



本章,主要给大家简单介绍了几款获取性能数据的工具,包含:nmon、jvisualvm、jmc、arthas、ark等,这里也只是简单的介绍了一些基本用法,起到抛砖引玉的作用,各个工具的详细用法,还是要小伙伴们深入学习。
相信有一定基础的小伙伴们对CPU与内存的速度差异、内存与磁盘的速度差异以及磁盘的顺序写和随机写速度差异有一定的了解。
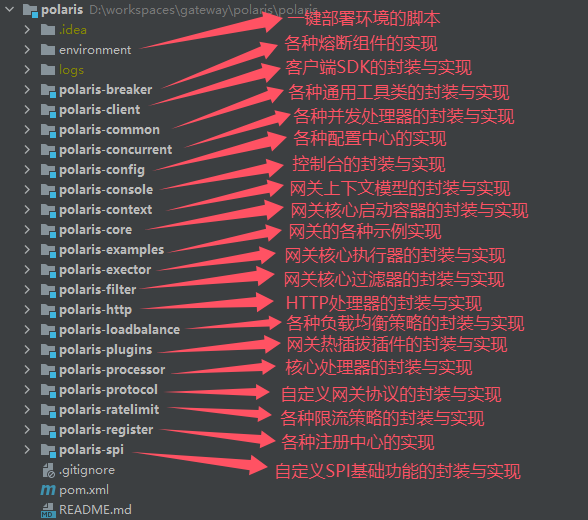
高性能polaris网关项目结构图
高性能Polaris网关项目一期工程基本完结,文末领券加星球跟冰河一起学习高性能Polaris网关。
了解一些计算机硬件的速度差异,再结合一些代码的性能分析工具,可以更好的分析代码的运行时性能,包括操作系统性能数据、JVM 的性能数据、应用的性能数据等。
一、计算机硬件速度差异
1.1 CPU与内存的速度差异
- CPU比内存快多少:CPU的处理速度通常比内存快很多。CPU的时钟频率可以达到3-5 GHz(即每秒数十亿次的操作),而内存(DRAM)的带宽大约为几十GB/s(例如DDR4的带宽大约是25-30 GB/s)。理论上,CPU每个时钟周期能完成的操作比内存大得多,因此CPU对内存的访问时间比内存的读写速度慢得多。
- 大致估算:CPU的处理速度比内存快100到1000倍。换句话说,CPU需要等待内存的数据大约是其自身处理速度的数百倍。
1.2 内存与磁盘的速度差异
- 内存比磁盘快多少:内存的访问速度通常比硬盘快得多。现代的内存(DRAM)可以在毫微秒级别(ns)内完成访问,而传统硬盘(HDD)需要等待毫秒级别的响应时间。
- 内存与磁盘速度比:内存的读取速度通常比磁盘快几千到几万倍。例如,内存的读取时间可能为几十纳秒(ns),而HDD则可能是几毫秒(ms)。现代的固态硬盘(SSD)比传统的HDD要快,但即使是SSD,其速度仍然比内存慢得多,可能只有几十倍到几百倍。
1.3 磁盘的顺序写和随机写速度
- 顺序写(Sequential Write):顺序写是指数据按顺序连续写入磁盘,这样磁头移动的距离较小,通常可以实现最快的写入速度。SSD的顺序写速度通常可以达到几GB/s(例如,现代NVMe SSD的顺序写速度可达到3-7GB/s,甚至更高)。而HDD的顺序写速度一般在100-150 MB/s之间。
- 随机写(Random Write):随机写是指数据以随机方式分布,磁头需要不断移动到不同位置,导致速度下降。SSD的随机写速度通常要比顺序写慢一些,但仍比HDD快很多。现代SSD的随机写速度可能在几百MB/s到几GB/s之间,而传统HDD的随机写速度可能只有几十MB/s。
- 顺序写与随机写速度比
a.对于SSD,顺序写速度通常比随机写速度快大约1.5到3倍(视具体设备而定)。
b.对于HDD,顺序写比随机写要快3到5倍左右。
了解完计算机硬件的速度差异后,接下来,我们重点介绍如何获取代码的运行时性能数据。
二、通过nmon获取性能数据
nmon是一个经典的Linux性能监控工具,可以通过nmon工具获取详细的监控报告。
2.1 安装nmon
以CentOS7为例,可以在命令行输入如下命令安装nmon。
yum install epel-release -y
yum install nmon -y
nmon -v
也可以直接从nmon官方站点:https://nmon.sourceforge.io/pmwiki.php 下载二进制文件,赋予其执行权限即可。
chmod +x nmon_x86_64_linux
./nmon_x86_64_linux
如果安装成功,输入nmon -v 或者 ./nmon_x86_64_linux后,会输出如下所示的信息。
[root@localhost ~]# nmon -v
nmon: invalid option -- 'v'
Hint for nmon version 16g
Full Help Info : nmon -h
On-screen Stats: nmon
Data Collection: nmon -f [-s <seconds>] [-c <count>] [-t|-T]
Capacity Plan : nmon -x
Interactive-Mode:
Read the Welcome screen & at any time type: "h"for more help
Type "q" to exit nmon
For Data-Collect-Mode
-f Must be the first option on the line (switches off interactive mode)
Saves data to a CSV Spreadsheet format .nmon file inthenlocal directory
Note: -f sets a defaults -s300 -c288 which you can then modify
Further Data Collection Options:
-s <seconds> time between data snapshots
-c <count> of snapshots before exiting
-t Includes Top Processes stats (-T also collects command arguments)
-x Capacity Planning=15 min snapshots for 1 day. (nmon -ft -s 900 -c 96)
---- End of Hints
2.2 运行 nmon
在命令行运行输入nmon命令运行nmon,如下所示。

进入nmon的运行面板后,可以按对应的快捷键监控指定的硬件资源,例如:
- CPU:按
c - 内存:按
m - 内核 :按
k - 磁盘 I/O:按
d - 网络:按
n - 进程:按
p - 退出:按
q
例如,按 d 监控磁盘的性能数据,如下所示。

通过如下命令,可以采集服务器数据。
nmon -f -s 5 -c 12 -m .
