




 软件环境
软件环境
Druid Starter官方网址:https://github.com/alibaba/druid/tree/master/druid-spring-boot-starter
Druid帮助文档:https://github.com/alibaba/druid/wiki/%E9%A6%96%E9%A1%B5
Druid源代码工程:https://github.com/alibaba/druid
Druid官方文档
https://github.com/alibaba/druid/wiki
Druid配置文档
https://github.com/alibaba/druid/wiki/DruidDataSource配置属性列表
Druid最佳实践
https://github.com/alibaba/druid/wiki/DruidDataSource配置
摘要
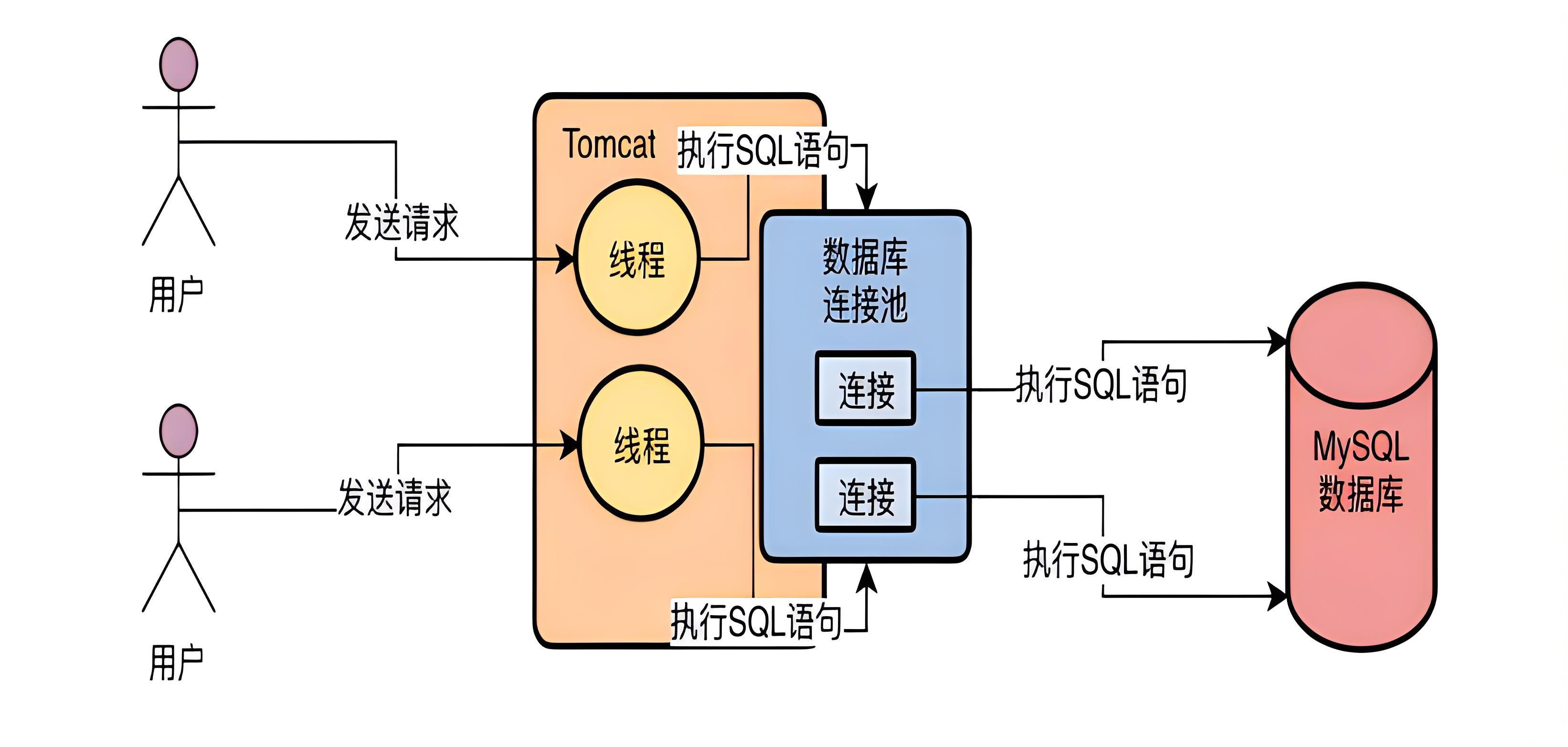
