









 本文从实际理解出发,阐述L1和L2正则化的概念,通过简化公式和实例,解释为何在机器学习中使用它们,以及如何通过拉格朗日乘子将正则化融入深度学习模型优化。重点讲解了L1正则化如何导致稀疏模型和L2正则化的平滑效果,配以直观图形帮助理解。
本文从实际理解出发,阐述L1和L2正则化的概念,通过简化公式和实例,解释为何在机器学习中使用它们,以及如何通过拉格朗日乘子将正则化融入深度学习模型优化。重点讲解了L1正则化如何导致稀疏模型和L2正则化的平滑效果,配以直观图形帮助理解。
看了好多关于L1、L2 正则化的文章,大多讲的比较正规(一堆数学公式),今天我就从自己的理解角度谈谈我对L1、L2正则化的理解
1、为啥要谈L1、L2 正则化,因为我发现学机器学习和深度学习都避免不了,人家会说正则化,会用一些正则化优化的策略,并且自己还不怎么懂
2、当然学这些避免不了一些基础的公式比如:
- L1 正则化公式 f ( w ) = ∣ w 1 ∣ + ∣ w 2 ∣ + ∣ w 3 ∣ + ∣ w 4 ∣ + . . . . . . f(w) = |w_1|+|w_2|+|w_3|+|w_4| + ...... f(w)=∣w1∣+∣w2∣+∣w3∣+∣w4∣+...... 也就是绝对值之和
- L2正则化公式
f
(
w
)
=
w
1
2
+
w
2
2
+
w
3
2
+
w
4
2
+
.
.
.
.
.
.
f(w) =\sqrt{ w_1^2+w_2^2+w_3^2+w_4^2+...... }
f(w)=w12+w22+w32+w42+......也就是距离公式 为啥没写成
(
x
1
−
y
1
)
2
(x_1-y_1)^2