此命令表示每 5 秒采集一次数据,共采集 12 次。执行此命令后,可以通过ps- ef | grep nmon 命令查看运行的进程。

nmon会把这一段时间之内的数据记录下来。比如这次生成的文件为localhost_250616_0848.nmon。

随后,可以通过nmonchart工具将nmon文件转换成html文件。首先安装nmonchart,如下所示。
wget https://sourceforge.net/projects/nmon/files/nmonchart43.tar
tar xvf nmonchart43.tar
随后,可以通过如下命令将nmon文件转换成html文件。
./nmonchart localhost_250616_0848.nmon localhost_250616_0848.html
文件转换成功,会多出一个localhost_250616_0848.html文件,如下所示。

注意:如果在转换文件时报如下错误。
/usr/bin/env: ksh: No such file or directory
则需要输入如下命令安装ksh。
yum install ksh -y
将生成的localhost_250616_0848.html文件下载到本地,使用浏览器打开,如下所示。
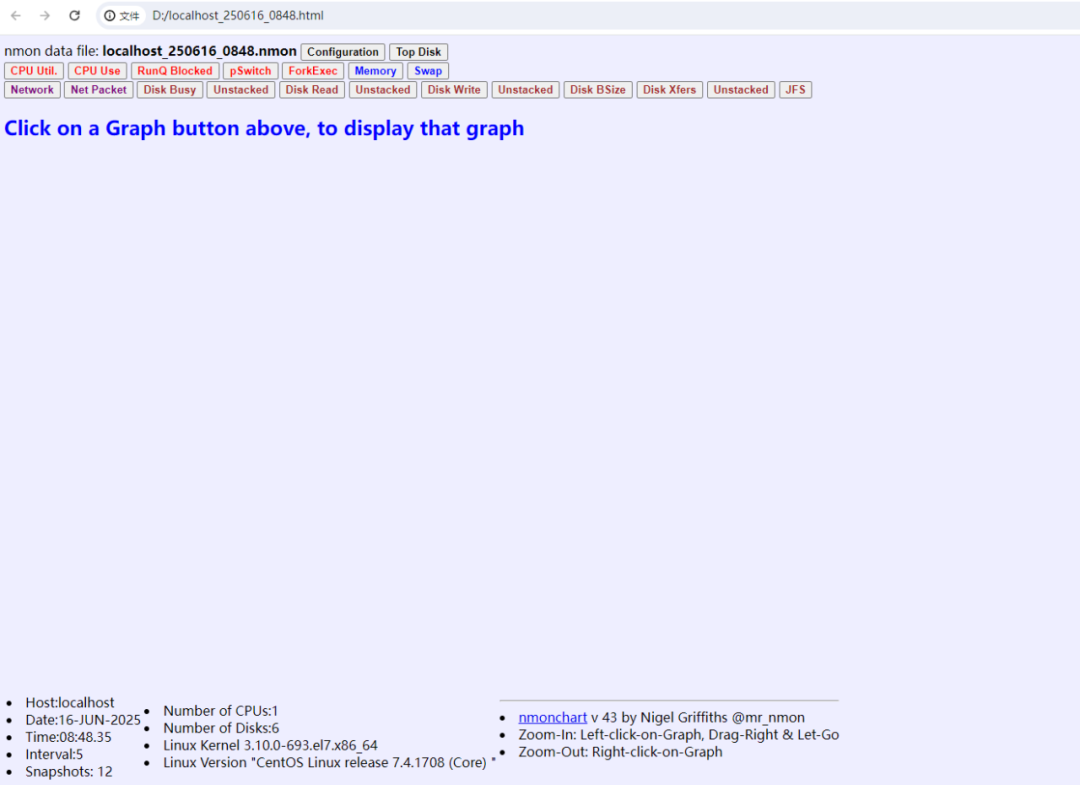
随后,就可以点击菜单栏来查看具体的监控指标了。
三、通过jvisualvm获取JVM性能数据
相信不少小伙伴都知道,jvisualvm是获取JVM性能数据的一款工具,在JDK1.8之前,会集成到JDK中,在JDK9之后,会单独进行发布。,并且jvisualvm也提供了大量的插件。
3.1 安装jvisualvm
大家可以到链接:https://visualvm.github.io下载jvisualvm,下载完毕后打开界面如下所示。
也可以在jvisualvm中更新自己想要安装的插件,点击Tools—>Plugins—>Available Plugins即可看到在jvisualvm中可以更新插件。
3.2 监控数据
如果想通过jvisualvm监控远程应用,则可以在应用上保留对应的JMX端口,具体做法就是在启动应用时,添加如下JVM参数。
-Dcom.sun.management.jmxremote.port=11000
-Dcom.sun.management.jmxremote.authenticate=false
-Dcom.sun.management.jmxremote.ssl=false
此时,应用对外保留的JMX端口为11000,并且不需要认证。
在jvisualvm中分析性能数据,主要使用的是抽样器(Sampler),如下所示。
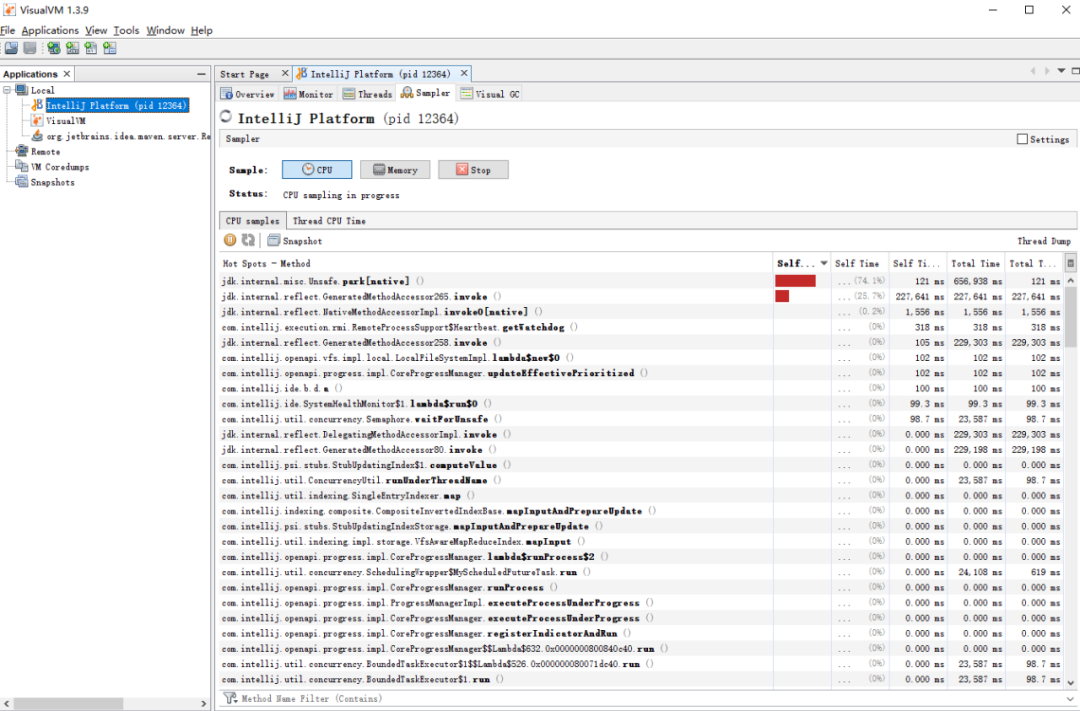
除此之外,也要关注如下一些指标。
- CPU分析:统计方法的执行次数和执行耗时,分析哪些方法执行时间过长,可能成为热点等。
- 内存分析:可以通过内存监视和内存快照等方式进行分析,进而检测内存泄漏问题,优化内存使用情况。
- 线程分析:可以查看线程的状态变化,以及一些死锁情况。
四、通过JMC获取详细性能数据
JMC的全称是JDK Misson controll,是一款分析Java应用详细性能数据的强大工具,也是一个图形化的界面监控工具,监控信息非常全面,JMC打开性能日志后,主要包括一般信息、内存、代码、线程、I/O、系统、事件等功能。
4.1 安装JMC
打开链接:https://www.oracle.com/java/technologies/jdk-mission-control.html 下载JMC,找到自己需要的版本后进行下载。下载后,解压即可使用。
4.2 目标JVM配置
需要在被监控的JVM上开启如下配置才能进行监控。
-Dcom.sun.management.jmxremote.authenticate=false
-Dcom.sun.management.jmxremote.ssl=false
-Dcom.sun.management.jmxremote.port=7777
-Dcom.sun.management.jmxremote
-XX:+UnlockCommercialFeatures
-XX:+FlightRecorder
如果要在目标JVM上启动持续不断的监控记录,并在JVM正常退出时Dump记录为文件,可以参考下面的脚本设置JVM参数。
for /f "tokens=1-3 delims=/ " %%a in ('date /t') do (set md=%%a-%%b-%%c)
