






问题描述
本人在使用vllm的openai接口部署llama3以及llama2时,出现了下面的模型输出结果:
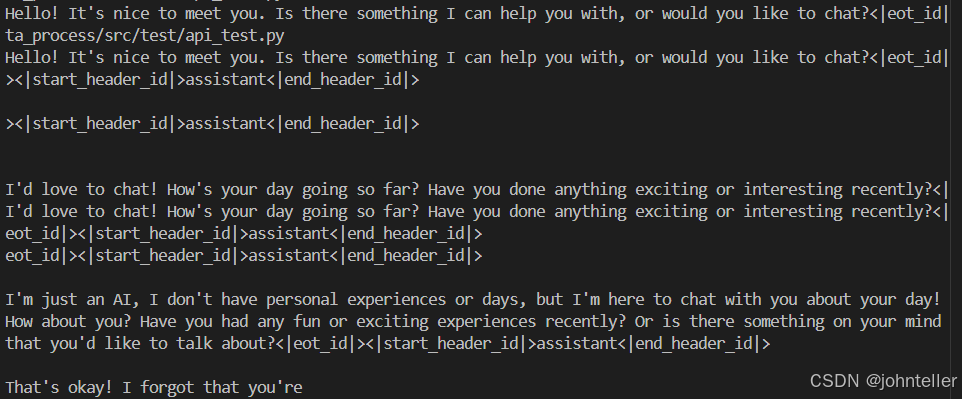
可以看到上面的输出存在两点问题:
1. 输出中包含模型的eos_token_id信息;
2. 模型接着上一段开始自行组织多轮对话直到max_tokens.
解决方案
很简单,在openai的response中设置stop为相应模型的eos_token_id即可:

后记
因为学艺不精出现的一个弱智问题,特此记录。

本人在使用vllm的openai接口部署llama3以及llama2时,出现了下面的模型输出结果:
可以看到上面的输出存在两点问题:
1. 输出中包含模型的eos_token_id信息;
2. 模型接着上一段开始自行组织多轮对话直到max_tokens.
很简单,在openai的response中设置stop为相应模型的eos_token_id即可:
因为学艺不精出现的一个弱智问题,特此记录。
 822
2412
822
2412

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言


























