



目录
前言
行业痛点:为何自建爬虫在AI时代步履维艰?
为什么选择Bright Data?面向AI数据采集的工程级解决方案
实战演练:构建“小米17”舆情AI Agent的四步法
第一步:注册与初始化
第二步:选择与配置数据采集API
第三步:配置采集任务
第四步:AI Agent 分析与报告生成 —— 从数据洞察驱动商业决策
数据如何变成决策依据?
结语:不是生成报告,而是赋能决策
前言
在竞争白热化的消费电子市场,新品发布前后的舆情动态是决定市场成败的关键。传统的市场调研方法缓慢且片面,而AI Agent能够自动、实时地从海量网络信息中提取洞察,正成为领先企业的“竞争雷达”。然而,构建一个高效的AI Agent,首要解决的难题就是:如何大规模、高可靠地获取训练与运行所需的视频、音频及文本数据。
本文将通过一个模拟案例——为“小米17”发布前后进行全网络舆情监控,详细解析如何利用Bright Data的企业级数据采集平台,构建一个端到端的AI分析Agent。
行业痛点:为何自建爬虫在AI时代步履维艰?
在构建“小米17”舆情AI Agent时,我们的工程师团队首先尝试了主流开源方案,却立刻遭遇了经典难题:
封锁与反爬:使用yt-dlp等工具抓取YouTube、B站等平台的评测视频时,频繁遭遇429错误和IP封禁。刚刚跑通的脚本,几小时后成功率就断崖式下跌。
规模化瓶颈:当试图增加并发以覆盖更多平台和数据时,自建代理池的IP质量参差不齐、管理复杂,导致工程资源大量耗费在基础设施维护上,而非核心的AI分析逻辑。
数据异构性:舆情散落在视频、音频、社区帖文、新闻等多种模态中。手动整合多种数据源并确保其稳定获取,几乎是一项不可能完成的任务。
这些痛点正是Bright Data旨在核心解决的企业级问题。
为什么选择Bright Data?面向AI数据采集的工程级解决方案
与常见的代理服务或开源工具不同,Bright Data是为大规模、高要求的商业数据采集而原生构建的。在“小米17”项目中,其优势体现得淋漓尽致:
对比yt-dlp/自建代理池:Bright Data提供的是即开即用、免维护的世界级代理网络,无需担心IP被封锁或速率限制,成功率与稳定性有数量级的提升。
对比其他商业爬虫平台:Bright Data的无限并发能力和只为成功结果付费的模式,使其在成本和性能上极具优势,特别适合需要快速覆盖全网舆情的爆发性需求。
实战演练:构建“小米17”舆情AI Agent的四步法
以下是如何利用Bright Data快速搭建并驱动这个AI Agent的核心流程:
第一步:注册与初始化
点击注册 Bright Data 快速创建账户,免费体验。其简洁的控制台让团队能在几分钟内完成初始化,立即开始数据采集之旅。
第二步:选择与配置数据采集API
根据“小米17”舆情分析的需求,我们组合使用了Bright Data的Web Scraper API中的两大核心产品:
Discover by keyword:根据关键词(如 "machine learning tutorial")在 YouTube 搜索栏中进行搜索,并抓取搜索结果中的视频。
返回数据:搜索结果中的视频标题、URL、频道、发布时间、播放量、音频转成文本内容等。
Collect by URL:根据一个 YouTube 视频链接,抓取该视频下的评论数据。
返回数据:评论内容、评论者用户名及链接、点赞数、发布时间、是否为置顶评论、二级评论等。
第三步:配置采集任务
在Bright Data控制台,通过有代码模式,轻松定义采集任务:
为什么选择“有代码”方式?