for /f "tokens=1-3 delims=/:." %%a in ("%TIME%") do (set mt=%%a%%b%%c)
set CUR_TIME=%md%-%mt%
rem 启用黑匣子默认记录行为。官方文档注明dumponexitpath支持目录,但我在7u71版本下测试失败
set JAVA_OPTS=%JAVA_OPTS% -XX:FlightRecorderOptinotallow=defaultrecording=true,disk=true,dumpnotallow=true,dumpnotallow=%LOG_DIR%\jfr\dump-on-exit-%CUR_TIME%.jfr,maxage=3600s,settings=%JRE_HOME%\lib\jfr\profile.jfc
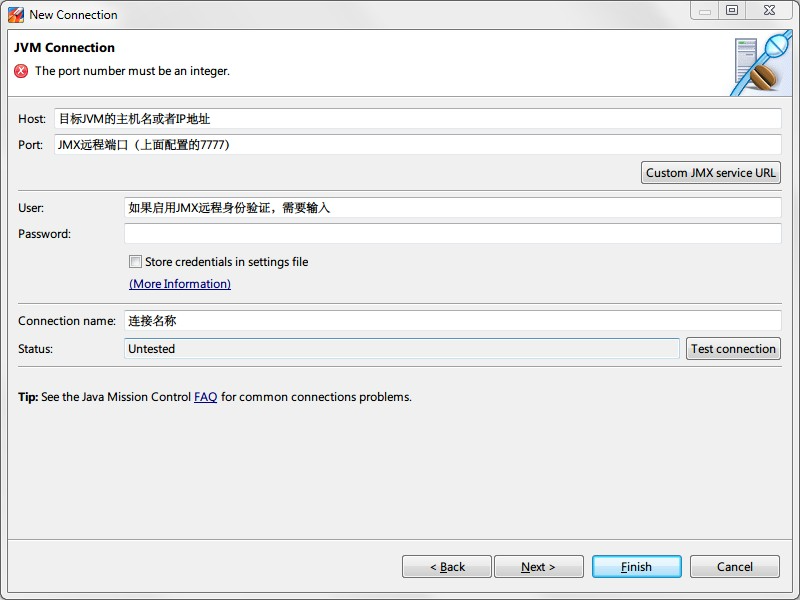
4.3 连接目标JVM
配置并重启目标JVM后,打开JMC,点击 File - Connect... - Create New connection,参考下图设置,完毕后点击Test connection确认可以连通,最后点击Finish结束配置。
4.4 MBean Server
在左侧窗格JVM Browser视图中,双击刚刚创建的JMC连接,点击MBean Server,即可在右侧主窗体查看实时的JVM状态信息,供6个选项卡,下面依次描述。
4.4.1 总览
包含JVM概要性的实时图表,包含3个面板:
|
面板 |
说明 |
|
仪表盘(Dashboard) |
以仪表方式显示系统运行参数,默认显示堆内存占用、JVM处理器占用、垃圾回收前后的堆内存情况。注意仪表上有有两个指针,灰色的通常显示最大值,黑色的显示当前值。 面板右侧的+号按钮,点击后可以添加目标JVM支持的任何运行参数到仪表盘中 |
|
处理器(Processor) |
显示JVM、操作系统的动态CPU占用曲线 |
|
内存(Memory) |
默认显示Java堆内存占用情况,可以选择查看物理内存占用等项目 |
4.4.2 MBean浏览器
以树形结构显示目标JVM支持的所有MBean列表和属性、操作集。
4.4.3 触发器
包含若干预定义的触发器,可以在特定条件下,执行预定义的动作。支持的触发器包括:
|
触发器 |
说明 |
|
CPU Usage - JVM Process (Too High) |
当JVM的进程的CPU占用过高时 |
|
CPU Usage - JVM Process (Too Low) |
当JVM的进程的CPU占用过低时 |
|
CPU Usage - Machine (Too High) |
当OS的CPU占用过高时 |
|
CPU Usage - Machine (Too Low) |
当OS的CPU占用过低时 |
|
Deadlocked Threads |
当发生JVM线程死锁时 |
|
Live Set (Too Large) |
当垃圾回收之后,存活对象占堆大小百分比过大时 |
|
Thread Count (Too High) |
当JVM线程总数过大时 |
此外,任何MBean属性均可以作为触发器使用,中间件(例如Tomcat、Weblogic、ActiveMQ)都有自己的扩展。 双击触发器后,右侧即显示规则详情(Rule Details),可以定义触发的阈值(到达时,或者从异常值恢复时)、执行的动作,可用的动作包括:
|
动作 |
说明 |
|
Application alert |
在应用程序上显示一个警告对话框 |
|
Console output |
在控制台(stdout)上输出警告信息 |
|
Dump Flight Recording |
保存黑匣子记录内容 |
|
HPROF Dump |
保存堆镜像 |
|
Log to file |
在日志文件中输出警告信息 |
|
Send e-mail |
通过电子邮件发送警告信息 |
|
Start Continuous Flight Recording |
启动不间断的黑匣子记录 |
|
Start Time Limited Flight Recording |
启动限制时间长度的黑匣子记录 |
4.4.4 LiveSet
所谓LiveSet,是指在一次垃圾回收之后,堆内存的占用比率,取值在0-1之间。
如果GC后,可用的内存空间不足,则LiveSet接近100%,这预示可能存在OOM风险。在生产环境下,我们可以监控LiveSet,并在其过大时,把堆内存映像Dump出来供后续分析。
触发器配置示例:
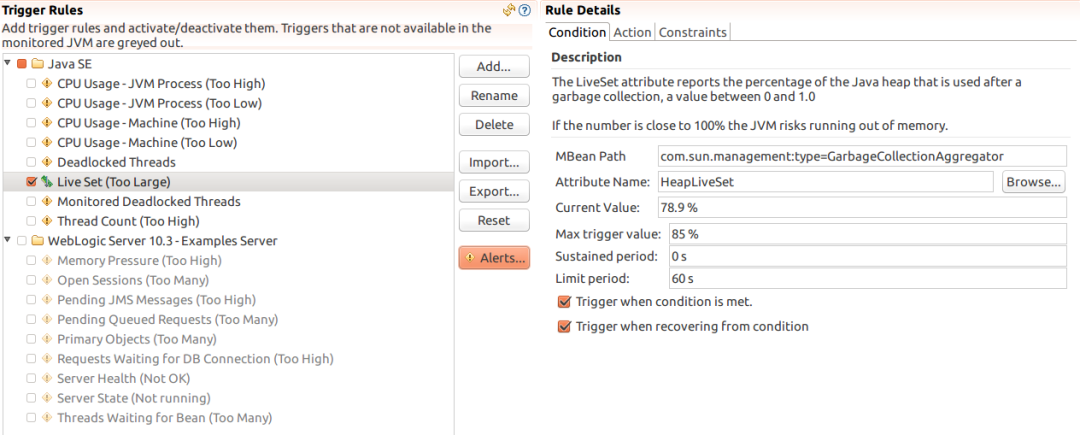
