






1 OpenCV介绍
OpenCV(开放源代码计算机视觉库)是一个开源的计算机视觉和机器学习软件库。由一系列 C++ 类和函数构成,用于图像处理、计算机视觉领域的算法实现。
1.1 OpenCV优势
-
开源免费:完全开源,可以自由使用,降低开发成本和技术门槛。
-
多语言支持:除C++原生接口外,还支持Java、Python等编程语言。
-
跨平台:支持多种操作系统,Windows、Linux、ios、Android等,方便开发和部署。
-
丰富API:完善的传统计算机视觉算法,涵盖主流的机器学习算法,同时添加了对深度学习的支持。
1.2 OpenCV-Python
OpenCV-Python是原始OpenCV C++实现的Python包装器。它结合了 OpenCV C++ API 的高性能与 Python 语言的易用性和简洁性。通过 OpenCV-Python,开发者可以轻松地进行图像处理、计算机视觉任务以及机器学习应用。
与C / C++等语言相比,Python速度较慢。Python可以使用C / C++扩展,这使我们可以在C / C++中编写计算密集型代码,并创建可用作Python模块的Python包装器。两个好处:首先,代码与原始C / C++代码一样快(因为它是在后台工作的实际C++代码),其次,在Python中编写代码比使用C / C++更容易。
OpenCV-Python使用Numpy,这是一个高度优化的数据库操作库。所有OpenCV数组结构都转换为Numpy数组。这也使得与使用Numpy的其他库(如SciPy和Matplotlib)集成更容易。
2 环境安装
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple opencv-python
3 图像表示
像素是图像的基本单元,每个像素存储着图像的颜色、亮度和其他特征。一系列像素组合到一起就形成了完整的图像,在计算机中,图像以像素的形式存在并采用二进制格式进行存储。根据图像的颜色不同,每个像素可以用不同的二进制数表示。
计算机采用0/1编码的系统,数字图像也是利用0/1来记录信息,我们平常接触的图像都是8位数图像。opencv中常用的是8位图像,大多数彩色和灰度图像使用8位表示每个通道的像素值,范围从0到255,其中0,代表最黑,1,表示最白。。
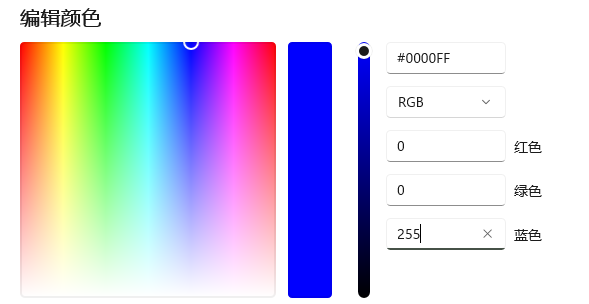
日常生活中常见的图像是RGB三原色图。RGB图上的每个点都是由红(R)、绿(G)、蓝(B)三个颜色按照一定比例混合而成的,几乎所有颜色都可以通过这三种颜色按照不同比例调配而成。在计算机中,RGB三种颜色被称为RGB三通道,根据这三个通道存储的像素值,来对应不同的颜色。例如,在使用“画图”软件进行自定义调色时,其数值单位就是像素。


在OpenCV中,无论是读取还是创建图像,结果都是一个NumPy数组。对于彩色图像,这个数组通常是三维的;而对于灰度图像,则是二维的。图像本质上是像素值的二维或三维矩阵(对于彩色图像)。使用 NumPy 数组来表示图像数据非常适合,因为这样可以直接利用 NumPy 提供的强大功能进行快速的数值运算和矩阵操作。
-
形状(Shape):图像的尺寸由其高(height)、宽(width)和通道数(channels)决定。可以通过img.shape属性获取这些信息。