虽然亮数据提供零代码界面,但通过代码调用API,你可以实现:
✅ 完全自动化调度(如每日凌晨自动采集)
✅ 动态关键词生成(如根据热点自动调整搜索词)
✅ 复杂数据清洗与分类(NLP自动打标签)
✅ 无缝集成数据库/推荐系统
✅ 错误重试、日志监控、报警机制
1.登录平台后,点击左侧导航栏的 “Data” 模块,进入数据管理页面,然后选择 “Scrapers Library”(爬虫库),进入网络爬虫市场。
在爬虫市场中,选择 “社交媒体” 分类,找到并点击 “youtube.com”,进入该爬虫工具的详细配置页面,如下图: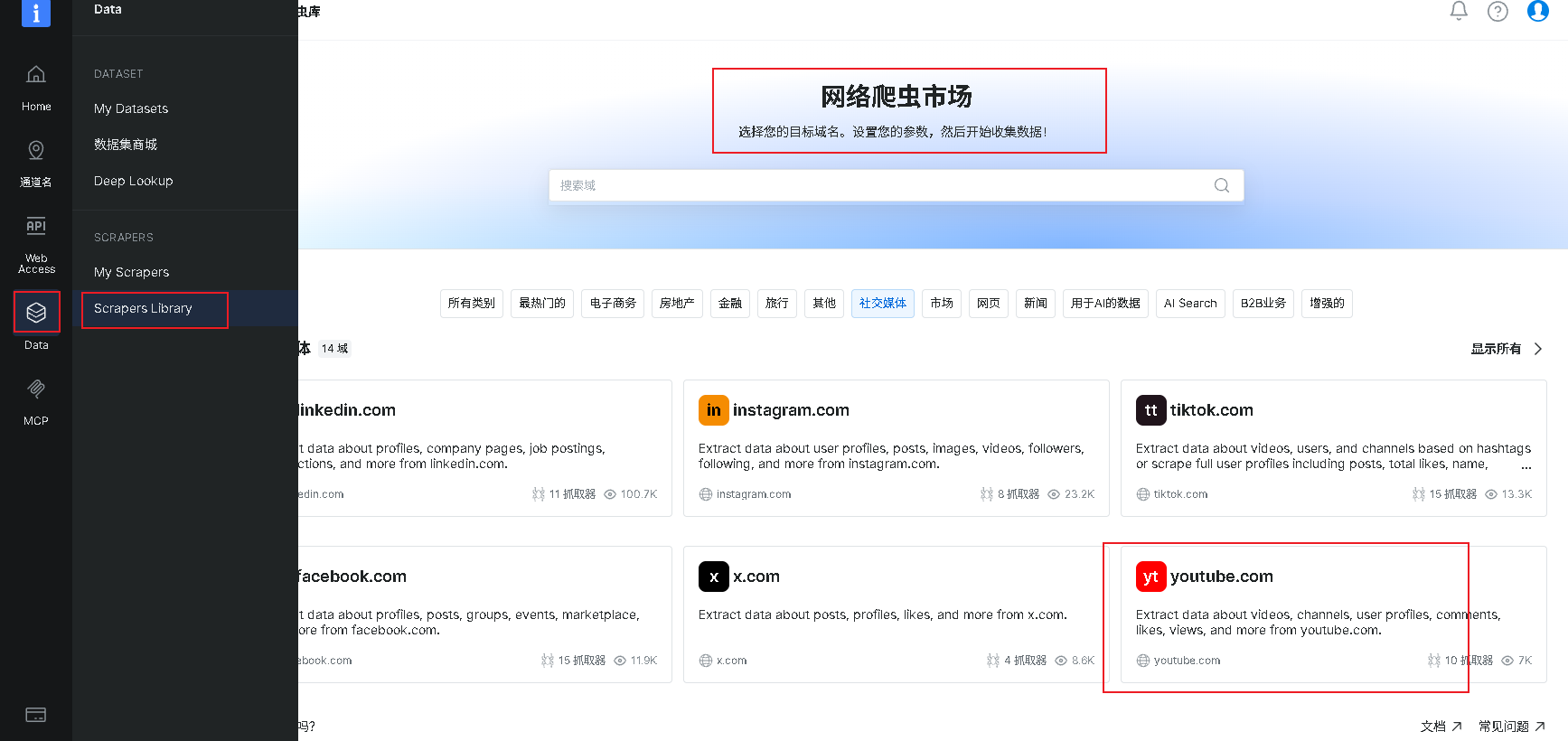
2.先使用Discover by keyword,我们输入相关的关键词,来发现视频,我们演示这里主要来爬取小米17发布首周的相关视频数据,这里博主演示做了爬取数量限制,具体可根据需求定制;输入相关数据后,右侧代码中会自动同步,我们直接复制拿到编辑器,如下图:
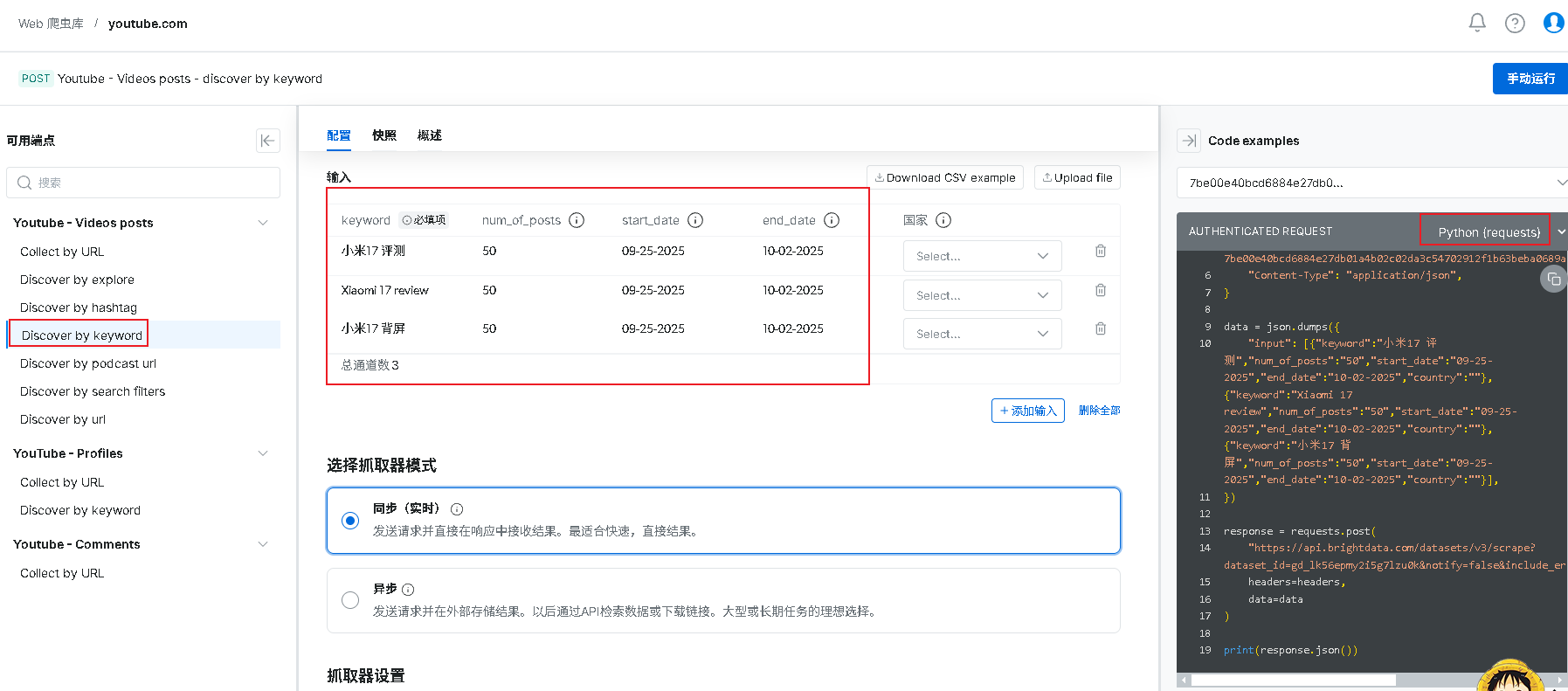
3.在编辑器中,可以直接运行代码,会直接触发请求,我们也可以在控制面板查看日志,能看到触发的请求,等状态变为Ready,既为爬取成功,我们可以直接点击下载按钮进行下载爬取的数据,如下图:
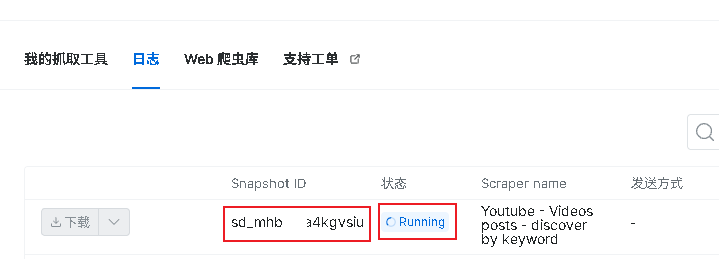
4.通过Snapshot ID直接通过官方提供的api下载爬取成功的数据,代码如下:
import requests
url = 'https://api.brightdata.com/datasets/v3/snapshot/替换你的SnapshotID?batch_size=1000&part=1'
headers = {
'Authorization': '替换你的令牌'
}
try:
response = requests.get(url, headers=headers, stream=True)
response.raise_for_status()
with open('discover_by_keyword.jsonl', 'wb') as file:
for chunk in response.iter_content(chunk_size=8192):
file.write(chunk)
print("Download completed successfully")
except requests.exceptions.RequestException as e:
print(f"Error: {e}")
运行如上后,我们拿到的这个 .jsonl 文件是原始抓取结果,信息很全但比较杂,很多字段用不上。接下来就需要做数据清洗,把我们真正需要的字段——比如视频标题、播放量、发布时间这些——提取出来,整理成干净、易用的数据表。
5.discover_by_keyword.jsonl数据清洗,代码如下:
import json
import os
def extract_clean_video_data(raw_data):
"""
提取指定字段,若关键字段缺失则返回 None(视为垃圾数据)
"""
# 关键字段检查:如果 url、video_id、title 等核心字段缺失,或没有 video_url(代表无法播放),视为无效
if not raw_data.get("video_url"):
return None # 垃圾数据:无视频播放链接
if not raw_data.get("url") or not raw_data.get("video_id") or not raw_data.get("title"):
return None # 垃圾数据:缺少基本元数据
# 提取
video = {
"url": raw_data.get("url"), # 视频在 YouTube 上的完整网页链接