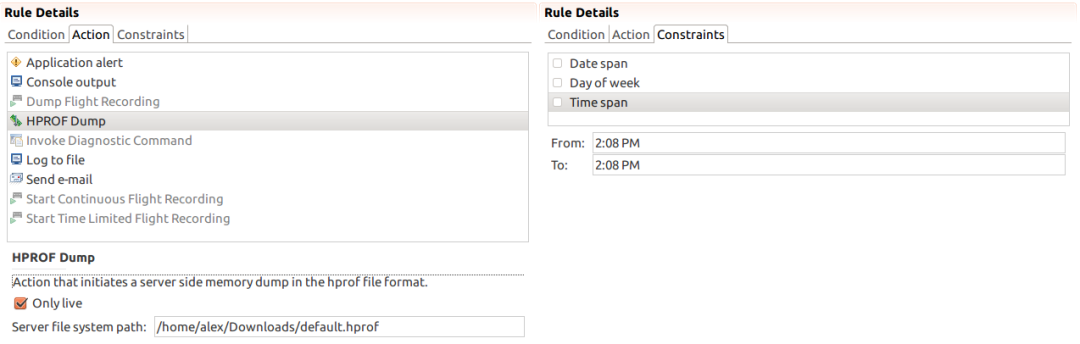
其中Condition面板:
- Current Value为指标的当前值,当发生GC后,自动刷新
- Max trigger value为触发器激活时的指标值
- Sustained period,指标必须到达Max trigger value至少多长时间,触发器才可能激活
- Limit period,连续两次激活触发器的最小间隔时间
其中Action面板:
- Only live,如果勾选,仅仅GCRoot可达的对象才被Dump出来
- hprof路径为服务器的路径
其中Constraints面板:可以指定此触发器在什么日期、什么时间段启用。
要分析内存映像,你可以使用如下命令启动一个Web UI:
jhat -port 7770 -J-Xmx4G default.hprof
4.4.5 系统
显示JVM和系统的概要信息,包含3个面板:
- 系统信息:例如OS类型、硬件架构、系统内存、JVM的PID、JVM版本、Classpath、JVM启动时间、JVM参数(Java Options)
- JVM统计:例如已加载的类数量、已运行时间
- 系统属性:显示JVM的系统属性
4.4.6 内存
显示JVM内存占用情况,分为上下两个面板。
|
面板 |
说明 |
|
GC Table |
显示垃圾回收器(ParNew:新生代的并行回收器,ConcurrentMarkSweep:并发垃圾回收器…)的工作情况,包括:GC总计时间、GC总次数、最近GC开始结束时间、GC标识符、GC线程数 |
|
Active Memory Pools |
显示当前的内存池的大小、已用大小、类型(堆/非堆),可能有以下内存池: Code Cache:代码缓存 Par Eden Space:并行(-XX:+UseParNewGC)垃圾回收的新生代Eden区 Par Survivor Space:并行垃圾回收的新生代Survivor区 CMS Perm Gen:并发垃圾回收永久代 CMS Old Gen:并发垃圾收集年老代 PS Old Gen:并行(-XX:+UseParallelGC)垃圾收集年老代 关于垃圾回收器内存分代。 |
4.4.7 线程
显示JVM线程活动情况,分为三个面板。
|
面板 |
说明 |
|
Live Thread Graph |
显示当前存活线程的数量、守护线程的数量、线程数量峰值的实时曲线 |
|
Live Threads |
显示当前存活线程的列表,可以进行CPU占用分析、死锁检测、线程分配内存量的分析 |
|
Stack traces for selected threads |
显示瞬时的线程调用栈 |
4.5 启动JMC
JMC可以用于事后分析系统性能低下,甚至崩溃的原因。JMC支持两种方式来启动黑匣子记录:通过触发器自动启动, 或者在左侧面板,双击Flight Recorder,手工启动。手工启动可以参考下图设置:
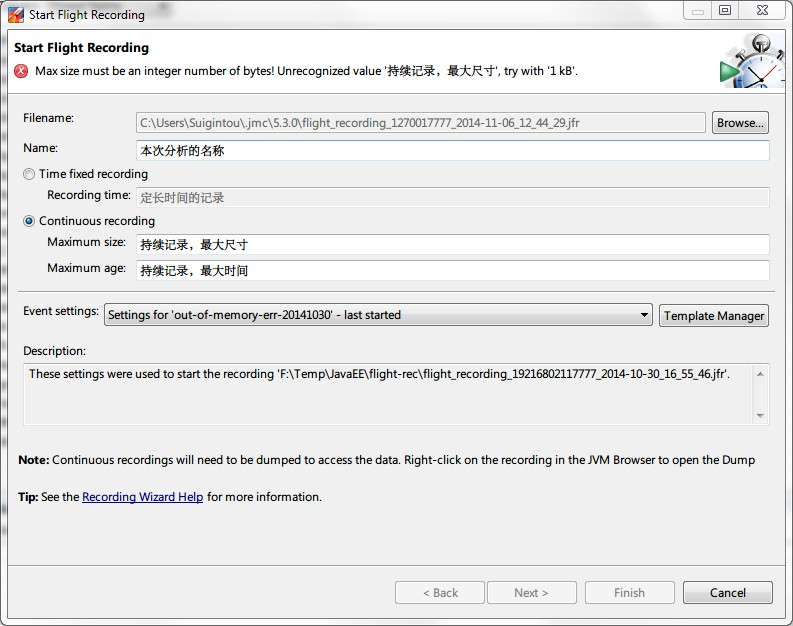
其中:Time fixed recording表示记录定长时间,时间到达后,自动停止记录;Continuous recording表示进行持续不断的记录,直到JVM退出或者接收到停止指令,这种记录方式下可以随时进行dump操作。
虽然黑匣子在JVM本地记录数据,但不在Java堆中记录,因此它并不会影响内存特性和垃圾收集。
黑匣子录制完成后,会在你选择的目录中生成一个.jfr文件,该文件包含录制期间JVM中发生的各种事件。
4.5.1 工作机制
黑匣子通过JVM内部API来收集数据,并存放在一个线程本地(thread-local)的缓冲中,并最终刷入全局内存缓冲(global in-memory buffer),内存缓冲中的数据,会被刷入磁盘,磁盘文件时经过压缩的。
每个记录数据块,要么在内存中,要么在磁盘中,这意味着——进程被停止或者宕机时,部分数据会丢失,JVM崩溃会也可能导致一部分数据丢失。
可以配置黑匣子不使用磁盘空间,这种场景下,全局内存缓冲被循环使用,旧的数据自动丢弃。
4.5.2 黑匣子记录模板
在JMC界面上,点击 Windows - Flight Recording Template Manager,看到类似如下界面。可以导入、导出、编辑JFR的设置文件。
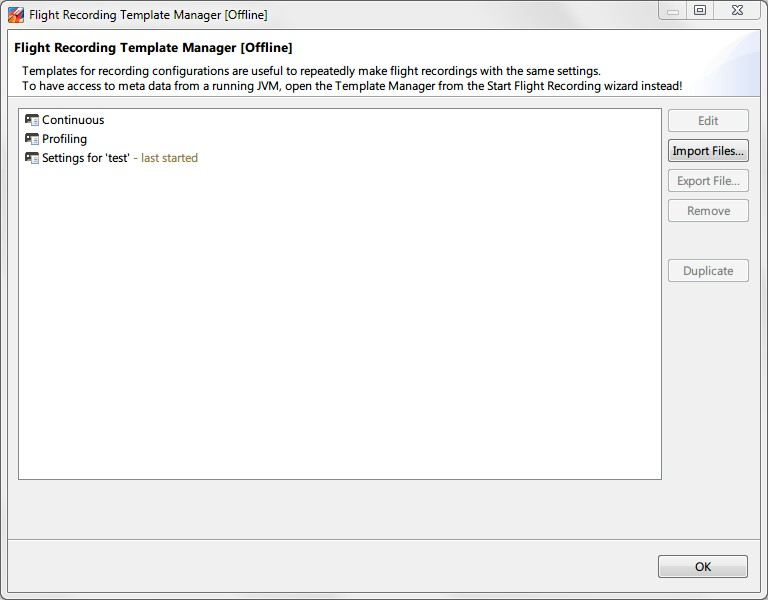
我们可以导入%JDK_HOME%\jre\lib\jfr下的两个自带模板:default.jfc(Continuous)、profile.jfc(Profiling)。这两个模板的对比如下:
|
模板 |
特性 |
|
Continuous |