-
对于彩色图像(如RGB),返回的是一个包含三个值的元组 (height, width, channels)。
-
对于灰度图像,返回的是一个包含两个值的元组 (height, width),因为灰度图像只有一个通道。
-
数据类型(dtype):图像中的每个像素值的数据类型决定了可以存储的最大值。例如,8位无符号整数(uint8)允许的范围是从0到255。
-
像素表示
-
单通道图像(灰度图像):每个像素由一个数值表示,代表该点的亮度。值越低(接近0),颜色越暗;值越高(接近255),颜色越亮。
-
多通道图像(彩色图像): 在OpenCV中,默认情况下,彩色图像是以BGR(蓝-绿-红)顺序存储的,而不是常见的RGB格式。 每个像素由三个数值组成,分别对应蓝色、绿色和红色分量。
-

彩色图像
每个像素通常是由红(R)、绿(G)、蓝(B)三个分量来表示的,分量介于(0,255)。RGB图像与索引图像一样都可以用来表示彩色图像。与索引图像一样,它分别用红(R)、绿(G)、蓝(B)三原色的组合来表示每个像素的颜色。但与索引图像不同的是,RGB图像每一个像素的颜色值(由RGB三原色表示)直接存放在图像矩阵中,由于每一像素的颜色需由R、G、B三个分量来表示,M、N分别表示图像的行列数,三个M x N的二维矩阵分别表示各个像素的R、G、B三个颜色分量。RGB图像的数据类型一般为8位无符号整形,通常用于表示和存放真彩色图像。

每一个像素点又由通道数组成,以三通道为例,一个像素为BGR组成,BGR为8位无符号整数
4 基本图像操作
4.1 创建窗体
-
cv2.namedWindow(winname,[窗口属性])
使用
cv2.namedWindow()方法创建一个新的窗口。你可以为这个窗口指定一个名称,并且可以选择窗口的属性(例如,是否可调整大小)。参数:
-
winname:窗口名
-
窗口属性:窗口大小是否可调整
-
import cv2 as cv
#创建窗口cv.namedwindow(窗口名,flags)
#flags窗口属性标志,控制窗口的行为和显示方式,默认是 cv2.WINDOW_AUTOSIZE
#cv.WINDOW_NORMAL窗口大小可控制
cv.namedWindow('text', cv.WINDOW_NORMAL)
#cv.WINDOW_AUTOSIZE自适应图片大小
cv.namedWindow('image', cv.WINDOW_AUTOSIZE)
4.2 读取图像
-
cv2.imread(path,[读取方式])
参数:
-
filename:图像路径
-
-
读取方式:彩色·默认、灰色等
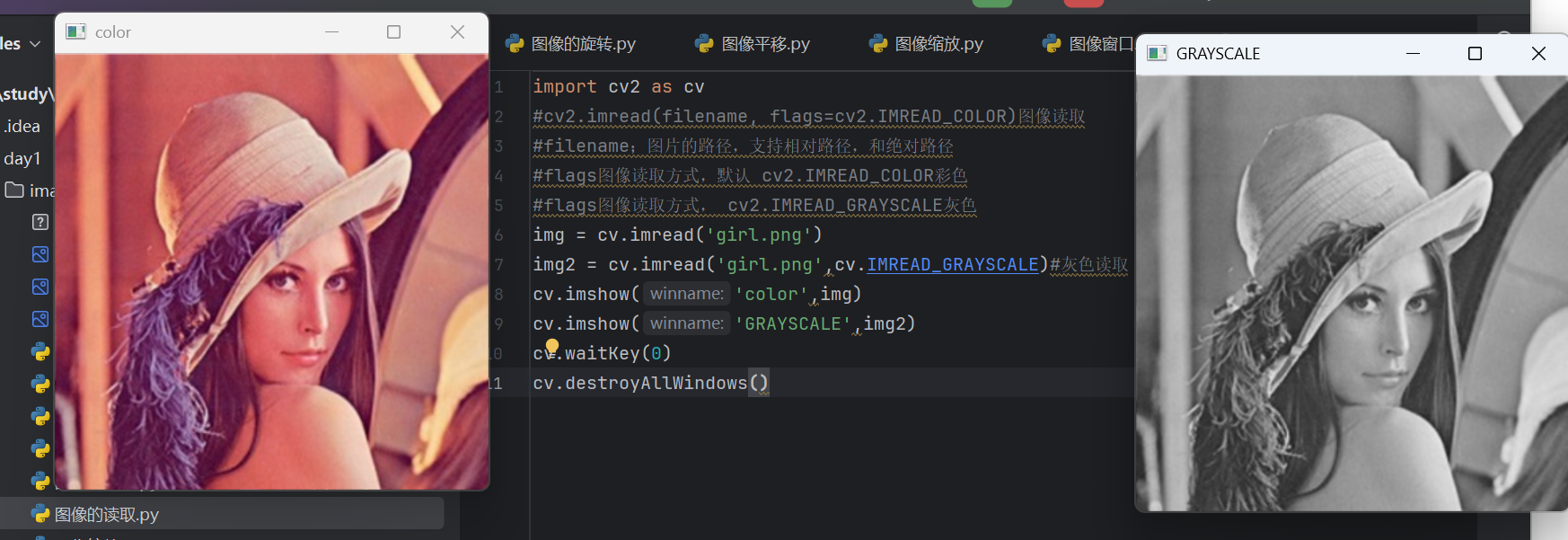
可以看到读取方式不同显示不同。
4.3 显示图像
-
cv2.imshow(winname,img)
参数:
-
winname:显示图像的窗口名,以字符串类型表示
-
img:要显示的图像
注意:在调用显示图像的API后,要调用cv2.waitKey(0)给图像绘制留下时间,否则窗口会出现无响应情况,并且图像无法显示出来。
-
cv.waitKey(0):表示无限期地等待任何键盘按键。这种用法常见于图像显示窗口中,确保图像在窗口中显示直到用户决定关闭它。