"video_id": raw_data.get("video_id"), # YouTube 分配给该视频的唯一 ID
"title": raw_data.get("title"), # 视频的标题
"youtuber": raw_data.get("youtuber"), # 发布该视频的 YouTube 用户名(Handle)
"handle_name": raw_data.get("handle_name"), # 频道所有者的真实姓名或常用名
"channel_url": raw_data.get("channel_url"), # YouTube 频道主页链接
"date_posted": raw_data.get("date_posted"), # 视频发布时间 (ISO 格式)
"timestamp": raw_data.get("timestamp"), # 数据被抓取的时间戳
"views": raw_data.get("views"), # 视频累计观看次数
"likes": raw_data.get("likes"), # 视频获得的点赞数
"subscribers": raw_data.get("subscribers"), # 频道订阅者数量
"video_length": raw_data.get("video_length"), # 视频时长(秒)
"preview_image": raw_data.get("preview_image"), # 视频缩略图 URL
"quality": raw_data.get("quality"), # 视频质量标签(如 hd720)
"quality_label": raw_data.get("quality_label"), # 更详细的分辨率描述(如 720p)
"is_sponsored": raw_data.get("is_sponsored"), # 是否为赞助内容
"verified": raw_data.get("verified"), # 频道是否认证
"license": raw_data.get("license") # 视频版权或许可类型
}
# 直接使用原始数据中的 input(来源) 和 transcript(字幕)(如果存在)
input_data = raw_data.get("input", {})
transcript_data = raw_data.get("transcript", [])
return {
"video": video,
"input": input_data,
"transcript": transcript_data
}
def process_jsonl_file(input_file, output_file):
"""
处理 .jsonl 文件(每行一个 JSON)
"""
cleaned_data = []
with open(input_file, 'r', encoding='utf-8') as f:
for line_num, line in enumerate(f, 1):
line = line.strip()
if not line:
continue # 跳过空行
try:
raw_data = json.loads(line)
cleaned = extract_clean_video_data(raw_data)
if cleaned:
cleaned_data.append(cleaned)
else:
print(f"跳过第 {line_num} 行:缺少关键字段(垃圾数据)")
except json.JSONDecodeError as e:
print(f"第 {line_num} 行 JSON 解析失败:{e}")
# 保存结果
with open(output_file, 'w', encoding='utf-8') as f:
json.dump(cleaned_data, f, indent=2, ensure_ascii=False)
print(f"清洗完成!共保留 {len(cleaned_data)} 条有效数据,已保存至 {output_file}")
def process_json_array_file(input_file, output_file):
"""
处理 JSON 数组文件(整个文件是一个列表)
"""
cleaned_data = []
with open(input_file, 'r', encoding='utf-8') as f:
try:
data_list = json.load(f) # 整个文件是一个列表
except json.JSONDecodeError as e:
print(f"文件解析失败:{e}")
return
for idx, raw_data in enumerate(data_list):
cleaned = extract_clean_video_data(raw_data)
if cleaned:
cleaned_data.append(cleaned)
else:
print(f"跳过第 {idx + 1} 个对象:缺少关键字段(垃圾数据)")
# 保存结果
with open(output_file, 'w', encoding='utf-8') as f:
json.dump(cleaned_data, f, indent=2, ensure_ascii=False)
print(f"清洗完成!共保留 {len(cleaned_data)} 条有效数据,已保存至 {output_file}")
process_jsonl_file('discover_by_keyword.jsonl', 'discover_by_keyword.json')
执行结果:
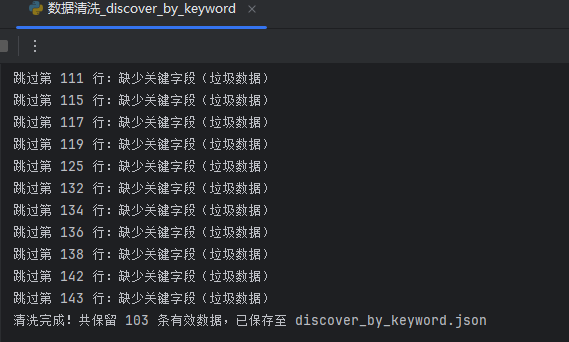
输出结果:

6.现在我们已经有了清洗好的视频数据。下一步,要分析用户对“小米17发布”的看法,就需要评论数据。我们先从刚才处理完的文件里,把所有视频的链接提取出来,然后用 Collect by URL 功能,自动去每个视频下面抓取评论内容,代码如下:
import time
import requests
import json
file_path = 'discover_by_keyword.json'
with open(file_path, 'r', encoding='utf-8') as file:
data = json.load(file)
# 提取每个 video 的 url
# 保持首次出现的顺序并去重
urls = list(dict.fromkeys(
item['video']['url']
for item in data
if isinstance(item, dict) and 'video' in item and 'url' in item['video']
))
# print("提取到的 video URLs(按顺序去重):")
# for url in urls:
# print(url)
#
# print(f"\n✅ 共提取到 {len(urls)} 个不重复的 URL")
headers = {
"Authorization": "替换你的令牌",
"Content-Type": "application/json",
}
input_list = [
{
"url": url,
"sort_by": "Top comments",
"num_of_comments": 120, #爬取主评论的数量
"load_replies": 5 #子评论数量
}
for url in urls
]
data = json.dumps({"input": input_list})
