




内容源自计算机科研圈
本文第一作者王文,浙江大学博士生,研究方向是多模态理解与生成等。本文通讯作者沈春华,浙江大学求是讲席教授,主要研究课题包括具身智能、大模型推理增强、强化学习、通用感知模型等。
近年来,扩散大语言模型(Diffusion Large Language Models, dLLMs)正迅速崭露头角,成为文本生成领域的一股新势力。与传统自回归(Autoregressive, AR)模型从左到右逐字生成不同,dLLM 依托迭代去噪的生成机制,不仅能够一次性生成多个 token,还能在对话、推理、创作等任务中展现出独特的优势。当你还在等传统 LLM「一个字一个字」地憋出答案时,dLLM 早已通过几轮迭代「秒」出完整结果,带来前所未有的生成效率。
然而,速度的提升并不意味着完美的答案。现有 dLLM 的解码策略往往只关注最后一次迭代的生成结果,直接舍弃了中间多轮迭代中蕴含的丰富语义与推理信息。这些被忽视的中间预测,实际上可能暗藏着更准确、更接近真相的答案。一旦被丢弃,不仅造成信息浪费,还可能让模型错失做对题目的最佳时机。
更令人意外的是,研究团队在数学推理任务中观察到了一种「先对后错」的现象:模型先是得出了正确答案,却在随后的迭代中将其「推翻」,转而采用错误答案,最终导致整体回答错误。以下图为例,模型在第 55 步时明明已经得到正确的 25,却在后续生成中改成了 2,并一直坚持到最后也未能修正。
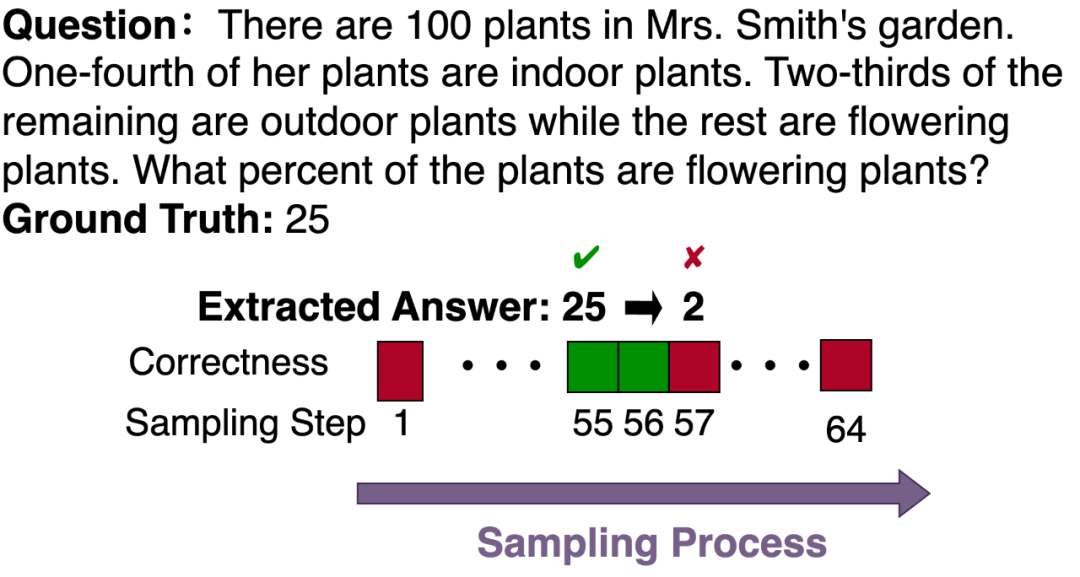
正是基于这一关键观察,来自浙江大学的研究团队从时序视角切入,提出了 Temporal Self-Consistency Voting 与 Temporal Consistency Reinforcement 两种方法,对模型的性能进行优化与提升。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1046
1046

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