-
cv.waitKey(n):n>0,意味着程序将等待n毫秒。这种方式常用于视频播放或实时摄像头捕获场景,以便控制每一帧停留的时间,同时允许用户通过按键来中断循环或发出命令。
-
-
cv2.destroyAllWindows():会在当前程序执行到该语句时立即销毁打开的窗口,并释放与这些窗口相关的资源。 -
winname:窗口名,关闭指定名称的窗口。可省略,销毁所有已打开的窗口。
4.4 保存图像
-
cv2.imwrite(path,img)
参数:
-
path:图片保存的路径和图片名
-
img:要保存的图像
-
#cv.imwrite(path,img)
#path;保存的路径和图片名,img:要保存的图片
cv.imwrite('./girl2.png',img2)
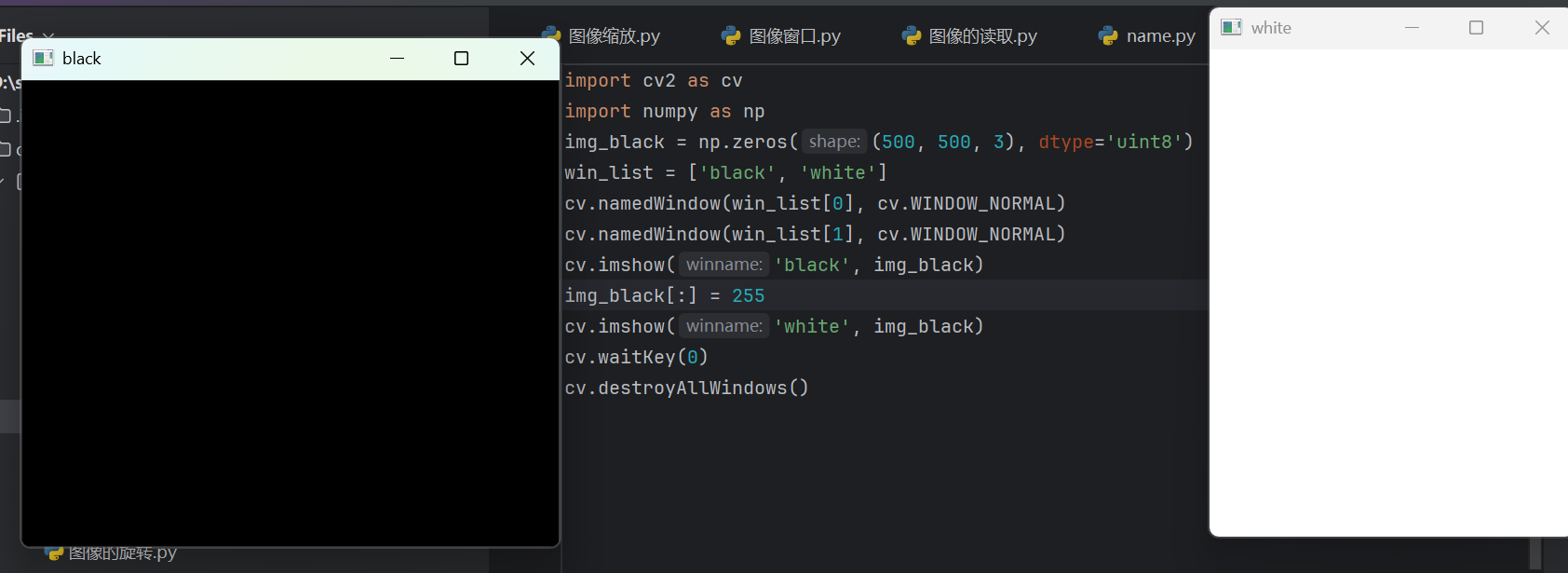
4.5 创建黑白图像
-
使用
np.zeros()创建全黑图像,再修改像素值成为全白图像。-
numpy.zeros((height,width,channels),dtype=np. uint8)
-
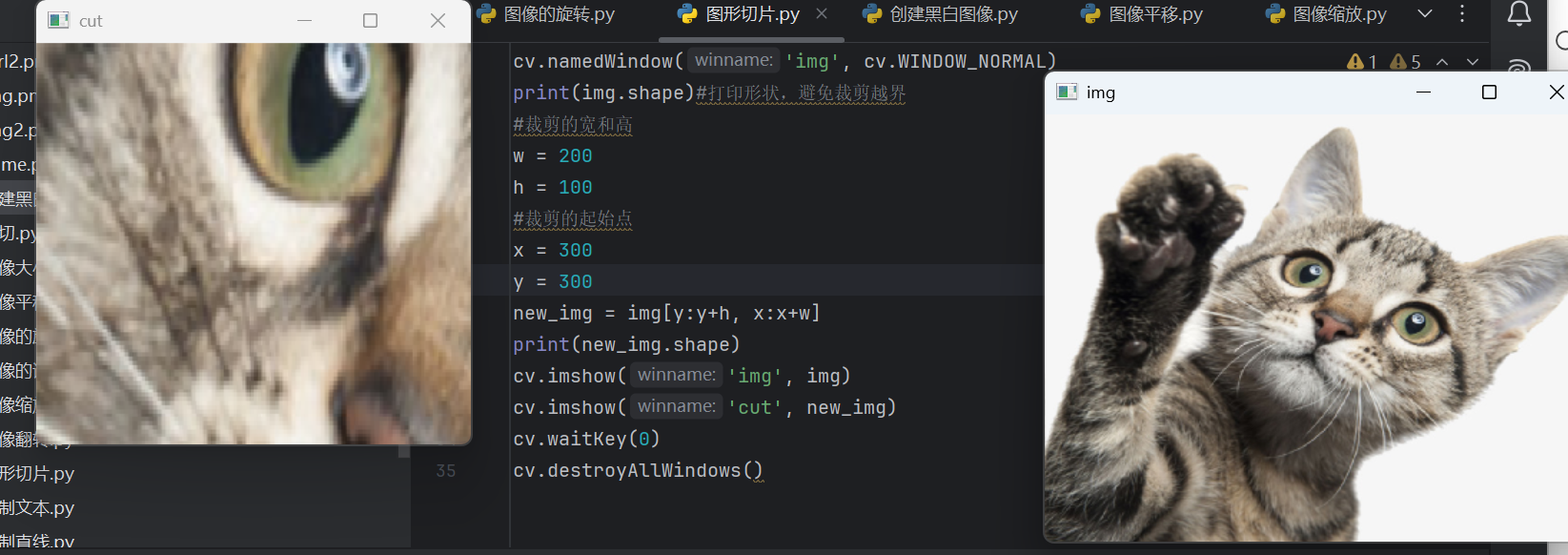
4.6 图像切片(图片剪裁)
-
Opencv中,图像切片用于从图像中提取一个子区域(矩形区域)。
-
假设你有一个图像
img,它的类型是numpy.ndarray。img[y:y+h,x:x+w]的含义如下:-
x:子区域左上角的x坐标
-
y:子区域左上角的y坐标
-
w:子区域的宽度
-
h:子区域的高度
-
-
切片操作
-
img[y:y+h,x:x+w]提取的是从(x,y)开始,高度为h,宽度为w的矩形区域
-
4.7 图像大小调整
-
cv2.resize是Opencv库中用于调整图像大小的函数,在图像处理中很常用,特别是在要对图像进行缩放以适应不同需求时。 -
cv2.resize(img,dsize)
-
img:输入图像,通常是二维或三位NumPy数组。
-
dsize:输出图像的尺寸,是一个二元组
(w,h),
-
# cv.imshow('r_img',r_img)
# cv.waitKey(0)
# cv.destroyAllWindows()
import cv2 as cv
import numpy as np
img = cv.imread('girl.png')
print(img.shape)
img1 = cv.resize(img,(500,500))
print(img1.shape)
cv.imshow('girl',img)
cv.imshow('girl1',img1)
cv.waitKey(0)
cv.destroyAllWindows()
5 图像绘制
5.1 绘制直线
-
cv2.line(img,sart,end,color,thickness)
-
参数
-
img:要绘制直线的图像
-
start、end:直线的起点和终点
-
color:直线的颜色(对于彩色图像,使用 BGR 格式指定颜色)
-
thickness:线条宽度
-
5.2 绘制圆形
-
cv2.circle(img,centerpoint,r,color,thickness)