# print(data)
response = requests.post(
"https://api.brightdata.com/datasets/v3/scrape?dataset_id=gd_lk9q0ew71spt1mxywf¬ify=false&include_errors=true",
headers=headers,
data=data
)
time.sleep(5)
print(response.json())
7.爬取成功后,我们使用SnapshotID,下载爬取的数据,代码如下:
import requests
url = 'https://api.brightdata.com/datasets/v3/snapshot/替换你的SnapshotID?batch_size=1000&part=1'
headers = {
"Authorization": "替换你的令牌",
}
try:
response = requests.get(url, headers=headers, stream=True)
response.raise_for_status()
with open('collect_by_url.jsonl', 'wb') as file:
for chunk in response.iter_content(chunk_size=8192):
file.write(chunk)
print("Download completed successfully")
except requests.exceptions.RequestException as e:
print(f"Error: {e}")
运行如上后,我们同样拿到的这个 .jsonl 文件是原始抓取结果,信息很全但比较杂,很多字段用不上。接下来就需要做数据清洗。
8.collect_by_url.jsonl数据清洗,代码如下:
import json
input_file = 'collect_by_url.jsonl'
output_file = 'collect_by_url.json'
result = []
with open(input_file, 'r', encoding='utf-8') as f:
for line_num, line in enumerate(f, 1):
line = line.strip()
if not line:
continue
try:
data = json.loads(line)
except json.JSONDecodeError as e:
print(f"第 {line_num} 行 JSON 解析错误: {e}")
continue
# 提取主评论信息
main_comment = {
"user_name": data.get("username"),
"comment_text": data.get("comment_text"),
"likes": data.get("likes", 0),
"url": data.get("url")
}
# 提取 replies_value 中的回复
replies = []
replies_value = data.get("replies_value", []) or [] # 防止为 None
for reply in replies_value:
reply_item = {
"user_name": reply.get("user_name"),
"reply_text": reply.get("reply_text"),
"reply_like": reply.get("reply_like", 0)
}
# 可选:过滤空回复
if reply_item["reply_text"]:
replies.append(reply_item)
# 组合成最终结构
item = {
