







 文章讲述了从传统的图像特征设计到深度学习的转变,特别是卷积神经网络(如AlexNet,VGG,GoogLeNet,ResNet)的发展,以及VisionTransformer的出现和其在图像分类任务中的卓越性能。此外,还提到了自监督学习作为有效的学习策略,以及各种优化技术如权重初始化、数据增强和模型正则化在提升模型性能中的作用。
文章讲述了从传统的图像特征设计到深度学习的转变,特别是卷积神经网络(如AlexNet,VGG,GoogLeNet,ResNet)的发展,以及VisionTransformer的出现和其在图像分类任务中的卓越性能。此外,还提到了自监督学习作为有效的学习策略,以及各种优化技术如权重初始化、数据增强和模型正则化在提升模型性能中的作用。
图像分类
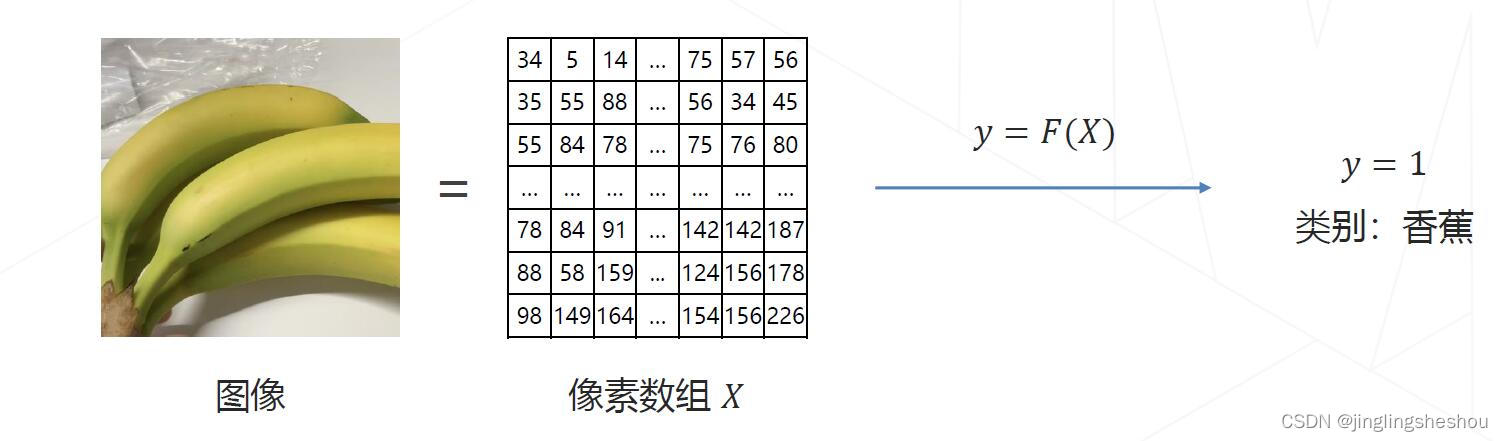
任务目标:给定一张图片,识别图像中的物体是什么。
数学表示
图像是像素构成的数组:
X
∈
R
H
×
W
×
3
X\in\mathbb{R}^{H\times W\times3}
X∈RH×W×3
对类别进行编号,香蕉
→
\rightarrow
→ 1,苹果
→
\rightarrow
→ 2,橘子
→
\rightarrow
→ 3等等,得到类别
y
∈
{
1
,
⋯
,
K
}
y\in \{1, \cdots, K\}
y∈{1,⋯,K},且预测结果符合人类认知。
视觉任务的难点
传统方法: 设计图像特征(1990s~2000s)
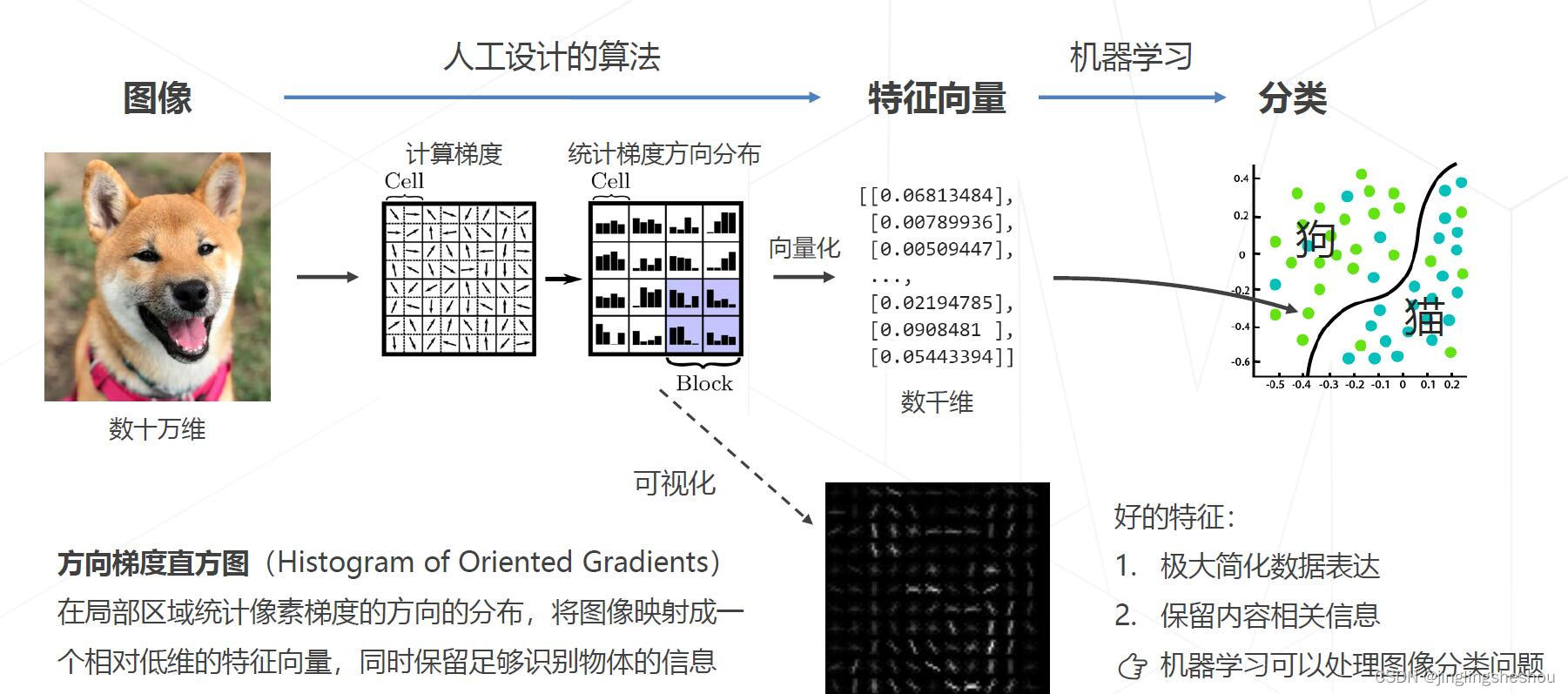
特征工程的天花板
在ImageNet图像识别挑战赛里,2010和2011年的冠军队伍都使用了经典的视觉方法,基于手工设计的特征+机器学习算法实现图像分类,Top-5错误率在25%上下。
受限于人类的智慧,手工设计特征更多局限在像素层面的计算,丢失信息过多,在视觉任务上的性能达到瓶颈。
AlexNet的诞生和卷积神经网络的时代
2012年,多伦多的团队首次使用深度学习,将错误率降低至15.3%。2015年,卷积网络的性能超越人类
课程内容
卷积神经网络
AlexNet(2012)
Going Deeper (2012~2014)
- VGG-19
- GoogLeNet
- ResNet残差网络(2015)
更强的图像分类模型
神经结构搜索 - 借助强化学习等方法去搜索最佳的网络
代表:NASNet(2017) \Mnasnet(2018)\ EfficientNet(2019)\RegNet(2020)等 - Vision Transformer (2020+)