-
参数:
-
img:要绘制圆形的图片
-
centerpoint、r:圆心和半径
-
color:线条颜色
-
tnickness:线条宽度,为-1时生成闭合图案并填充颜色
-
5.3 绘制矩形
-
cv2.rectangle(img,leftupper,rightdown,color,thickness)
-
参数:
-
img:要绘制矩形的图像
-
leftupper、rightdown:矩形的左上角和右下角坐标
-
color:线条的颜色
-
thickness:线条的宽度
-
5.4 绘制文本(向图片中添加文字)
-
cv2.putText(img,text,station,font,Fontscale,color,thickness,cv2.LINE_AA)
-
参数:
-
img:要添加文字的图像
-
text:要写入的文本数据
-
station:文本的放置位置
-
font:字体样式
-
Fontscale:字体大小
-
thickness:字体线条宽度
-
cv2.LINE_AA:使用反走样技术绘制文本边框
-
反走样是一种提高图形质量的技术,通过混合颜色和像素边缘来减少锯齿状效果,使文本看起来更加平滑、清晰。
-
Opencv中,相较于cv2.LINE_8(默认值),cv2.LINE_AA能提供更好的视觉效果,特别是在文本较小或者需要高精度显示的情况下。
-
-
5.5 读取视频
-
cap = cv2.VideoCapture(path)
-
path:视频流资源路径设置为0,代表从默认摄像头捕获视频流
-
-
ret,frame = cap.read()
-
返回值cap调用read()方法得到一个布尔值和一帧图像,布尔值表示是否成功读取到帧,如果为False,可能是因为视频结束或读取失败,如果为True,frame则是当前帧的图像数据。
-
捕获摄像头的实时视频流
import cv2 as cv
cap = cv.VideoCapture('001.mp4')
#循环读取每一帧,ret 布尔,frame帧
while True:
cv.namedWindow('frame', cv.WINDOW_NORMAL)
ret, frame = cap.read()
if not ret:
print('error')
break
else:
cv.imshow('frame', frame)
if cv.waitKey(40) & 0xFF == ord('q'):#&0xFF为了屏蔽高位,留下第八位的键位。
break
cap.release() #释放摄像头资源
cv.destroyAllWindows()#销毁窗口
图像预处理
1 图像翻转(图片镜像旋转)
在OpenCV中,图片的镜像旋转是以图像的中心为原点进行镜像翻转的。
-
cv2.flip(img,flipcode)
-
参数
-
img: 要翻转的图像
-
flipcode: 指定翻转类型的标志
-
flipcode=0: 垂直翻转,图片像素点沿x轴翻转,像素点坐标(x,y)-->(x,-y)
-
flipcode>0: 水平翻转,图片像素点沿y轴翻转,像素点坐标(x,y)-->(-x,y)
-
flipcode<0: 水平垂直翻转,水平翻转和垂直翻转的结合,像素点坐标(x,y)-->(-x,-y)