(x1−y1)2 这种形式,因为深度学习当中我们只关注w即权重所以,要转变下思想(穿个马甲出来也要认识它)
为了简单起见我们只取 w 1 , w 2 w_1,w_2 w1,w2 所以
L1正则化的公式 f ( w ) = ∣ w 1 ∣ + ∣ w 2 ∣ f(w)=|w_1|+|w_2| f(w)=∣w1∣+∣w2∣ 图像为:
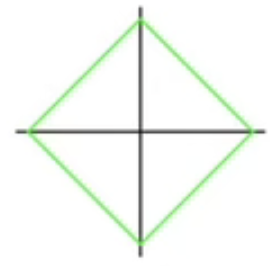
L2 正则化的公式 f ( w ) = w 1 2 + w 2 2 f(w) = w_1^2+w_2^2 f(w)=w12+w22图像为:
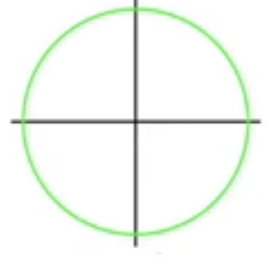
- 拉格朗日数乘公式:
f
(
w
1
,
w
2
,
λ
)
=
f
(
w
1
,
w
2
)
+
λ
ϕ
(
w
1
,
w
2
)
f(w_1,w_2,\lambda) = f(w_1,w_2)+\lambda\phi(w_1,w_2)
f(w1,w2,λ)=f(w1,w2)+λϕ(w1,w2) 虽然这里边只有
w
1
,
w
2
w_1,w_2
w1,w2但是可以搬到高维上且
f
(
w
1
,
w
2
)
f(w_1,w_2)
f(w1,w2)展开后也是包含平方项的所以这个公式就和我们做深度学习求损失的公式很像了(深度学习求损失的公式一般用均方误差来算)比如YOLOV1中的公式(看不懂不重要,重要的是理解求损失是用平方差求的即可)
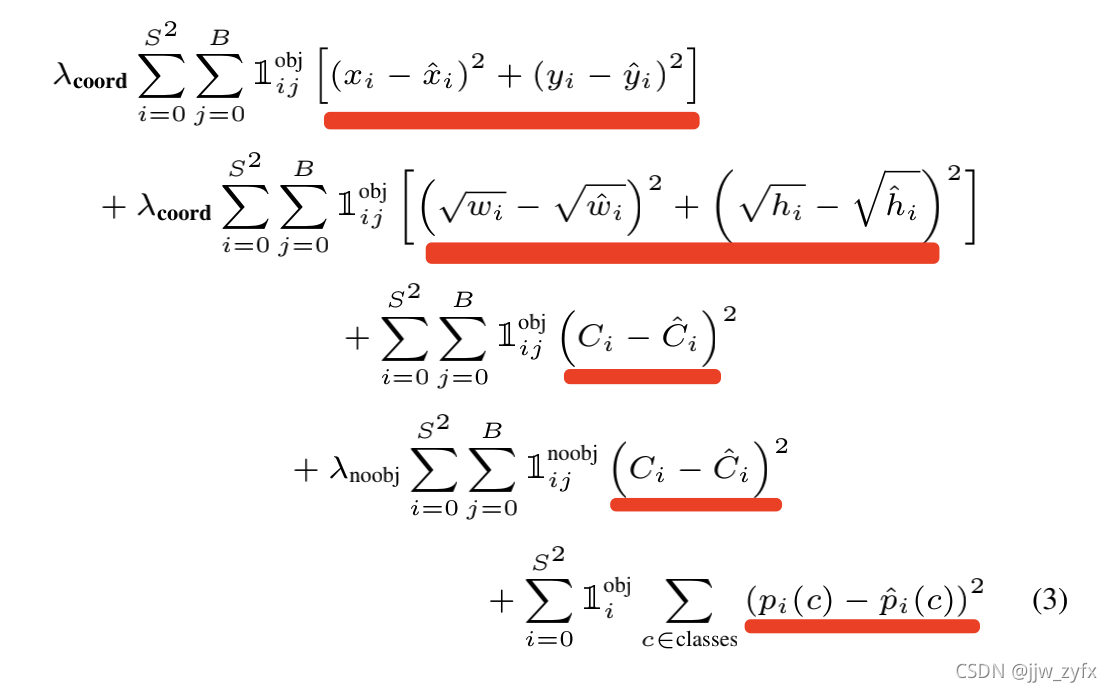