使用transformer替代卷积网络实现分类,使用更大的数据集训练,达到超越卷积网络的精度
Vision Transformer(2020)、Swin-Transformer(2021ICCV最佳论文) - ConvNeXt(2022)
将Swin Transformer的模型元素迁移到卷积网络中,性能反超Transformer
轻量化卷积神经网络
降低模型参数量和计算量的方法
- 降低通道数 C ′ C^{\prime} C′和 C C C(平方级别)
- 减小卷积核的尺寸K(平方级别)
举例: - GoogLeNet使用不同大小的卷积核
- ResNet 使用 1 × 1 1\times1 1×1卷积压缩通道数
- 可分离卷积: MoboleNet V1 使用可分离卷积
- ResNeXt的分组卷积
Vision Transformers
模型学习
目标:确定模型
F
Θ
F_{\Theta}
FΘ的具体形式后,找寻最优参数
Θ
⋆
\Theta^{\star}
Θ⋆,使得模型
F
Θ
(
X
)
F_{\Theta}(X)
FΘ(X)给出准确的分类结果
p
(
y
∣
X
)
p(y|X)
p(y∣X)。
范式一:监督学习
范式二:自监督学习
学习率与优化策略
- 权重初始化:(1) 随机初始化;(1) 用训练和的模型进行权重初始化。
- 学习率策略:(1) 学习率退火Annealing;(2) 学习率升温 Warmup。
Linear Scaling Rule
经验性结论:针对同一个训练任务,当batch size扩大为原来的k倍时,学习率也对应扩大k倍。 - 自适应梯度算法
- 正则化与权重衰减 Weight Decay
- 早停Early Stopping
- 模型权重平均 EMA、Stochastic Weight Averaging
数组增强
- 组合数据增强 AutoAugment & RandAugment
- 组合图像 Mixup & CutMix
- 标签平滑 Label Smoothing
模型相关策略
- 丢弃层Dropout
- 随机深度 Stochastic Depth
自监督学习
Relative Location(ICCV2015)、 SimCLR(ICML2020)、Masked autoencoders(MAE, CVPR2022)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









