









 提出了一种简单且高度模块化的网络架构ResNeXt,该架构通过重复使用一种聚合了相同拓扑结构的变换集的构建块来实现图像分类任务。设计中采用了两个简化规则:如果产生相同大小的空间映射,则块间共享相同的超参数;每当空间映射尺寸减半时,块的宽度则加倍,确保所有块的计算复杂度大致相同。
提出了一种简单且高度模块化的网络架构ResNeXt,该架构通过重复使用一种聚合了相同拓扑结构的变换集的构建块来实现图像分类任务。设计中采用了两个简化规则:如果产生相同大小的空间映射,则块间共享相同的超参数;每当空间映射尺寸减半时,块的宽度则加倍,确保所有块的计算复杂度大致相同。
TITLE: Aggregated Residual Transformations for Deep Neural Networks
AUTHOR: Saining Xie, Ross Girshick, Piotr Dollár, Zhuowen Tu, Kaiming He
ASSOCIATION: UC San Diego, Facebook AI Research
FROM: arXiv:1611.05431
CONTRIBUTIONS
A simple, highly modularized network (ResNeXt) architecture for image classification is proposed. The network is constructed by repeating a building block that aggregates a set of transformations with the same topology.
METHOD
The network is designed with two simple rules inspired by VGG/ResNets:
- if producing spatial maps of the same size, the blocks share the same hyper-parameters (width and filter sizes).
- each time when the spatial map is downsampled by a factor of 2, the width of the blocks is multiplied by a factor of 2. The second rule ensures that the computational complexity, in terms of FLOPs is roughly the same for all blocks.
The building block of ResNeXt is shown in the following figure:
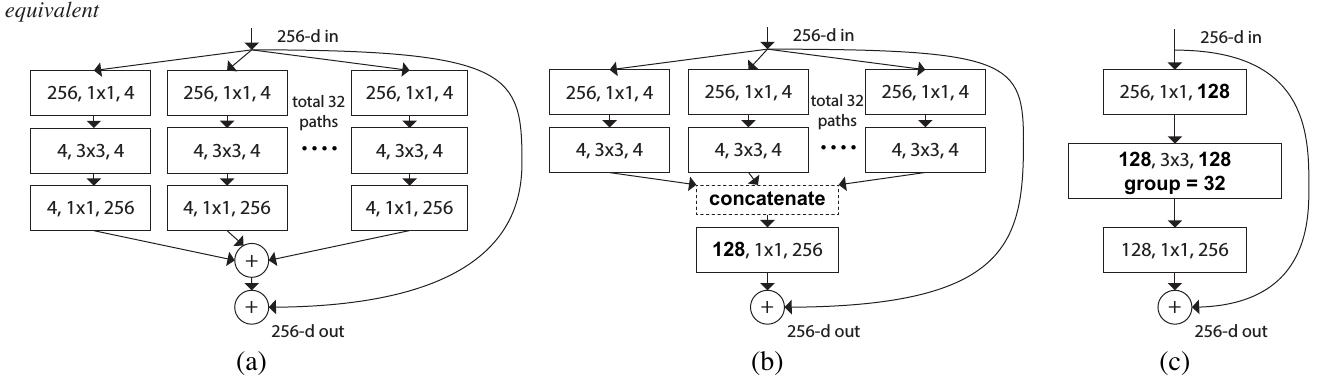
Such design will make the network having more channels (sets of transformations) without increasing much FLOPs, which is claimed as the increasing of ardinality.
SOME IDEAS
The explanation of why such designation can lead to better performance seems to be less pursative.

















 2132
2132

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