"comment": main_comment,
"replies": replies
}
result.append(item)
# 保存为标准 JSON(数组),方便阅读和使用
with open(output_file, 'w', encoding='utf-8') as f:
json.dump(result, f, ensure_ascii=False, indent=2)
print(f"✅ 提取完成!共处理 {len(result)} 条主评论")
print(f"✅ 结果已保存到 '{output_file}'")
执行结果:
输出结果:
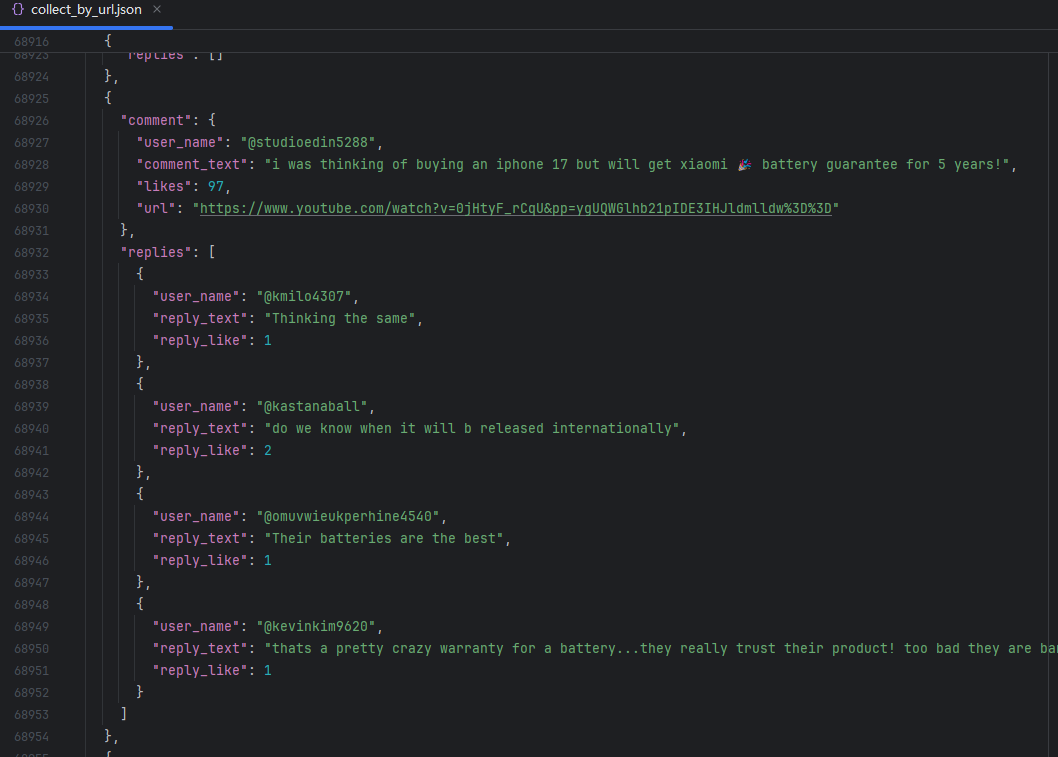
8. 至此,我们已分别获取了视频元数据的 JSON 文件和对应评论数据的 JSON 文件。下一步,将这两个数据集进行合并:以视频 URL 或视频 ID 为唯一键,将每条视频的评论数据嵌入到其对应的视频元信息中,实现“一个视频 + 其全部评论”的完整数据结构,便于管理和分析。代码如下:
import json
def load_json_file(filename):
"""读取 JSON 文件"""
try:
with open(filename, 'r', encoding='utf-8') as f:
return json.load(f)
except FileNotFoundError:
print(f"错误:文件 {filename} 未找到。")
exit(1)
except json.JSONDecodeError as e:
print(f"错误:{filename} 文件格式不是有效的 JSON。")
print(e)
exit(1)
def save_json_file(data, filename):
"""保存数据到 JSON 文件"""
try:
with open(filename, 'w', encoding='utf-8') as f:
json.dump(data, f, ensure_ascii=False, indent=2)
print(f"✅ 合并完成,结果已保存到 {filename}")
except Exception as e:
print(f"❌ 保存文件失败:{e}")
def merge_comments_to_videos(a_list, b_list):
"""将 b_list 中匹配 url 的评论添加到 a_list 对应项中"""
result = []
for item in a_list:
video_url = item['video']['url']
matched_comments = []
for comment_item in b_list:
comment_url = comment_item['comment']['url']
if comment_url == video_url:
# 只保留 comment 内容,不带外层包装和 replies
clean_comment = comment_item['comment'].copy()
matched_comments.append(clean_comment)
# 复制原 item 并添加 comments 字段
new_item = {**item}
new_item['comments'] = matched_comments
result.append(new_item)
return result
def main():
# 📁 文件路径
a_file = 'discover_by_keyword.json' # 视频数据
b_file = 'collect_by_url.json' # 评论数据
output_file = 'output.json' # 输出文件
# 🔽 读取文件
print("🔄 正在读取 a.json 和 b.json...")