-
import cv2 as cv #cv.flip(img,指定翻转的类型的标准) #=0垂直 #>0;水平 #<0:水平加垂直 img = cv.imread('img.png') #垂直翻转 cv.namedWindow('img', cv.WINDOW_NORMAL) cv.namedWindow('img_s', cv.WINDOW_NORMAL) cv.namedWindow('img_c', cv.WINDOW_NORMAL) img_c=cv.flip(img,0) img_s = cv.flip(img,1) img_cs=cv.flip(img,-1) cv.imshow('img_s',img_s) cv.imshow('img',img) cv.imshow('img_c',img_c) cv.imshow('img_cs',img_cs) cv.waitKey(0) cv.destroyAllWindows()2 图像仿射变换
仿射变换(Affine Transformation)是一种线性变换,保持了点之间的相对距离不变。
-
-
仿射变换的基本性质
-
保持直线:变换后的直线仍然是直线。
-
保持平行:平行的直线在变换后依然保持平行。
-
比例不变性:直线上两点之间的距离比例在变换后保持不变。
-
不保持角度和长度:不同于等距变换,仿射变换一般不保持角度大小和线段的实际长度。
-
-
常见的仿射变换类型
-
旋转:绕着某个点或轴旋转一定角度。
-
平移:仅改变物体的位置,不改变其形状和大小。
-
缩放:改变物体的大小。
-
剪切:使物体发生倾斜变形。
-
-
仿射变换的基本原理
-
线性变换
-
二维空间中,图像点坐标为(x,y),仿射变换的目标是将这些点映射到新的位置 (x', y')。
-
为了实现这种映射,通常会使用一个矩阵乘法的形式:
-
(类似于y=kx+b)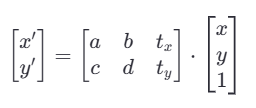
-
x'=ax+by+tx
-
a,b,c,d 是线性变换部分的系数,控制旋转、缩放和剪切。
-
t_x,t_y 是平移部分的系数,控制图像在平面上的移动。
-
输入点的坐标被扩展为齐次坐标形式[x,y,1],以便能够同时处理线性变换和平移
-
-
cv2.getRotationMatrix2D()函数
-
获取旋转矩阵
cv2.getRotationMatrix2D(center,angle,scale)
-
-
-
center:旋转中心点的坐标,格式为
(x,y)。 -
angle:旋转角度,单位为度,正值表示逆时针旋转负值表示顺时针旋转。
-
scale:缩放比例,若设为1,则不缩放。
-
返回值:M,2x3的旋转矩阵。
-
-
cv2.warpAffine()函数
-
仿射变换函数
cv2.warpAffine(img,M,dsize)
-
img:输入图像。
-
M:2x3的变换矩阵,类型为
np.float32。 -
dsize:输出图像的尺寸,形式为
(width,height)。
通过变换矩阵和变换函数我们可以的到新的图片
2.1 图像旋转
旋转图像可以将图像绕着某个点旋转一定的角度。
import cv2 as cv
img = cv.imread('img.png')
#获取图像尺寸