Druid数据源指标监控分数据采集和指标告警,是指通过开发java代码获取应用的Druid数据源指标并暴露到应用的指标端点,然后通过普米等监控工具拉取该指标,然后通过alert-manager、n9e等告警工具配置域值从而实现告警和监控的能力。
本文亮点
1、实现了一般的Druid数据源监控,
2、还额外支持tomcat内置JNDI做为底层数据源的Druid数据源监控
3、如需实现HikariCP数据源指标采集只需改一下代码中的指标名即可(代码可复用)
特别说明
Springboot2的较新版本自带HikariCP且默认HikariCP,且不需要额外开发,自带此类监控指标。如果需要附加其他指标tag(属性)可参考此文稍作修改。
标签
JNDI数据源指标监控、Druid指标监控、HikariCP指标监控
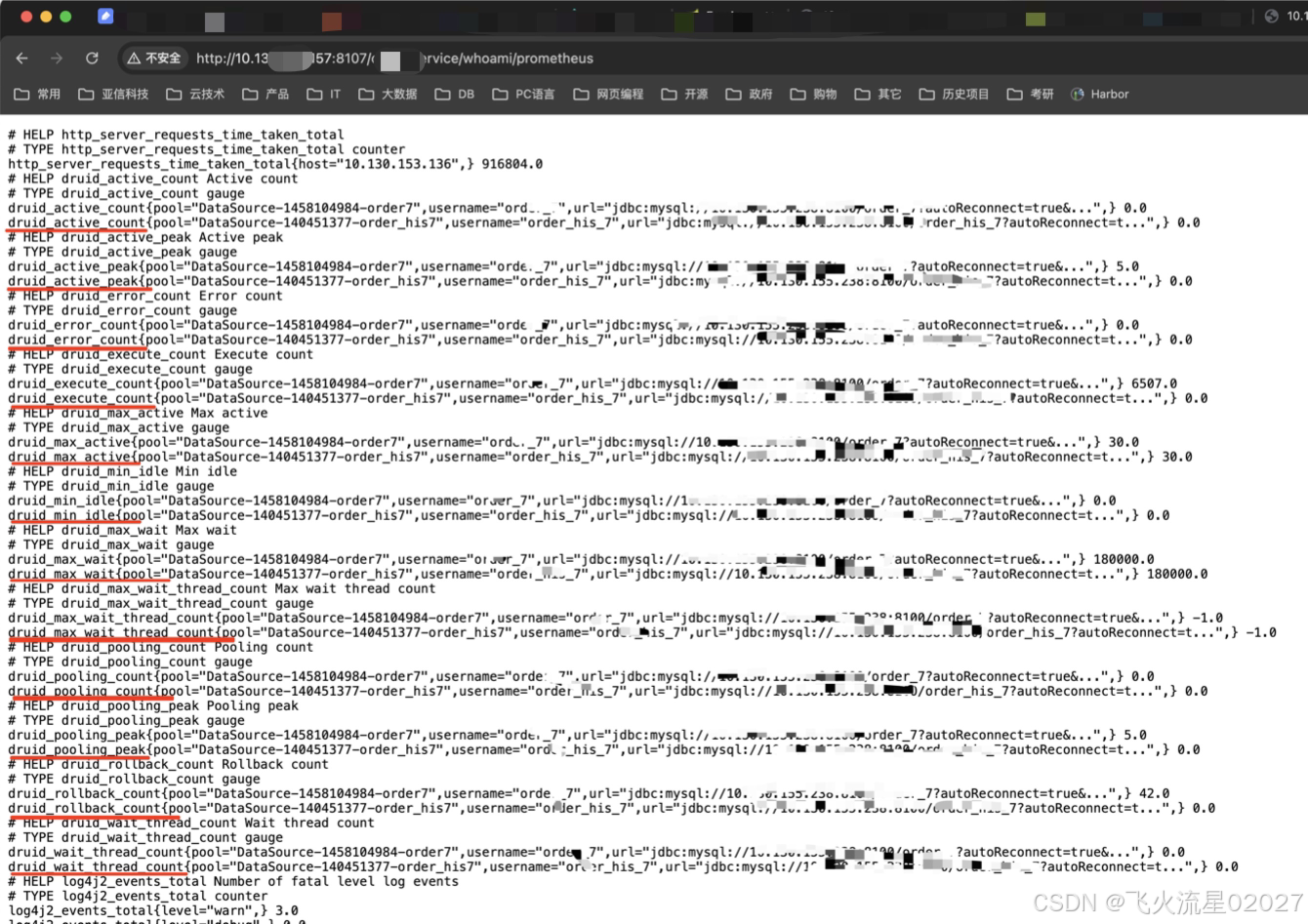
一、效果图
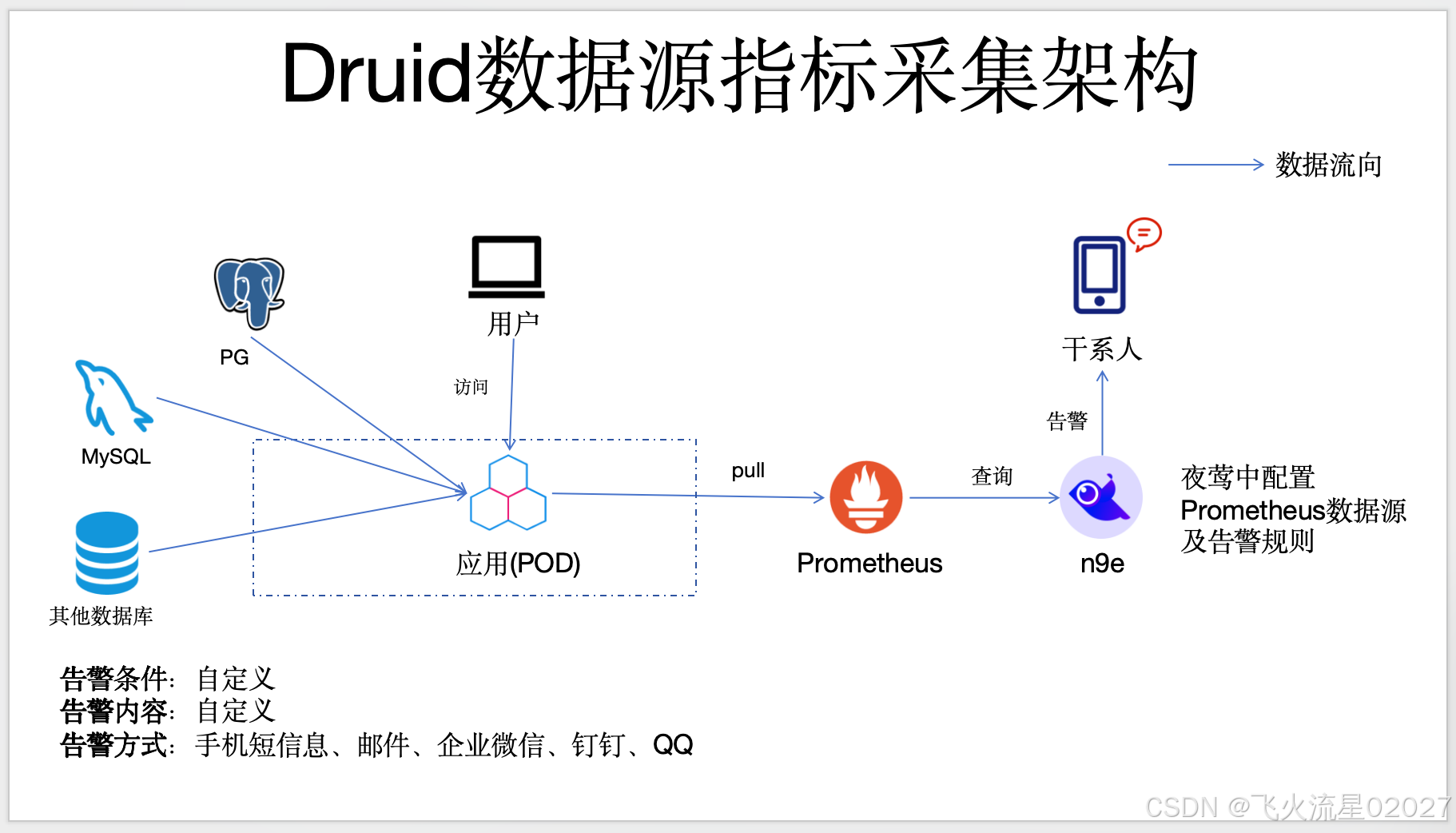
二、数据流图/组件架构图
三、代码
1、Druid数据源指标配置类
package person.daizhongde.common.monitor.druid;
import person.daizhongde.datasources.DynamicDataSource;// AbstractRoutingDataSource 的实现类,用于支持Druid代理tomcat JNDI数据源
import com.alibaba.druid.pool.DruidDataSource;
import io.prometheus.client.CollectorRegistry;
import lombok.extern.slf4j.Slf4j;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.autoconfigure.condition.Condit 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 4096
4096

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