a_data = load_json_file(a_file)
b_data = load_json_file(b_file)
# 🔀 合并评论
print("🔧 正在合并评论...")
merged_data = merge_comments_to_videos(a_data, b_data)
# 📤 保存结果
save_json_file(merged_data, output_file)
if __name__ == "__main__":
main()
第四步:AI Agent 分析与报告生成 —— 从数据洞察驱动商业决策
当企业通过 Bright Data 快速获取高质量、结构化的真实用户评论数据后,真正的价值才刚刚开始。我们的 AI Agent 立即接手这些干净可用的数据,自动执行深度语义分析、情感识别、主题聚类与风险预警,将海量非结构化文本转化为可读、可视、可行动的商业洞察。
以本次小米17系列发布首周舆情分析为例,AI Agent 在数小时内完成对 YouTube 核心评测视频及用户评论的全面解析,输出一份结构清晰、重点突出的自动化报告。这不仅节省了人工收集与整理的数日工作量,更关键的是——让企业实现了“从数据到洞察”的秒级跃迁。
数据如何变成决策依据?
快速定位核心争议点
报告一眼揭示:“背屏实用性差”成为最高频负面反馈(⭐⭐⭐⭐⭐),远超其他问题。这意味着产品团队可立即评估功能迭代优先级,市场团队则需准备针对性沟通话术,避免舆论进一步恶化。
识别品牌信任危机苗头
“抄袭”“系统烂”“割韭菜”等关键词高频出现,且已形成如“宛平路600号做手机”等网络梗。AI 不仅标记出这些高风险表达,还评估整体危机等级为🟡中等——提前预警,为企业争取黄金响应时间。
把握用户真实偏好
尽管争议不断,仍有35%正面评价集中于“创意新颖”“设计用心”“续航强劲”。这说明创新方向获得了部分核心用户的认可。企业可据此精准定位目标客群:热爱尝鲜、追求个性化的科技爱好者,并围绕这一群体优化营销策略。
竞品对比洞察直达战略层
用户频繁将小米与 iPhone 对比,既批评其“缺乏自信”,也肯定其“敢于探索”。这种复杂认知提醒管理层:技术创新的同时,品牌叙事和用户心智建设必须同步升级。
可视化 = 决策加速器
所有分析结果均以可视化仪表盘呈现:情感分布饼图、热点词云、趋势折线、风险热力图……无论是产品经理、市场总监还是高管,都能在几分钟内掌握全局,无需技术背景即可理解关键信息。
原来需要一周的手工调研 → 现在24小时内自动完成
模糊的“感觉有争议” → 明确的“40%负面源于背屏实用性”
被动应对舆情 → 主动预判风险、制定回应策略
结语:不是生成报告,而是赋能决策
借助 Bright Data + AI Agent 的闭环能力,企业不再只是“看到数据”,而是真正实现从被动观察到主动干预的转变。每一次产品发布、每一次营销活动、每一次品牌互动,都可以基于真实用户声音做出更快、更准、更有温度的决策。这才是数据的价值:不止于看见,更在于预见与行动。
AI大模型学习福利
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

因篇幅有限,仅展示部分资料,需要点击文章最下方名片即可前往获取
二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

因篇幅有限,仅展示部分资料,需要点击文章最下方名片即可前往获
三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

因篇幅有限,仅展示部分资料,需要点击文章最下方名片即可前往获
四、AI大模型商业化落地方案

因篇幅有限,仅展示部分资料,需要点击文章最下方名片即可前往获
作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









