




在大规模数据存储中,实现索引查询这样一个实际背景下,树节点存储的元素数量是有限的(如果元素数量非常多的话,查找就退化成节点内部的线性查找了),这样导致二叉查找树结构由于树的深度过大而造成磁盘I/O读写过于频繁,进而导致查询效率低下(为什么会出现这种情况,待会在外部存储器-磁盘中有所解释),那么如何减少树的深度(当然是不能减少查询的数据量),一个基本的想法就是:采用多叉树结构(由于树节点元素数量是有限的,自然该节点的子树数量也就是有限的)。
也就是说,因为磁盘的操作费时费资源,如果过于频繁的多次查找势必效率低下。那么如何提高效率,即如何避免磁盘过于频繁的多次查找呢?根据磁盘查找存取的次数往往由树的高度所决定,所以,只要我们通过某种较好的树结构减少树的结构尽量减少树的高度,那么是不是便能有效减少磁盘查找存取的次数呢?那这种有效的树结构是一种怎样的树呢?
这样我们就提出了一个新的查找树结构——多路查找树。根据平衡二叉树的启发,自然就想到平衡多路查找树结构,也就是这篇文章所要阐述的第一个主题B~tree,即B树结构(后面,我们将看到,B树的各种操作能使B树保持较低的高度,从而达到有效避免磁盘过于频繁的查找存取操作,从而有效提高查找效率)。
B树
B-tree(B-tree树即B树,B即Balanced,平衡的意思)这棵神奇的树是在Rudolf Bayer, Edward M. McCreight(1970)写的一篇论文《Organization and Maintenance of Large Ordered Indices》中首次提出的(wikipedia中:http://en.wikipedia.org/wiki/B-tree,阐述了B-tree名字来源以及相关的开源地址)。在开始介绍B~tree之前,先了解下相关的硬件知识,才能很好的了解为什么需要B~tree这种外存数据结构。
磁盘读取数据是以盘块(block)为基本单位的。位于同一盘块中的所有数据都能被一次性全部读取出来。而磁盘IO代价主要花费在查找时间上。因此我们应该尽量将相关信息存放在同一盘块,同一磁道中。或者至少放在同一柱面或相邻柱面上,以求在读/写信息时尽量减少磁头来回移动的次数,避免过多的查找时间。所以,在大规模数据存储方面,大量数据存储在外存磁盘中,而在外存磁盘中读取/写入块(block)中某数据时,首先需要定位到磁盘中的某块,如何有效地查找磁盘中的数据,需要一种合理高效的外存数据结构,就是下面所要重点阐述的B-tree结构,以及相关的变种结构:B+-tree结构和B*-tree结构。
B 树是为了磁盘或其它存储设备而设计的一种多叉(下面你会看到,相对于二叉,B树每个内结点有多个分支,即多叉)平衡查找树。与本blog之前介绍的红黑树很相似,但在降低磁盘I/0操作方面要更好一些。许多数据库系统都一般使用B树或者B树的各种变形结构,如下文即将要介绍的B+树,B*树来存储信息。
B树与红黑树最大的不同在于,B树的结点可以有许多子女,从几个到几千个。那为什么又说B树与红黑树很相似呢?因为与红黑树一样,一棵含n个结点的B树的高度也为O(lgn),但可能比一棵红黑树的高度小许多,应为它的分支因子比较大。所以,B树可以在O(logn)时间内,实现各种如插入(insert),删除(delete)等动态集合操作。
如下图所示,即是一棵B树,一棵关键字为英语中辅音字母的B树,现在要从树种查找字母R(包含n[x]个关键字的内结点x,x有n[x]+1]个子女(也就是说,一个内结点x若含有n[x]个关键字,那么x将含有n[x]+1个子女)。所有的叶结点都处于相同的深度,带阴影的结点为查找字母R时要检查的结点):

相信,从上图你能轻易的看到,一个内结点x若含有n[x]个关键字,那么x将含有n[x]+1个子女。如含有2个关键字D H的内结点有3个子女,而含有3个关键字Q T X的内结点有4个子女。
B树的定义,从下文中,你将看到,或者是用阶,或者是用度,如下段文字所述:
Unfortunately, the literature on B-trees is not uniform in its use of terms relating to B-Trees. (Folk & Zoellick 1992, p. 362) Bayer & McCreight (1972), Comer (1979), and others define the order of B-tree as the minimum number of keys in a non-root node. Folk & Zoellick (1992) points out that terminology is ambiguous because the maximum number of keys is not clear. An order 3 B-tree might hold a maximum of 6 keys or a maximum of 7 keys. (Knuth 1998,TAOCP p. 483) avoids the problem by defining the order to be maximum number of children (which is one more than the maximum number of keys).

