 CCF比赛数据处理与模型应用
CCF比赛数据处理与模型应用




 本周开启新的CCF比赛,先了解数据集信息,进行数据预处理和特征工程,用XGBoost模型得出结果。训练集和测试集通过数据集左连接得到,对数据做缺失值填充、特征编码等处理。下周计划利用其他数据集和特征,安装Pytorch尝试神经网络模型并与决策树对比。
本周开启新的CCF比赛,先了解数据集信息,进行数据预处理和特征工程,用XGBoost模型得出结果。训练集和测试集通过数据集左连接得到,对数据做缺失值填充、特征编码等处理。下周计划利用其他数据集和特征,安装Pytorch尝试神经网络模型并与决策树对比。
本周开始了新的CCF比赛,首先了解各个数据集的基本信息,进行简单的数据预处理和特征工程操作,并直接使用上次最终效果最好的XGBoost模型跑出一个结果。
首先,训练集需要带标签的数据,使用数据集7中的14865个id作为键值与其他数据集做左连接(类似数据库操作),仅包含标签的id对应的条目保留。经观察,仅数据集1数据特征较全面且缺失少,因此目前暂时只用到数据集1,训练集为数据集7与数据集1以id为key左连接的结果(使用panda中的merge函数),测试集为数据集8与数据集1以id为key左连接的结果,其基本信息如下:
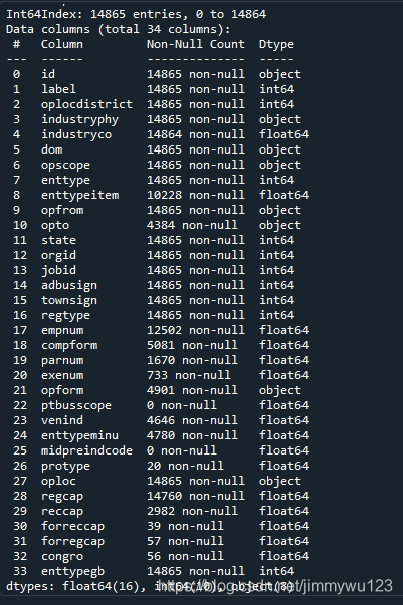
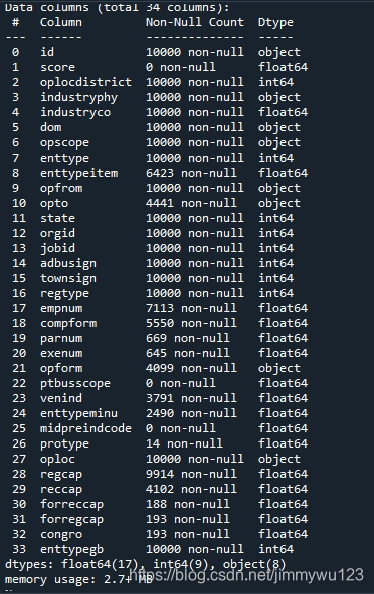
数据预处理和特征工程的方法与之前类似,部分特征缺失过多,予以舍弃(如protype,forreccap等)。部分类别类特征难为地址或字符串,暂时难以挖掘出有效信息供树模型处理(如dom,opscope等)。对缺失的数据用平均值做填充,将类别类特征iudustryphy映射1到19的数值(特征编码),便于模型处理。预处理并筛选后的特征集如下:
features = ['oplocdistrict','industryphy','industryco','enttype','state','orgid','jobid','adbusign','townsign','regtype','enttypegb','regcap']
XGBoost模型调参如下:
model = xgb.XGBClassifier(max_depth=5, min_child_weight=2, learning_rate=0.05, n_estimators=500, subsumple=0.8, colsample_bytree=0.8)
最终结果如下:
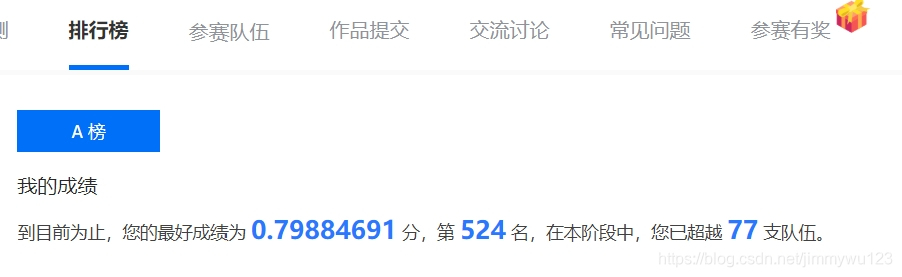
该结果还有较大提升空间。下周主要有两个方向:
一、尝试利用其他数据集,并尝试部分暂未用到的特征在预处理后是否能加入特征集
二、安装Pytorch,尝试之前没有使用过的神经网络模型,并与决策树模型做对比,必要时可尝试综合两者的结果


















 679
679

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