h,w,_ = img.shape
#旋转中心
center = (w//2, h//2)
#获取旋转矩阵
M = cv.getRotationMatrix2D(center,45,0.5)
#仿射变换函数
new_img = cv.warpAffine(img,M,(w,h))
cv.imshow('img',img)
cv.imshow('new_img',new_img)
cv.waitKey(0)
cv.destroyAllWindows()
2.2 图像平移
移操作可以将图像中的每个点沿着某个方向移动一定的距离。
-
假设我们有一个点 P(x,y),希望将其沿x轴方向平移t_x*个单位,沿y轴方向平移t_y个单位到新的位置P′(x′,y′),那么平移公式如下:
x′=x+tx
y′=y+ty
在矩阵形式下,该变换可以表示为:
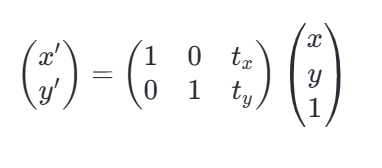
在原来基础上x加上偏移量,y加上偏移量
import cv2 as cv
import numpy as np
img = cv.imread('img.png')
#图像平移:位置变大小不变
#获取图像尺寸
h , w = img.shape[:2]
#创建平移矩阵,计算像素点新的坐标
#定义平移的距离
tx = 100
ty = 50
#定义平移矩阵
M=np.float32([[1,0,tx],[0,1,ty]])
#仿射变换函数平移
new_img = cv.warpAffine(img,M,(w,h))
cv.imshow('img',img)
cv.imshow('new_img',new_img)
cv.waitKey(0)
cv.destroyAllWindows()
2.3 图像缩放
缩放操作可以改变图片的大小。
-
假设要把图像的宽高分别缩放为0.5和0.8,那么对应的缩放因子sx=0.5,sy=0.8。
-
点P(x,y)对应到新的位置P′(x′,y′),缩放公式为:
import cv2 as cv
import numpy as np
img = cv.imread('img.png')
#获取尺寸
h, w,_ = img.shape
#定义缩放矩阵
x = 0.8
y = 0.8
new_x = int(w*x)
new_y = int(h*y)
M = np.float32([[x,0,0],[0,y ,0]])
new_img = cv.warpAffine(img, M, (new_x, new_y))
cv.imshow('img', img)
cv.imshow('new_img', new_img)
cv.waitKey(0)
cv.destroyAllWindows()
注意在获取尺寸时img.shape返回的是h,w不是w,h。在应用映射函数时,如果不想新的图片有黑影,新图片的输出desize()也要更改。
2.4 图像剪切
剪切操作可以改变图形的形状,以便其在某个方向上倾斜,它将对象的形状改变为斜边平行四边形,而不改变其面积。
-
想象我们手上有一张矩形纸片,如果你固定纸片的一边,并沿着另一边施加一个平行于该边的力,这张纸片就会变形为一个平行四边形。这就是剪切变换的一个直观解释。
-
对于二维空间中的点P(x,y),对他进行剪切变换:
沿x轴剪切:x'=x+sh_y*y y'=y
沿y轴剪切:x'=x y'=sh_x*x+y
-
当需要同时沿两个方向进行剪切时,x'=x+sh_y*y , y'=sh_x*x+y
-
在矩阵形式下,该变换可以表示为:
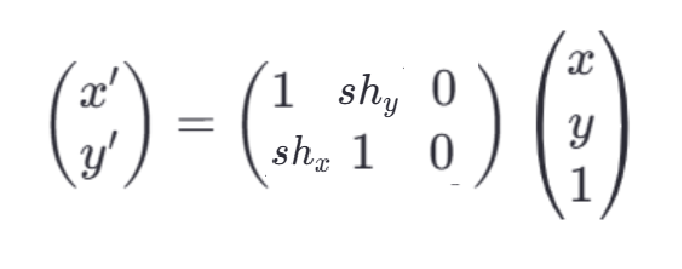 口诀,沿什么轴剪切那么那个轴就变,另一个不变,两个轴剪切,那么都变。
口诀,沿什么轴剪切那么那个轴就变,另一个不变,两个轴剪切,那么都变。
import cv2 as cv
import numpy as np
img = cv.imread('img.png')
print(img.shape)
#获取宽高
h,w = img.shape[:2]
#定义剪切因子
shx = 0.5#垂直方向的剪切因子
shy = 0.8#水平方向的剪切因子
#定义剪切矩阵
cv.namedWindow('img_w', cv.WINDOW_NORMAL)
M=np.float32([[1,shy,0],[0,1,0]])#只做水平剪切
M1= np.float32([[1,0,0],[shx,1,0]])#只做垂直剪切
M2= np.float32([[1,shy,0],[shx,1,0]])#水平垂直都做
#剪切
img_w = cv.warpAffine(img,M,(w,h))
print(img_w.shape)
cv.imshow('img',img)
cv.imshow('img_w',img_w)
cv.waitKey(0)
cv.destroyAllWindows()
3 插值方法
在图像处理和计算机图形学中,插值(Interpolation)是一种通过已知数据点之间的推断或估计来获取新数据点的方法。它在图像处理中常用于处理图像的放大、缩小、旋转、变形等操作,以及处理图像中的像素值。
图像插值算法是为了解决图像缩放或者旋转等操作时,由于像素之间的间隔不一致而导致的信息丢失和图像质量下降的问题。当我们对图像进行缩放或旋转等操作时,需要在新的像素位置上计算出对应的像素值,而插值算法的作用就是根据已知的像素值来推测未知位置的像素值。
3.1 最近邻插值
CV2.INTER_NEAREST
首先给出目标点与原图像点之间坐标的计算公式:

通俗的讲,该公式就是让目标图像中的每个像素值都能找到对应的原图中的像素值,这样才能根据不同的插值方法来获取新的像素值。根据该公式,我们就可以得到每一个目标点所对应的原图像的点,比如一个2*2的图像放大到4*4,如下图所示,其中红色的为每个像素点的坐标,黑色的则表示该像素点的像素值。
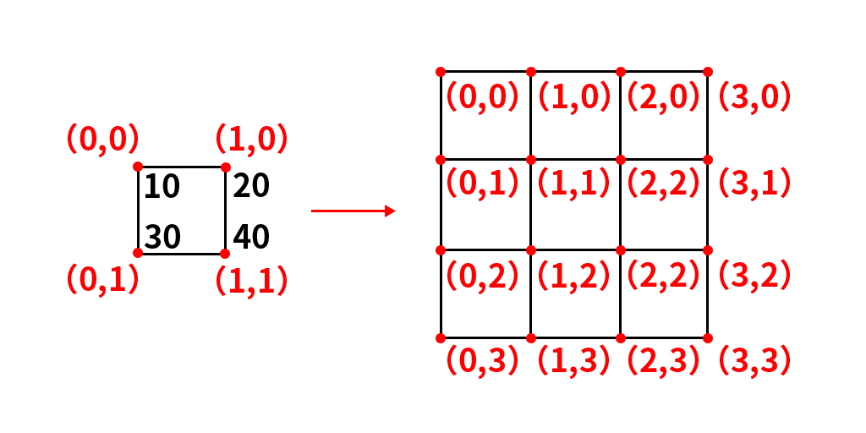 那么根据公式我们就可以计算出放大后的图像(0,0)点对应的原图像中的坐标为:
那么根据公式我们就可以计算出放大后的图像(0,0)点对应的原图像中的坐标为:
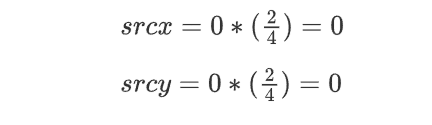
本质是放大后肯定会多出像素点,而多出来的像素点我们应该怎样取像素值才能保证我们的新图和原图最大程度相同。不同的方法精确度不同。最近邻插值法精确度就没有那么高。
3.2 双线性插值
CV2.INTER_LINEAR