from: http://en.wikipedia.org/wiki/Btree#Technical_description。
用阶定义的B树
B 树又叫平衡多路查找树。一棵m阶的B 树 (注:切勿简单的认为一棵m阶的B树是m叉树,虽然存在四叉树,八叉树,KD树,及vp/R树/R*树/R+树/X树/M树/线段树/希尔伯特R树/优先R树等空间划分树,但与B树完全不等同)的特性如下:
-
树中每个结点最多含有m个孩子(m>=2);
-
除根结点和叶子结点外,其它每个结点至少有[ceil(m / 2)]个孩子(其中ceil(x)是一个取上限的函数);
-
若根结点不是叶子结点,则至少有2个孩子(特殊情况:没有孩子的根结点,即根结点为叶子结点,整棵树只有一个根节点);
-
所有叶子结点都出现在同一层,叶子结点不包含任何关键字信息(可以看做是外部接点或查询失败的接点,实际上这些结点不存在,指向这些结点的指针都为null);(读者反馈@冷岳:这里有错,叶子节点只是没有孩子和指向孩子的指针,这些节点也存在,也有元素。@研究者July:其实,关键是把什么当做叶子结点,因为如红黑树中,每一个NULL指针即当做叶子结点,只是没画出来而已)。
-
每个非终端结点中包含有n个关键字信息: (n,P0,K1,P1,K2,P2,......,Kn,Pn)。其中:
a) Ki (i=1...n)为关键字,且关键字按顺序升序排序K(i-1)< Ki。
b) Pi为指向子树根的接点,且指针P(i-1)指向子树种所有结点的关键字均小于Ki,但都大于K(i-1)。
c) 关键字的个数n必须满足: [ceil(m / 2)-1]<= n <= m-1。
如下图所示:

用度定义的B树
针对上面的5点,再阐述下:B树中每一个结点能包含的关键字(如之前上面的D H和Q T X)数有一个上界和下界。这个下界可以用一个称作B树的最小度数(算法导论中文版上译作度数,最小度数即内节点中节点最小孩子数目)m(m>=2)表示。
-
每个非根的内结点至多有m个子女,每个非根的结点必须至少含有m-1个关键字,如果树是非空的,则根结点至少包含一个关键字;
-
每个结点可包含至多2m-1个关键字。所以一个内结点至多可有2m个子女。如果一个结点恰好有2m-1个关键字,我们就说这个结点是满的(而稍后介绍的B*树作为B树的一种常用变形,B*树中要求每个内结点至少为2/3满,而不是像这里的B树所要求的至少半满);
-
当关键字数m=2(t=2的意思是,m min=2,m可以>=2)时的B树是最简单的 (有很多人会因此误认为B树就是二叉查找树,但二叉查找树就是二叉查找树,B树就是B树,B树是一棵含有m(m>=2)个关键字的平衡多路查找树),此时,每个内结点可能因此而含有2个、3个或4个子女,亦即一棵2-3-4树,然而在实际中,通常采用大得多的t值。
B树中的每个结点根据实际情况可以包含大量的关键字信息和分支(当然是不能超过磁盘块的大小,根据磁盘驱动(disk drives)的不同,一般块的大小在1k~4k左右);这样树的深度降低了,这就意味着查找一个元素只要很少结点从外存磁盘中读入内存,很快访问到要查找的数据。如果你看完上面关于B树定义的介绍,思维感觉不够清晰,请继续参阅下文第6小节、B树的插入、删除操作 部分。
B树的高度
根据上面的例子我们可以看出,对于辅存做IO读的次数取决于B树的高度。而B树的高度由什么决定的呢?
若B树某一非叶子节点包含N个关键字,则此非叶子节点含有N+1个孩子结点,而所有的叶子结点都在第I层,我们可以得出:
- 因为根至少有两个孩子,因此第2层至少有两个结点。
- 除根和叶子外,其它结点至少有┌m/2┐个孩子,
- 因此在第3层至少有2*┌m/2┐个结点,
- 在第4层至少有2*(┌m/2┐^2)个结点,
- 在第 I 层至少有2*(┌m/2┐^(l-2) )个结点,于是有: N+1 ≥ 2*┌m/2┐I-2;
- 考虑第L层的结点个数为N+1,那么2*(┌m/2┐^(l-2))≤N+1,也就是L层的最少结点数刚好达到N+1个,即: I≤ log┌m/2┐((N+1)/2 )+2;
所以
- 当B树包含N个关键字时,B树的最大高度为l-1(因为计算B树高度时,叶结点所在层不计算在内),即:l - 1 = log┌m/2┐((N+1)/2 )+1。
这个B树的高度公式从侧面显示了B树的查找效率是相当高的 。
曾在一次面试中被问到, 一棵含有N个总关键字数的m阶的B树的最大高度是多少?答曰:log_ ceil(m/2) (N+1)/2 + 1 (上面中关于m阶B树的第1点特性已经提到: 树中每个结点含有最多含有m个孩子,即m满足:ceil(m/2)<= m<=m。而树中每个结点含孩子数越少,树的高度则越大,故如此)。在2012微软4月份的笔试中也问到了此问题。
此外,还有读者反馈,说上面的B树的高度计算公式与算法导论一书上的不同,而后我特意翻看了算法导论第18章关于B树的高度一节的内容,如下图所示:
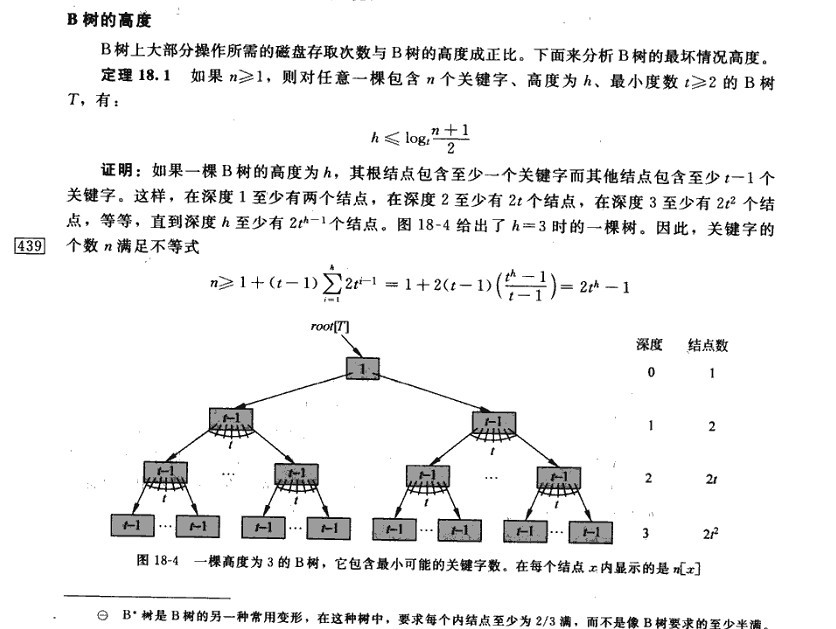
在上图中书上所举的例子中,也许,根据我们大多数人的理解,它的高度应该是4,而书上却说的是“一棵高度为3的B树”。我想,此时,你也就明白了,算法导论一书上的高度的定义是从“0”开始计数的,而我们中国人的习惯是树的高度是从“1”开始计数的。特此说明。July、二零一二年九月二十七日。
B+-tree
B+-tree:是应文件系统所需而产生的一种B-tree的变形树。
一棵m阶的B+树和m阶的B树的异同点在于:
1.有n棵子树的结点中含有n-1 个关键字; (此处颇有争议,B+树到底是与B 树n棵子树有n-1个关键字 保持一致,还是不一致:B树n棵子树的结点中含有n个关键字,待后续查证。暂先提供两个参考链接:①wikipedia http://en.wikipedia.org/wiki/B%2B_tree#Overview;②http://hedengcheng.com/?p=525。而下面B+树的图尚未最终确定是否有问题,请读者注意)
2.所有的叶子结点中包含了全部关键字的信息,及指向含有这些关键字记录的指针,且叶子结点本身依关键字的大小自小而大的顺序链接。 (而B 树的叶子节点并没有包括全部需要查找的信息)
3.所有的非终端结点可以看成是索引部分,结点中仅含有其子树根结点中最大(或最小)关键字。 (而B 树的非终节点也包含需要查找的有效信息)