Garbage Collector:正常 Compiler:正常 Method Sampling: 正常 Thread Dump: 最少一次 Exceptions:仅Error Synchronization Threshold: 20 ms File I/O Threshold: 20 ms Socket I/O Threshold: 20 ms Heap Statistics: 禁用 Class Loading:禁用 Allocation Profiling:禁用 未启用记录的事件类型:Exception Throw、Object Alloc In New TLAB、Object Alloc Outside TLAB、Class Loading、Compile/Failure、GC/Object Count、GC/Object Count After GC、GC/Phases/Phase Level 3、Profiling/Execution Sample Info、 |
|
Profiling |
Garbage Collector:正常 Compiler:详细 Method Sampling: 最大化 Thread Dump: 每分钟 Exceptions:仅Error Synchronization Threshold: 10 ms File I/O Threshold: 10 ms Socket I/O Threshold: 10 ms Heap Statistics: 禁用 Class Loading:禁用 Allocation Profiling:启用 未启用记录的事件类型:Exception Throw、Class Loading、GC/Object Count、GC/Object Count After GC、GC/Phases/Phase Level 3、Profiling/Execution Sample Info、 |
4.7 黑匣子诊断命令
利用诊断命令,可以通过脚本控制黑匣子的行为,命令的示例如下:
rem 获取进程号为5361的JVM关于JFR.start命令的帮助
jcmd 5361 help JFR.start
rem 检查进程的JFR运行状态
jcmd 7648 JFR.check
rem 输出如下。注意recording=0表示正在运行的记录的标识符,后续操作需要用到这个标识符
rem 7648:
rem Recording: recording=0 name="HotSpot default" maxage=1h (running)
rem 启动一个15分钟的黑匣子记录,延迟5分钟启动,使用JDK自带的默认设置(default.jfc),保存Dump文件到D盘
jcmd 7648 JFR.start name=SampleRcd delay=300 duratinotallow=900s filename=D:\temp\SampleRcd.jfr
\ settings=D:\JavaEE\jdk\x64\jre\lib\jfr\default.jfc
rem 相对路径取决于目标JVM
jcmd 1234 JFR.start delay=0s duratinotallow=${jfr_du}s name=$name filename=$PWD/$name.jfr settings=profile
rem 下面的脚本,可以用于定期进行记录,按记录时间保存为不同的文件
setlocal
set DUMP_DIR=D:\temp
set SERVICE_NAME=Tomcat7
set JAVA_HOME=D:\JavaEE\jdk\x64\1.7
pushd %JAVA_HOME%\bin
for /f "tokens=1-3 delims=/ " %%a in ('date /t') do (set md=%%a-%%b-%%c)
for /f "tokens=1-3 delims=/:." %%a in ("%TIME%") do (set mt=%%a%%b%%c)
set CUR_TIME=%md%-%mt%
for /F "tokens=1,3" %%a in ('sc queryex %SERVICE_NAME%') do (
if"%%a" == "PID"set"JPID=%%b"
)
rem 启动飞行记录,如果目标JVM是以SYSTEM身份启动的NT Service,可以使用PSTools发起jcmd命令,否则会报错:insufficient memory or insufficient privileges to attach
rem psexec -s jcmd %JPID% JFR.start ...