所以为了在深度学习中求得最小损失就尽量构造拉格朗日数乘公式。即把拉格朗日数乘公式中的 f ( w 1 , w 2 ) f(w_1,w_2) f(w1,w2)作为深度学习中的损失函数的一部分,把拉格朗日中的 λ ϕ ( w 1 , w 2 ) \lambda\phi(w_1,w_2) λϕ(w1,w2)用L1正则或L2正则替换(也就是在L1,L2正则前乘以 λ \lambda λ)然后根据拉格朗日数乘求解各个参数使得值最优
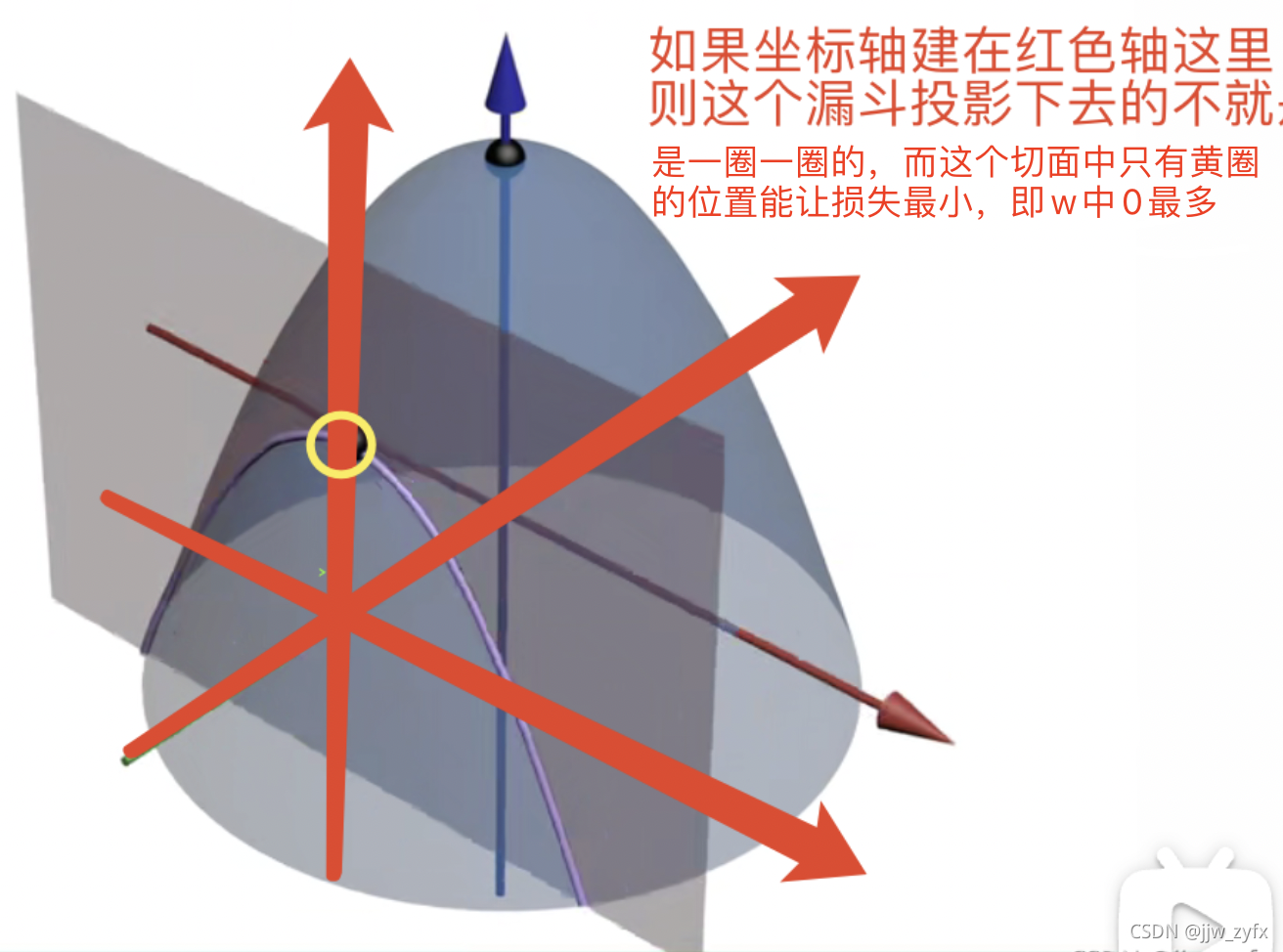
3对于下图的理解
- L1正则化图
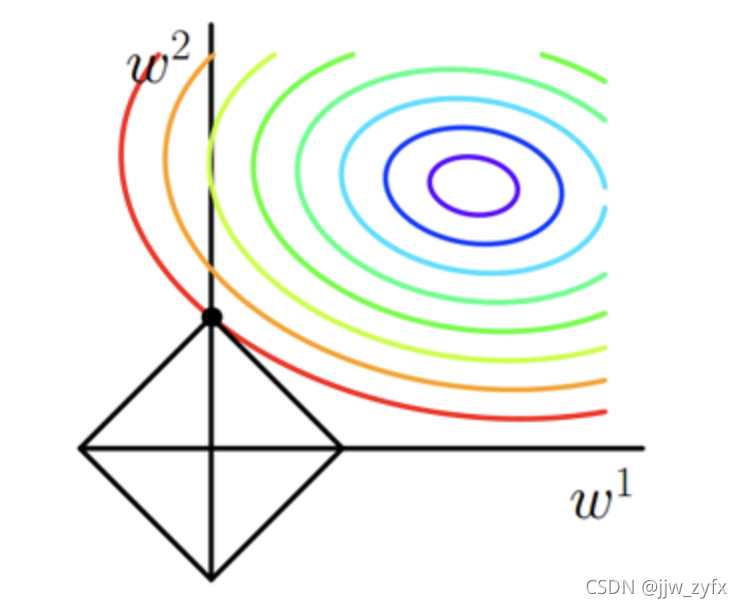
对于上边这个图,也是他们常用来解释为啥L1正则化能稀疏模型、这个图我刚开始也没看明白为啥最上边的那个交点能稀疏模型,对于稀疏模型,大致意思就是让权重w尽可能多的为零,即在 y = w 1 x + w 2 x 2 + w 3 x 3 + . . . y=w_1x+w_2x^2+w_3x^3+... y=w1x+w2x2+w3x3+...中的w如果有很多0则公式不就简单多了,也就是说模型不就简单多了,这样可以仅使用有价值的特征,所以可以达到特征选择的目的,但是如何让w为0,只有当w在坐标轴上的时候0才最多(需要注意的是上图是个二维图,不是3D,并且不是以彩色图形为中心建立的)这就需要发挥你的想象力虽然下图不是上图的原图,但是可以借鉴
- L2正则化图
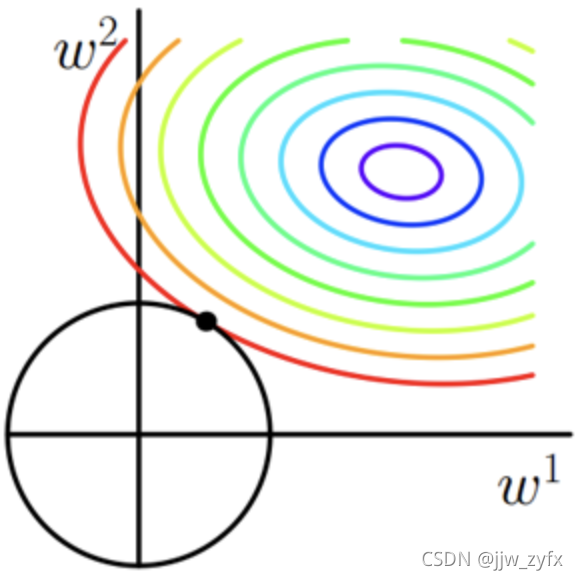
对于L2正则化图不容易将w落在坐标轴上,但是只要相切就可以让w权重变小,w越小模型也越简单
其他的可以参考另一篇博客点击进入

















 7453
7453

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