a) 为什么说B+-tree比B 树更适合实际应用中操作系统的文件索引和数据库索引?
1) B+-tree的磁盘读写代价更低
B+-tree的内部结点并没有指向关键字具体信息的指针。因此其内部结点相对B 树更小。如果把所有同一内部结点的关键字存放在同一盘块中,那么盘块所能容纳的关键字数量也越多。一次性读入内存中的需要查找的关键字也就越多。相对来说IO读写次数也就降低了。
举个例子,假设磁盘中的一个盘块容纳16bytes,而一个关键字2bytes,一个关键字具体信息指针2bytes。一棵9阶B-tree(一个结点最多8个关键字)的内部结点需要2个盘快。而B+ 树内部结点只需要1个盘快。当需要把内部结点读入内存中的时候,B 树就比B+ 树多一次盘块查找时间(在磁盘中就是盘片旋转的时间)。
2) B+-tree的查询效率更加稳定
由于非终结点并不是最终指向文件内容的结点,而只是叶子结点中关键字的索引。所以任何关键字的查找必须走一条从根结点到叶子结点的路。所有关键字查询的路径长度相同,导致每一个数据的查询效率相当。
读者点评
本文评论下第149楼,fanyy1991针对上文所说的两点,道:个人觉得这两个原因都不是主要原因。数据库索引采用B+树的主要原因是 B树在提高了磁盘IO性能的同时并没有解决元素遍历的效率低下的问题。正是为了解决这个问题,B+树应运而生。B+树只要遍历叶子节点就可以实现整棵树的遍历。而且在数据库中基于范围的查询是非常频繁的,而B树不支持这样的操作(或者说效率太低)。
b) B+-tree的应用: VSAM(虚拟存储存取法)文件(来源论文 the ubiquitous Btree 作者:D COMER - 1979 )

B*-tree
B*-tree是B+-tree的变体,在B+树的基础上(所有的叶子结点中包含了全部关键字的信息,及指向含有这些关键字记录的指针),B*树中非根和非叶子结点再增加指向兄弟的指针;B*树定义了非叶子结点关键字个数至少为(2/3)*M,即块的最低使用率为2/3(代替B+树的1/2)。给出了一个简单实例,如下图所示:

B+树的分裂:当一个结点满时,分配一个新的结点,并将原结点中1/2的数据复制到新结点,最后在父结点中增加新结点的指针;B+树的分裂只影响原结点和父结点,而不会影响兄弟结点,所以它不需要指向兄弟的指针。
B*树的分裂:当一个结点满时,如果它的下一个兄弟结点未满,那么将一部分数据移到兄弟结点中,再在原结点插入关键字,最后修改父结点中兄弟结点的关键字(因为兄弟结点的关键字范围改变了);如果兄弟也满了,则在原结点与兄弟结点之间增加新结点,并各复制1/3的数据到新结点,最后在父结点增加新结点的指针。
所以,B*树分配新结点的概率比B+树要低,空间使用率更高;
总结
B树:有序数组+平衡多叉树;
B+树:有序数组链表+平衡多叉树;
B*树:一棵丰满的B+树。
在大规模数据存储的文件系统中,B~tree系列数据结构,起着很重要的作用,对于存储不同的数据,节点相关的信息也是有所不同,这里根据自己的理解,画的一个查找以职工号为关键字,职工号为38的记录的简单示意图。(这里假设每个物理块容纳3个索引,磁盘的I/O操作的基本单位是块(block),磁盘访问很费时,采用B+树有效的减少了访问磁盘的次数。)
对于像MySQL,DB2,Oracle等数据库中的索引结构得有较深入的了解才行,建议去找一些B 树相关的开源代码研究。

走进搜索引擎的作者梁斌老师针对B树、B+树给出了他的意见(为了真实性,特引用其原话,未作任何改动): “B+树还有一个最大的好处,方便扫库,B树必须用中序遍历的方法按序扫库,而B+树直接从叶子结点挨个扫一遍就完了,B+树支持range-query非常方便,而B树不支持。这是数据库选用B+树的最主要原因。
比如要查 5-10之间的,B+树一把到5这个标记,再一把到10,然后串起来就行了,B树就非常麻烦。B树的好处,就是成功查询特别有利,因为树的高度总体要比B+树矮。不成功的情况下,B树也比B+树稍稍占一点点便宜。
B树比如你的例子中查,17的话,一把就得到结果了,
有很多基于频率的搜索是选用B树,越频繁query的结点越往根上走,前提是需要对query做统计,而且要对key做一些变化。
另外B树也好B+树也好,根或者上面几层因为被反复query,所以这几块基本都在内存中,不会出现读磁盘IO,一般已启动的时候,就会主动换入内存。”非常感谢。
Bucket Li:"mysql 底层存储是用B+树实现的,知道为什么么。内存中B+树是没有优势的,但是一到磁盘,B+树的威力就出来了"。

















 1653
1653

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