jcmd %JPID% JFR.start name=rcd-%CUR_TIME% duratinotallow=900s compress=true filename=%DUMP_DIR%\rcd-%CUR_TIME%.jfr settings=%JAVA_HOME%\jre\lib\jfr\profile.jfc
popd
endlocal
rem 导出JFR的Dump文件
rem 如果目标JVM正在在运行持续不断的黑匣子记录,使用该命令,再结合定时任务机制,可以定期保存黑匣子记录的Dump文件
jcmd 7648 JFR.dump recording=0 filename=F:\temp\dump.jfr
4.7.1 命令列表
|
命令 |
说明 |
|
JFR.start |
启动一个JFR(黑匣子记录)实例,参数: name 本次记录的名称 settings 服务器上的设置模板 defaultrecording 是否启动默认录制 delay 录制延迟时间,默认0s duration 录制持续时间,默认0s,表示无限 filename 录制文件的名称 compress 是否使用GZip压缩结果,默认否 maxage 数据最大生命周期,默认0s,表示无限制 maxsize 数据最大字节数,默认0,表示无限制 |
|
JFR.check |
显示运行中的JFR的状态,参数: name 记录名称 recording 记录标识符 verbose 打印冗余信息,默认否 |
|
JFR.stop |
停止运行中的JFR,参数: name 记录名称 recording 记录标识符 discard 是否丢弃录制数据 filename 拷贝录制数据到文件 |
|
JFR.dump |
将录制中的JFR保存到文件,参数: name 记录名称 recording 记录标识符 filename 拷贝录制数据到文件 |
4.8 黑匣子分析
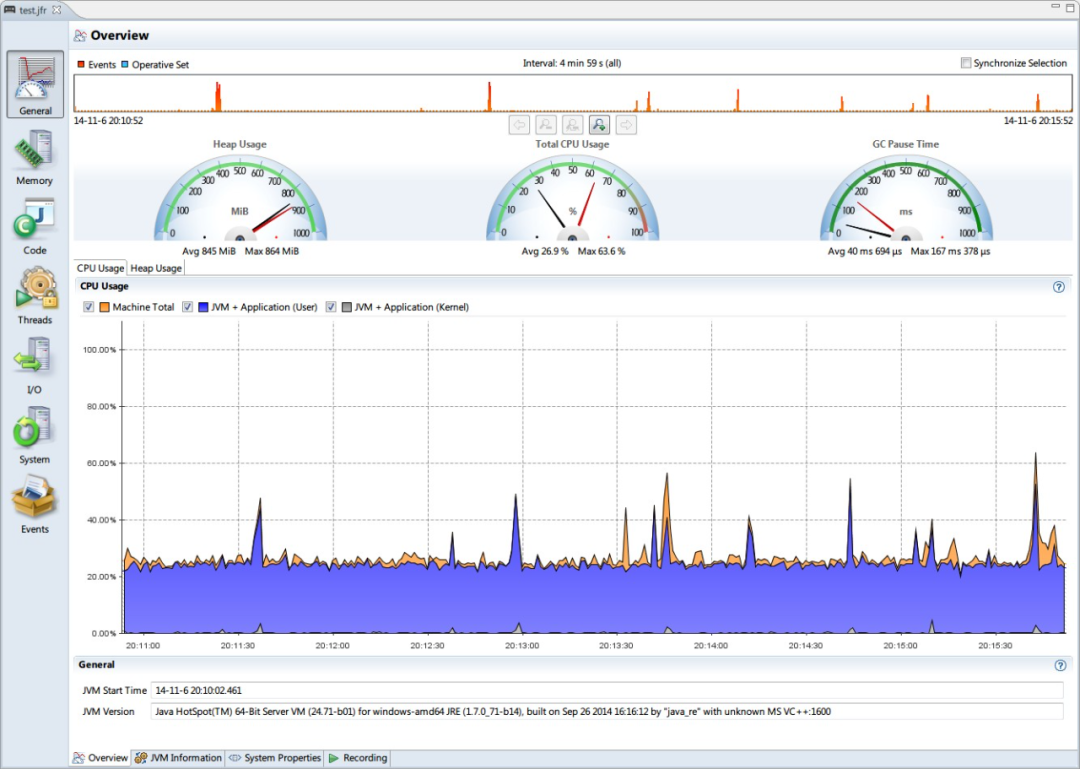
打开黑匣子记录的.jfr文件,即可看到类似下面的界面:左侧是记录的不同视图,可以点击切换;右侧主面板,顶部是事件的时间轴,拖动滑块,可以改变聚焦的时间范围(勾选右边的同步选择可以在切换视图时保持聚集范围),底部有若干选项卡。
4.8.1 基本信息
包含4个选项卡:
总览
可以看到聚焦时间范围内的实时仪表(堆占用、CPU占用、GC停顿时间),以及CPU、堆使用情况的曲线图。
JVM信息
可以看到JVM的一些基本信息,包括启动时间、JVM参数等。
系统属性
可以看到JVM的系统属性列表
记录
可以显示记录的事件的列表
内存
包含6个选项卡
总览
Memory Usage:可以显示聚焦时间范围内OS总内存、OS已使用内存、提交的堆、使用的堆的大小曲线图。
GC Configuration:显示简单的GC配置
GC Statistics:显示简单的GC统计,包括垃圾回收次数、停顿时间
垃圾收集
上面的面板,包含4个选项卡:
Heap:堆的使用情况曲线,红色小柱形显示了GC停顿的持续时间(刻度在右边)
Reference Objects:包含软引用、弱引用、幻引用、一般引用的数量变化区域图
Failed Promotions:失败的晋升列表,所谓晋升是指:年轻代对象向年老代转移的GC动作,包含对象个数和大小等信息
Failed Evacuations:
下面的面板,左侧显示历次GC的列表,右侧显示单次GC的详细信息,如下:
General:显示GC类型、触发原因、ID、开始结束时间、暂停时间
GC Phase:GC每个步骤的开始和持续时间
Reference Objects:本次GC涉及的各类引用的数量
Heap:堆在GC前后的大小对比
Perm Gen:永久代在GC前后的大小对比
垃圾回收时间
显示各代、各次GC所消耗的时间
垃圾回收配置
显示GC的详细配置,包括GC基本配置、堆的配置、年轻代的配置
内存分配
显示聚焦时间范围内的内存分配统计信息
General:在线程本地分配缓冲(TLAB)内、外(即Eden区域)中分配的对象个数、内存大小。面板下部是内存分配大小按时间的柱形图
Allocation in new TLAB:在TLAB中分配的内存,按对象类型、或者按执行分配的线程的占比饼图;Allocation Profile可以剖析分配内存热点所在的调用栈
Allocation outside TLAB:在Eden区域的内存分配情况,包含的子选项卡同上
示例:
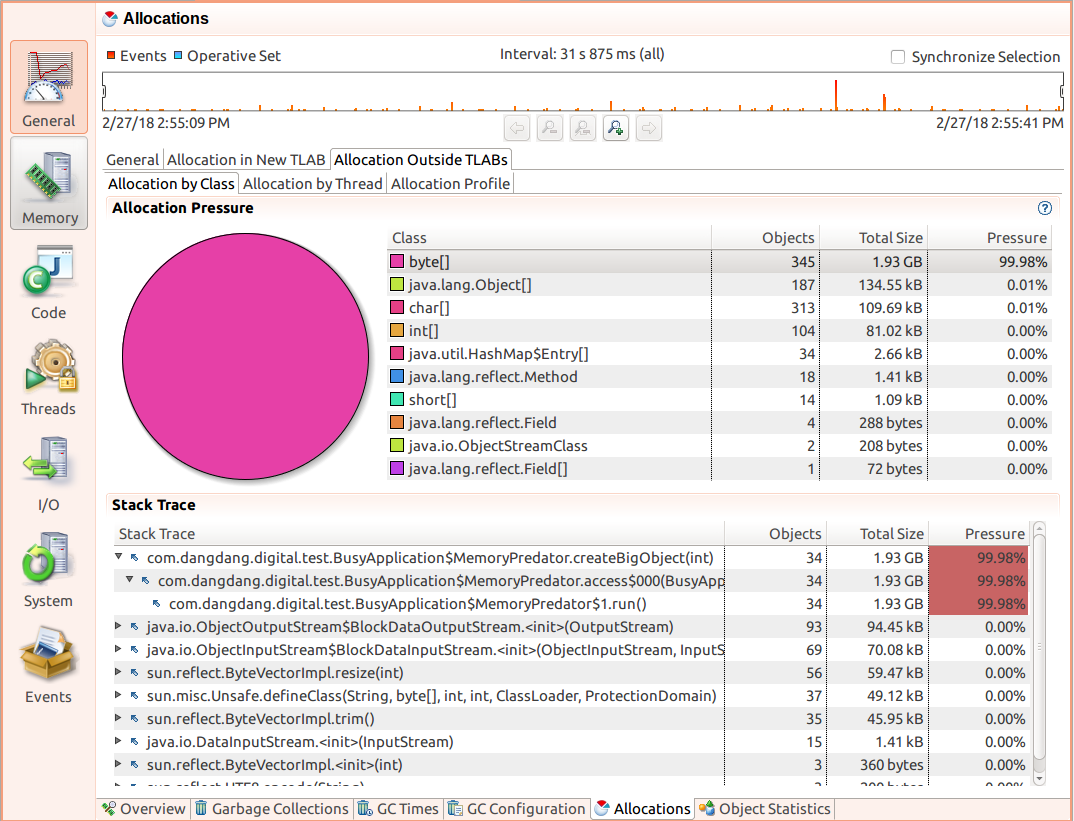
在Allocation By Class选项卡中:
- 上面板Allocation Pressure,按对象类型,显示内存占用最大的对象
- 下面板Stack Trace,选中上面板的某个对象类型后,在此显示分配对象的调用栈。第一行为直接分配对象的代码
4.8.2 对象统计
显示对象数量和内存占用的统计信息,包含上下两部分
上面的面板:显示占有堆内存百分比大于0.5%的类型的列表
下面的面板:显示增长数量最快的类型的列表
4.9 代码
包含6个选项卡:
4.9.1 总览
显示占用CPU时间最多的代码,分为上下两部分
上面的面板:显示CPU时间占用最多的包,包括列表和饼图
下面的面板:显示CPU占用最多的类,按占比降序排列
4.9.2 热点方法
显示热点方法(CPU占用时间最多),按占比降序排列,点击左侧小箭头可以向下钻取(找到哪些代码调用了这个方法导致的热点)
