







目录
- 多线程存在的问题
- 互斥量
- 死锁
- 其他替代方案
- 总结
多线程存在的问题
当涉及到共享数据时,问题很可能是因为共享数据修改所导致。如果共享数据是只读的,那么只读操作不会影响到数据,更不会涉及对数据的修改,所以所有线程都会获得同样的数据。但是,当一个或多个线程要修改共享数据时,就会产生很多麻烦。当两个线程在修改共享数据的时候,一个线程可能会读到被修改还未写回的数据,也就是一个中间状态的数据,c++并发编程中翻译为不变量(invariants)。
对一个int数据加1,其实可以分为三个步骤:
- 取数据放到寄存器
- cpu进行+1
- 将数据写回内存
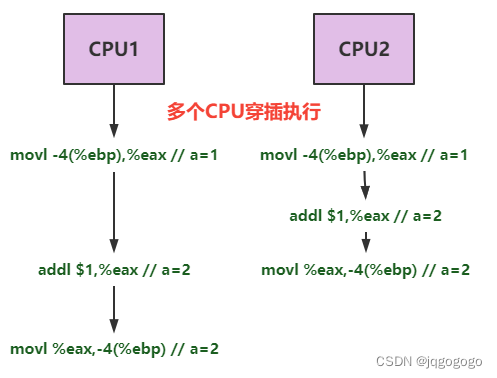
上图中对a=1进行了两次+1操作结果却是2,因为一个线程读到的是另一个线程进行了+1但是还没来得及写回内存的数据。
int count = 0;
void add()
{
for(int i = 0; i < 100000; i++)
{
count++;
}
}
thread t1(add);
thread t2(add);
cout<<"count= "<<count<<endl; // 结果未知
互斥量
mutex
为了保护多个线程共享的数据,可以采用互斥量将访问贡献数据的代码标记为互斥的。这样任何一个线程在访问共享数据的时候,都必须等前面的线程访问结束后才能进行访问,于是一个线程就不可能看到中间状态的数据。
c++中通过std::mutex创建互斥量,通过调用成员函数lock()进行加锁,unlock()进行解锁。当访问共享数据前进行加锁,访问后进行解锁。std::mutex的成员函数如下:
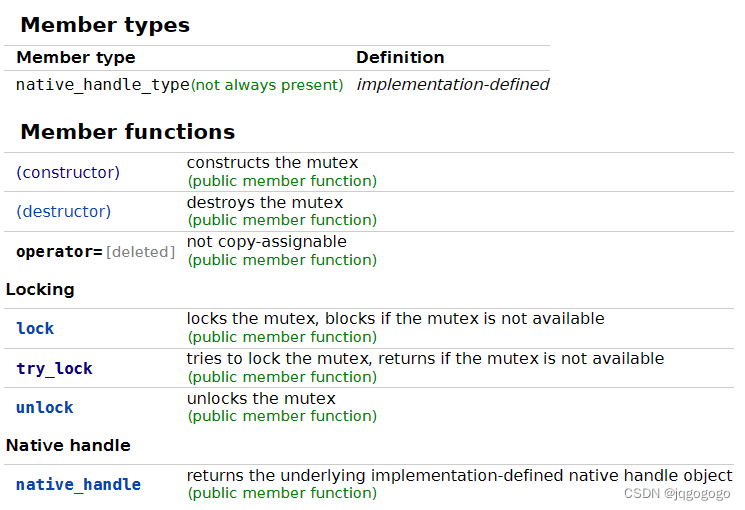
对上述例子,进行修改可以保证最后的结果是确定的。
mutex m; // 定义互斥量
int count = 0;
void add()
{
for(int i = 0; i < 100000; i++)
{
m.lock(); // 加锁
count++; // 修改共享数据
m.unlock(); // 解锁
}
}
lock_guard
但是其实在实践中不会直接去调用成员函数,因为调用lock之后一定要手动的调用unlock,否则别的线程将永远阻塞。C++提供了RAII语法的模板类lock_guard在构造函数中对互斥量进行加锁,在析构函数中解锁,从而保证了一个互斥量总能被正确的加锁解锁。
void add()
{
lock_guard<mutex> lock(m); // 定义了一个局部对象lock_guard
for(int i = 0; i < 100000; i++)
{
count++;
}
}
unique_lock
std::unique_lock是比std::lock_guard更灵活的锁,它同样可以在构造函数中对mutex对象进行加锁,在析构函数中进行解锁,它还支持其他的对锁管理方式。下面给出它的构造函数:
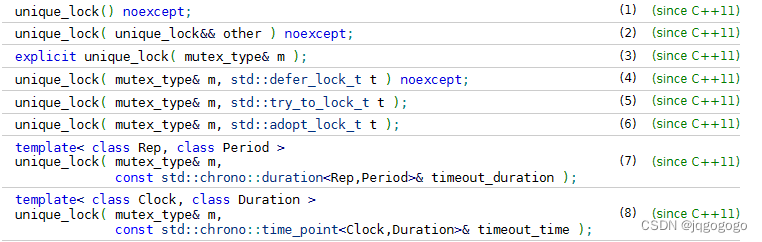
构造函数3:功能类似于std::lock_guard。主要介绍构造函数4、5、6,分别会传入一下几个类型的参数:

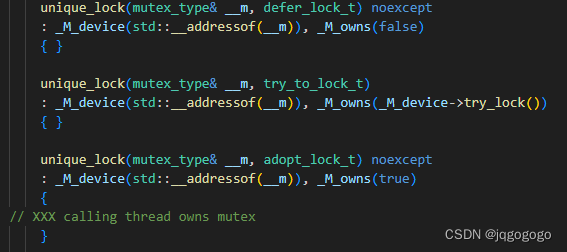
这三个类都是空类,只是用来标识不同的加锁策略。defer_lock_t不加锁,对mutex的所有权为false,try_lock_t尝试加锁,adopt_lock_t默认拥有对mutex的所有权。
下面的例子,展示了unique_lock的不同管理功能,通过普通构造函数可以实现对a的多线程修改,通过设置defer_lock_t可以对mutex延迟加锁,然后可以将lockb和lockc传入lock函数实现对两个mutex的同时加锁,然后调用exchange函数将c = b+c,b = c的旧值。
int a = 1, b = 1, c = 1;
mutex m_a, m_b, m_c;
void update()
{
{
unique_lock<mutex> lock(m_a);
a++;
}
{
unique_lock<mutex> lockb(m_b, std::defer_lock 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 8675
8675

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









