题:RDMA基于队列对的模型在大规模集群中会面临资源消耗问题。每个节点与其他每个节点通信都需要单独的QP,n节点集群可能需要n²数量的QP,这对网卡资源是巨大挑战。
-
虚拟化挑战:在云环境中,RDMA虚拟化仍是一个开放性问题。虽然已有一些解决方案(如SR-IOV、软RDMA),但在性能隔离、资源管理和迁移灵活性方面仍有不足。
国产化现状与发展机遇
在国际技术竞争加剧的背景下,RDMA网卡芯片的国产化发展成为重要议题。根据2024年CCF YOCSEF天津技术论坛的讨论,国产RDMA网卡芯片目前面临以下现状:
-
性能差距:国内成熟商用RDMA网卡芯片最高性能不超过2×100G,而国际领先水平已达400G甚至800G
-
起步较晚:国产RDMA网卡芯片产业起步晚、规模小、发展慢
-
制程限制:受限于芯片制造工艺,短期内难以实现重大突破
论坛专家指出,应对这些挑战需要双轨并行的策略:一方面,通过硬件逻辑设计的创新弥补制程不足,如采用多核架构提升性能;另一方面,继续投入芯片制程工艺的研发,从根本上解决问题。
未来发展趋势
RDMA技术的未来发展呈现出多个明显趋势:
-
融合架构:短期来看,Scale-Up(纵向扩展)和Scale-Out(横向扩展)网络是分离的,但长期趋势是基于以太网实现两种网络的融合,简化架构并提升灵活性。
-
软硬件协同设计:通过异构计算架构,将部分网络功能卸载到DPU(数据处理器)或智能网卡,进一步释放CPU负载,提升系统整体效率。
-
协议标准化:由中立科研机构或产业联盟推动国产RDMA技术标准,在物理层、链路层、网络层和传输层形成统一规范,并与国际标准(如美国主导的UEC标准)兼容互通。
-
AI驱动优化:随着AI训练规模不断扩大,RDMA将与GPU Direct等技术更紧密结合,支持万卡AI集群的高效通信,同时平衡有损与无损网络的使用。
-
新应用场景:从传统的高性能计算向更广泛的领域扩展,包括数据库、云计算、边缘计算和5G网络基础设施。