4.9.3 调用树
类似于热点方法选项卡,但是会显示所有热点方法的完整调用栈
4.9.4 异常
包含3个选项卡,显示异常(包括错误)的统计信息
Overview:显示异常和错误的总数、最频繁发生异常的调用栈
Exceptions、Error:单独显示异常或者错误的总数、频繁调用栈,注意,异常默认是不记录的
4.9.5 编译
显示即时编译的次数、编译大小、失败的日志
4.9.6 类加载
显示按时间的类加载、卸载的数量曲线图
4.10 线程
4.10.1 总览
分为上下两部分:
上面的面板:显示OS、JVM的CPU占用率的按时间统计的区域图
下面的面板:显示守护线程、活动线程数量的曲线图
4.10.2 热点线程
显示CPU占用最多的线程,及选中线程的热点方法,分为上下两部分
上面的面板:显示CPU占用最多的线程,按占比降序排列
下面的面板:显示上面板选中线程的热点方法、调用栈
4.10.3 资源争用
显示因为锁争用导致的线程阻塞的统计信息,分为3个选项卡:
Top Blocking Locks:发生阻塞最多的监视器(锁)对象的列表,包含了锁定次数、最长时间
Top Blocked Threads:因为等待锁被阻塞时间最长的线程的列表
Top Blocking Threads:因为占用锁导致其他线程等待时间最长的线程的列表
4.10.4 延迟
显示因为:Java线程休眠、监视器等待、Socket读取、监视器阻塞等原因导致的线程执行延迟的情况,包括延迟信息的列表和饼图,已经导致延迟的线程调用栈。延迟相关的事件包括:Java Thread Park(Waiting)、Java Monitor Wait(等待被唤醒)、Java Monitor Blocked(积极进入同步区被阻塞)等。
4.10.5 线程栈Dump
包含定时捕获的JVM中所有线程的瞬时调用栈镜像
4.10.6 监视器实例
Lock Instances:监视器对象的列表,包含锁定次数、总计持续时间
Trace Tree:选中监视器对象的锁定调用栈,每个调用栈锁定的次数
Top Threads:占用监视器次数最多的线程列表
4.11 输入输出
4.11.1 总览
分为两个选项卡
File Overview:
File Reads and Writes:显示按时间读写文件字节数的曲线
File Read、File Write:显示针对具体文件的读写字节数、次数的列表
Socket Overview:
Socket Read and Writes:显示按时间读写Socket字节数的曲线
Socket Read、Socket Writes:显示针对具体目标主机、端口读写字节数、次数的列表
4.11.2 读文件
按文件、线程、事件统计文件读操作的列表,以及每个文件读取按时间的变化、线程调用栈
4.11.3 写文件
按文件、线程、事件统计文件写操作的列表,以及每个文件写入按时间的变化、线程调用栈
4.11.4 读Socket
按目标主机、线程、事件统计文Socket读操作的列表,以及每个Socket读取按时间的变化、线程调用栈
4.11.5 写Socket
按目标主机、线程、事件统计文Socket写操作的列表,以及每个Socket写入按时间的变化、线程调用栈
4.12 系统
包含操作系统和硬件的基本信息
4.13 事件
显示黑匣子记录的事件的相关信息,左侧面板Event Types可以过滤关注的事件类型。总体来说,事件可以分为三类:持续事件(duration,持续一段时间,例如GC事件);瞬时事件(instant,立即发生和结束,例如内存溢出);样本事件(sample,通过定期采样获取,例如栈dump)。
4.13.1 总览
Producers:显示事件生产者的列表,以及制造事件的占比饼图
Event Types:显示各类型事件持续总时间、次数,占比饼图
4.13.2 日志
显示每一个事件的记录,按时间排列,为每个事件显示:开始时间、结束时间、持续时间、产生事件的线程
4.13.3 图表
以时间轴的形式展示事件历史
4.13.4 线程
以列表形式展示各线程产生事件的数量、持续时间
4.13.5 调用栈跟踪
按产生事件持续时间长短,降序排列相关的调用栈
4.13.6 事件统计
可以按单个事件类型进行简单的统计分析,支持不同的分组方式,支持总数、平均数、次数等指标,选中单个统计结果,可以显示调用栈。
五、Arthas获取调用耗时
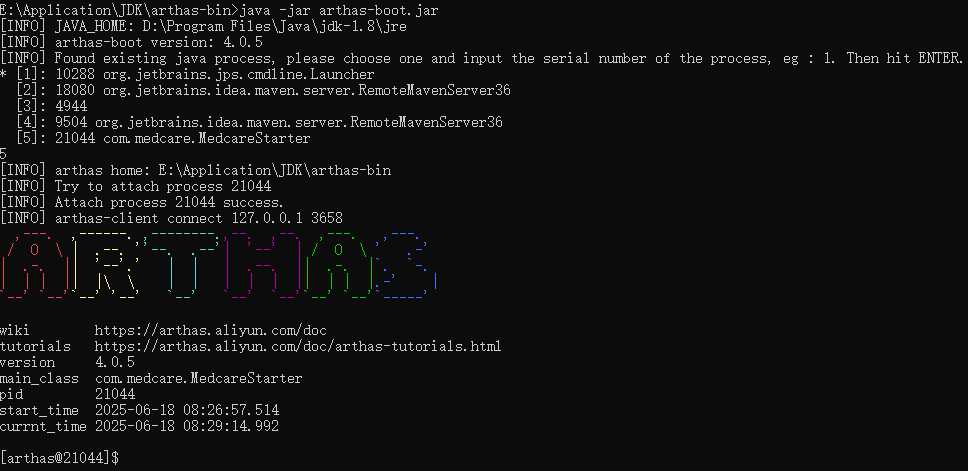
Arthas是阿里巴巴开源的一款线上监控诊断产品,通过全局视角实时查看应用 load、内存、gc、线程的状态信息,并能在不修改应用代码的情况下,对业务问题进行诊断,包括查看方法调用的出入参、异常,监测方法执行耗时,类加载信息等,大大提升线上问题排查效率。
官网为:https://arthas.aliyun.com
启动Arthas进入某个运行的Java进程界面如下所示。
有时在生产环境发现某个接口耗时非常高,但是又无法定位到具体的问题原因,可以使用Arthas的trace命令进行分析,trace命令能主动搜索 class-pattern/method-pattern对应的方法调用路径,渲染和统计整个调用链路上的所有性能开销和追踪调用链路。
5.1 trace查看方法整体耗时
基础语法:trace 全路径类名 方法名
$ trace demo.MathGame run
Press Q or Ctrl+C to abort.
