






 本文介绍了在信用评分场景下,如何处理缺失值(数值用均值,类别用众数填充)并选择关键特征。采用KNN模型进行训练,通过sklearn将数据集划分为训练集和测试集(30%为测试集),在测试集上取得了约0.79的准确率。下一步计划涉及异常值处理、相关性分析以及尝试更复杂的模型。
本文介绍了在信用评分场景下,如何处理缺失值(数值用均值,类别用众数填充)并选择关键特征。采用KNN模型进行训练,通过sklearn将数据集划分为训练集和测试集(30%为测试集),在测试集上取得了约0.79的准确率。下一步计划涉及异常值处理、相关性分析以及尝试更复杂的模型。
实践:
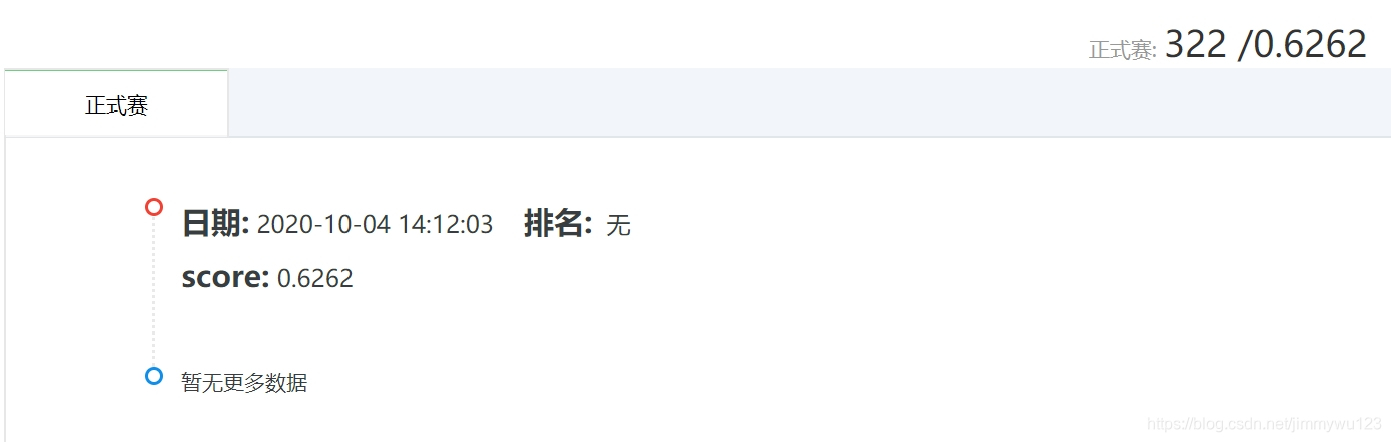
对部分有缺失值的特征做了简单的填充处理(数值类用均值替代,类别类用众数替代),重点选取部分与贷款数额、评级、收入与偿还能力相关的属性,使用KNN模型进行训练(因其较简单,运行速度较快)。由于测试集不含标签,我使用sklearn将原训练集随机划分为训练集、测试集,其中测试集占比为0.3,即240000条,在测试集上准确率约为0.79,赛事评分如下:
理论:
阅读了论坛中关于数据分析与特征工程的内容(包括可视化、空白值填充、异常值处理、特征选择等),下一步计划对异常值进行处理,并利用相关性分析选择适当的属性集。同时尝试缩小训练样本的规模,以更快地测试一些更复杂模型的性能。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