下图展示了RDMA技术未来的发展路径:
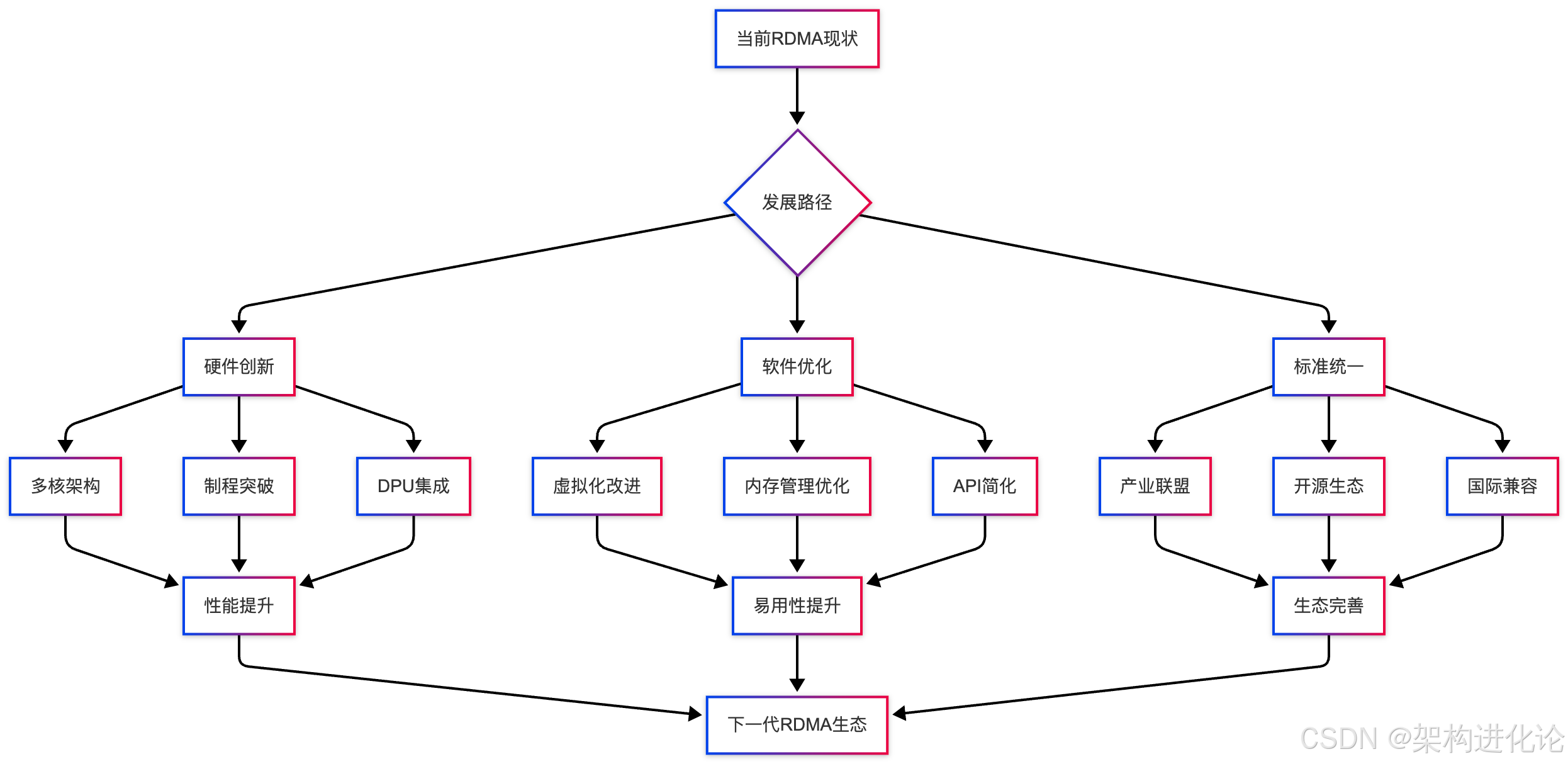
结论
RDMA技术代表了网络通信模式的根本性变革,它通过绕过远程CPU和内核协议栈,实现了直接内存访问,从而提供了极低的延迟和CPU开销。随着数字化进程加速,特别是AI和大数据应用的普及,RDMA在构建高性能计算基础设施中的重要性将持续提升。
从技术实现角度看,RDMA的三种主流技术——InfiniBand、RoCE和iWARP各有优势,适用于不同场景。RoCE因其在性能和成本间的平衡,正成为企业数据中心的主流选择。而在编程模型方面,RDMA Verbs API虽然复杂,但提供了对硬件能力的直接控制,使开发者能够充分发挥RDMA的潜力。
然而,RDMA技术的广泛应用仍面临挑战,包括内存注册开销、编程复杂性、网络配置要求等问题。同时,在国际技术竞争环境下,国产RDMA芯片的发展任重道远,需要产学研各方协同努力,在硬件设计、软件生态和标准制定上取得突破。
未来,随着DPU、异构计算等新技术的发展,RDMA将与更广泛的计算架构深度融合,为从数据中心到边缘计算的各个层面提供高性能网络支撑。对于架构师和技术决策者而言,深入了解并适时引入RDMA技术,将是构建下一代高性能应用的关键竞争优势。
正如本文通过理论分析和实践案例所展示的,RDMA不再是仅限于高性能计算领域的专有技术,而是正在成为主流数据中心的核心组件。无论是像中国移动客服系统这样的企业应用,还是大规模AI训练集群,RDMA都能带来显著的性能提升。随着技术的不断成熟和生态的完善,RDMA有望成为未来计算基础设施的标配技术,为各行业的数字化转型提供强大动力。



















 2299
2299

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