Affect(class-cnt:1 , method-cnt:1) cost in 28 ms.
`---ts=2025-06-16 00:45:08;thread_name=main;id=1;is_daemnotallow=false;priority=5;TCCL=sun.misc.Launcher$AppClassLoader@3d4eac69
`---[0.617465ms] demo.MathGame:run()
`---[0.078946ms] demo.MathGame:primeFactors() #24 [throws Exception]
`---ts=2025-06-16 00:45:09;thread_name=main;id=1;is_daemnotallow=false;priority=5;TCCL=sun.misc.Launcher$AppClassLoader@3d4eac69
`---[1.276874ms] demo.MathGame:run()
`---[0.03752ms] demo.MathGame:primeFactors() #24 [throws Exception]
提示结果里的 #24,表示在 run 函数里,在源文件的第24行调用了primeFactors()函数。
5.2 trace次数限制
如果方法调用的次数很多,那么可以用-n参数指定捕捉结果的次数。比如下面的例子里,捕捉到一次调用就退出命令。
基础语法:trace 全路径类名 方法名 -n 次数
$ trace demo.MathGame run -n 1
Press Q or Ctrl+C to abort.
Affect(class-cnt:1 , method-cnt:1) cost in 20 ms.
`---ts=2025-06-16 00:45:53;thread_name=main;id=1;is_daemnotallow=false;priority=5;TCCL=sun.misc.Launcher$AppClassLoader@3d4eac69
`---[0.549379ms] demo.MathGame:run()
+---[0.059839ms] demo.MathGame:primeFactors() #24
`---[0.232887ms] demo.MathGame:print() #25
Command execution times exceed limit: 1, so command will exit. You can set it with -n option.
trace命令的具体用法参见:https://arthas.aliyun.com/doc/trace.html。
Arthas的命令参见:https://arthas.aliyun.com/doc/commands.html。
六、通过wrk获取接口性能数据
wrk与ab类似,也是一款HTTP压测命令行工具。可以到链接:https://github.com/wg/wrk下载wrk。
6.1 安装wrk
这里以CentOS为例安装wrk,如下所示。
sudo yum groupinstall 'Development Tools'
sudo yum install -y openssl-devel git
git clone https://github.com/wg/wrk.git wrk
cd wrk
make
# 将可执行文件移动到 /usr/local/bin 位置
sudo cp wrk /usr/local/bin
6.2 压测测试接口
假设要对 OpenResty程序的 hello 接口进行压测,我们可以使用以下命令:
wrk -c 100 -d 30s -t 4 --latency http://121.4.xxx.xx/hello
这条命令表示,利用 wrk 发起压力测试,连接数为 100,线程数为 4,持续 10 秒,并打印响应时间统计信息。
运行后,我们可以看到以下输出:
Running 30s test @ http://121.4.xxx.xx/hello
4 threads and 100 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 60.74ms 94.62ms 1.82s 88.81%
Req/Sec 710.91 118.29 1.02k 69.08%
Latency Distribution
50% 26.22ms
75% 32.99ms
90% 176.28ms
99% 475.41ms
84967 requests in 30.02s, 15.40MB read
Socket errors: connect 0, read 0, write 0, timeout 2
Requests/sec: 2829.91
Transfer/sec: 525.08KB
我们可以从输出中看到以下信息:
- 压测的配置和目标网址
Running 30s test @ http://121.4.xxx.xx/hello
4 threads and 100 connections
- 每个线程的平均、标准差、最大和正负一个标准差占比的响应时间(Latency)
Latency 60.74ms 94.62ms 1.82s 88.81%
这个数据和 QPS 一样重要,表示系统的响应速度,这个值越小越好。
- 响应时间的分布情况:即有多少比例的请求在某个时间内完成,延时的分布百分比详细打印也就是下面展示信息
Latency Distribution
50% 26.22ms
75% 32.99ms
90% 176.28ms
99% 475.41ms
- 总的请求数
Requests/sec: 2829.91
这个数据表示服务端每秒钟处理了多少请求,这个值越大越好。
七、本章总结
本章,主要给大家简单介绍了几款获取性能数据的工具,包含:nmon、jvisualvm、jmc、arthas、ark等,这里也只是简单的介绍了一些基本用法,起到抛砖引玉的作用,各个工具的详细用法,还是要小伙伴们深入学习。
希望本章内容能够为大家带来实质性帮助,我们一起搞定性能优化。
八、写在最后
在冰河的知识星球除了手写高性能敏组件和热更的RPC视频外,还有其他十几个项目,像DeepSeek大模型、手写线程池、手写高性能SQL引擎、手写高性能Polaris网关、手写高性能熔断组件、手写通用指标上报组件、手写高性能数据库路由组件、手写分布式IM即时通讯系统、手写Seckill分布式秒杀系统、手写高性能RPC、实战高并发设计模式、简易商城系统等等。
AI大模型学习福利
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

因篇幅有限,仅展示部分资料,需要点击文章最下方名片即可前往获取
二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

因篇幅有限,仅展示部分资料,需要点击文章最下方名片即可前往获
三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

因篇幅有限,仅展示部分资料,需要点击文章最下方名片即可前往获
四、AI大模型商业化落地方案

因篇幅有限,仅展示部分资料,需要点击文章最下方名片即可前往获
作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