双线性插值是一种图像缩放、旋转或平移时进行像素值估计的插值方法。当需要对图像进行变换时,特别是尺寸变化时,原始图像的某些像素坐标可能不再是新图像中的整数位置,这时就需要使用插值算法来确定这些非整数坐标的像素值。
双线性插值的工作原理是这样的:
-
假设要查找目标图像上坐标为
(x', y')的像素值,在原图像上对应的浮点坐标为(x, y)。 -
在原图像上找到四个最接近
(x, y)的像素点,通常记作P00(x0, y0),P01(x0, y1),P10(x1, y0),P11(x1, y1),它们构成一个2x2的邻域矩阵。 -
分别在水平方向和垂直方向上做线性插值:
-
水平方向:根据
x与x0和x1的关系计算出P00和P10、P01和P11之间的插值结果。 -
垂直方向:将第一步的结果与
y与y0和y1的关系结合,再在垂直方向上做一次线性插值。
-
综合上述两次线性插值的结果,得到最终位于
(x', y')处的新像素的估计值。 -
比如我们根据上述公式计算出了新图像中的某点所对应的原图像的点P,其周围的点分别为Q12、Q22、Q11、Q21, 要插值的P点不在其周围点的连线上,这时候就需要用到双线性插值了。首先延申P点得到P和Q11、Q21的交点R1与P和Q12、Q22的交点R2,如下图所示:
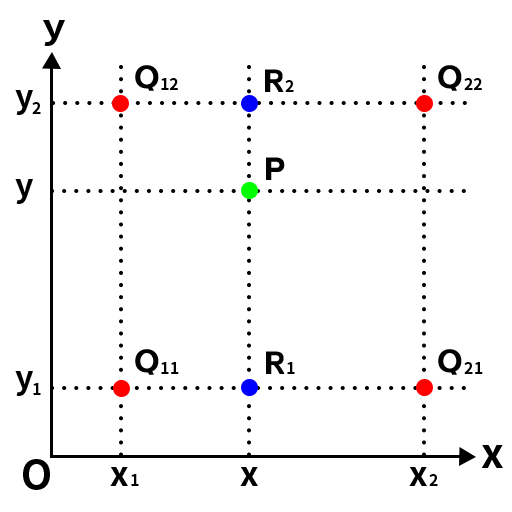
然后根据Q11、Q21得到R1的插值,根据Q12、Q22得到R2的插值,然后根据R1、R2得到P的插值即可,这就是双线性插值。以下是计算过程:
首先计算R1和R2的插值:
 其实可以这样理解,我目标点映射在原坐标,我距离谁越近,我是不是应该多取点他的像素值,距离越远我取的像素值比例越低。距离和值成反比。有点像线段法混合溶液问题。通过双线性插值法,大大提高了精确度。
其实可以这样理解,我目标点映射在原坐标,我距离谁越近,我是不是应该多取点他的像素值,距离越远我取的像素值比例越低。距离和值成反比。有点像线段法混合溶液问题。通过双线性插值法,大大提高了精确度。
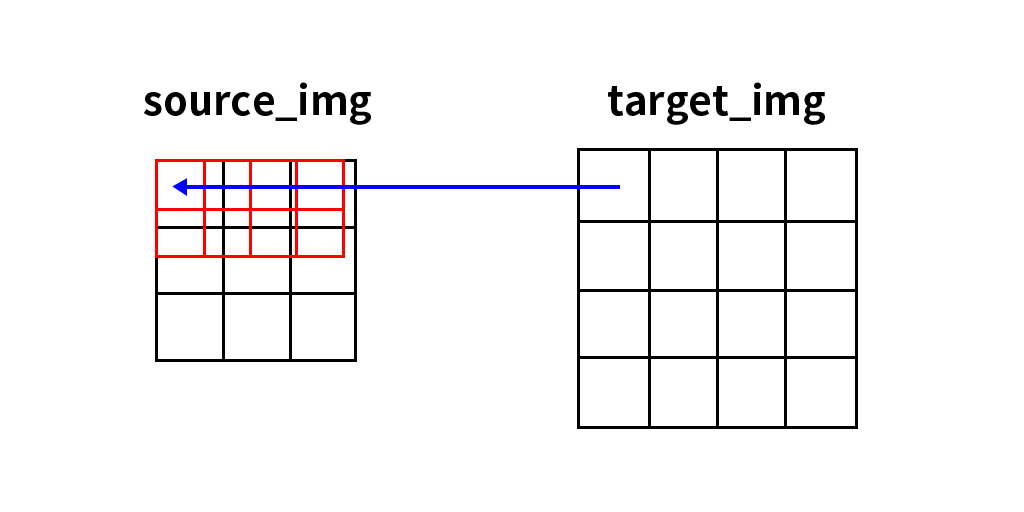
双线性插值的对应关系看似比较清晰,但还是有2个问题。首先是根据坐标系的不同,产生的结果不同,这张图是左上角为坐标系原点的情况,我们可以发现最左边x=0的点都会有概率直接复制到目标图像中(至少原点肯定是这样),而且就算不和原图像中的点重合,也相当于进行了1次单线性插值(带入到权重公式中会发现结果)。
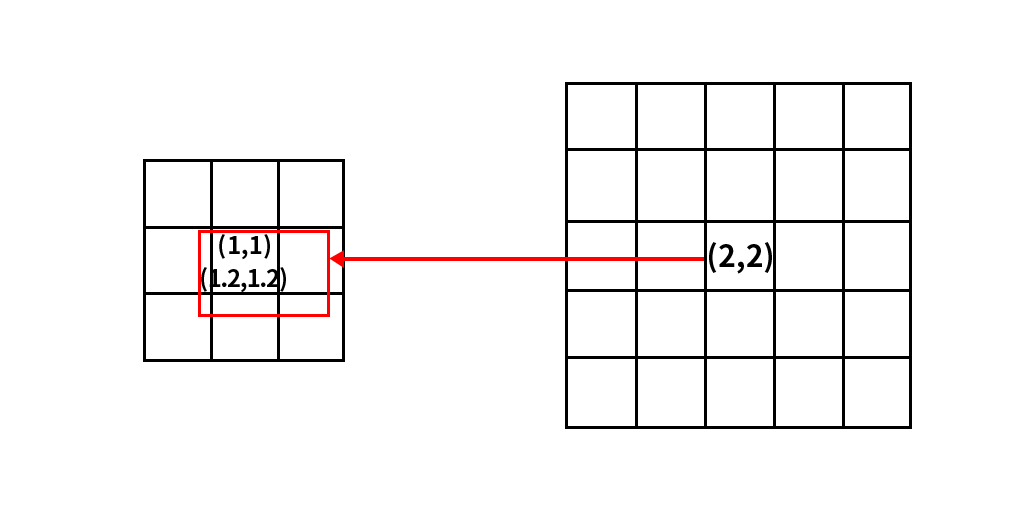
第二个问题时整体的图像相对位置会发生变化。如下图所示,左侧是原图像(3,3),右侧是目标图像(5,5),原图像的几何中心点是(1,1),目标图像的几何中心点是(2,2),根据对应关系,目标图像的几何中心点对应的原图像的位置是(1.2,1.2),那么问题来了,目标图像的原点(0,0)和原始图像的原点是重合的,但是目标图像的几何中心点相对于原始图像的几何中心点偏右下,那么整体图像的位置会发生偏移,所以参与计算的点相对都往右下偏移会产生相对的位置信息损失。这是第二个问题。


















 1667
1667

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









