




随着 Vision-R1 、MM-Eureka 等工作将强化学习引入多模态推理,数学推理也得到了一定提升。然而,在逻辑性与知识系统性要求极高的数学任务中,模型仍然达不到像人类一样进行严密推理的水平,这一问题仍然是开放性难题。
本文作者来自北京邮电大学、腾讯微信、清华大学。共同第一作者为北京邮电大学博士生乔润祺与硕士生谭秋纳,其共同完成的代表性工作 We-Math 于 ACL 2025 发表,并曾在 CVPR、ACL、ICLR、AAAI、ACM MM 等多个顶会中有论文发表。本文的通讯作者为博士生导师张洪刚与微信视觉技术中心李琛,We-Math 系列工作为乔润祺在微信实习期间完成。

- 论文标题:We-Math 2.0: A Versatile MathBook System for Incentivizing Visual Mathematical Reasoning
- 论文链接:https://arxiv.org/abs/2508.10433
- 主页链接:https://we-math2.github.io/
- 代码链接:https://github.com/We-Math/We-Math2.0
- 数据集链接:https://huggingface.co/datasets/We-Math/We-Math2.0-Standard
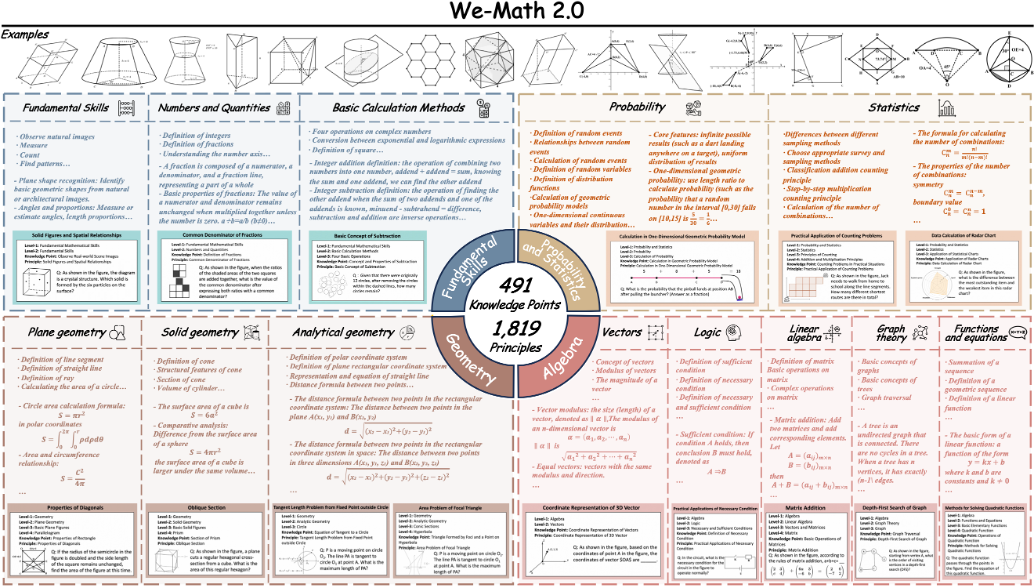
近期,多模态大模型在图像问答与视觉理解等任务中进展迅速。随着 Vision-R1 、MM-Eureka 等工作将强化学习引入多模态推理,数学推理也得到了一定提升。然而,在逻辑性与知识系统性要求极高的数学任务中,模型仍然达不到像人类一样进行严密推理的水平,这一问题仍然是开放性难题。
对此,我们仍然认为理想的学习范式应该是让模型先掌握所需的知识,再进一步提升泛化能力。基于这一思考,我们提出了 We-Math2.0:
1. MathBook Knowledge System:我们首先搭建了一个系统性、完整、相对正交的知识体系:包含 5 个层级,491 个知识点与 1819 个知识原理,覆盖了小学、初中、高中以及部分大学及竞赛的知识。
2. MathBook-Standard:基于知识体系,我们发现开源数据集存在无法完整覆盖、知识无法完成解构等问题,对此我们选择对每个知识体系进行手动构建题目、画图,并结合一题多图、一图多题两种思想,实现每个知识原理对应包含多个问题。
3. MathBook-Pro:我们希望进一步构造一个以模型为中心的数据空间来提升泛化能力。基于 MathBook-Standard 与知识体系,我们通过题目所需知识点数量、视觉复杂度、场景复杂度等三个维度对题目难度进行延展,将一条训练数据拓展为 8 个不同难度的样本。
4. 训练策略:基于所构建的数据集,我们首先通过 1000 条数据进行 SFT 冷启动微调,旨在改变模型的输出范式,进一步首先利用 MathBook-Standard 的数据,构建了均值奖励,旨在通过以知识原理为单位对模型进行奖惩。在此基础上,我们利用 MathBook-Pro 的数据,构建了动态调度训练(知识调度与模态调度)从而提升模型的泛化能力。
5. MathBookEval: 为了进一步评测模型在全面知识与推理深度层面的能力,我们提出了包含 1000 条样本的 MathBookEval
为了实现严谨、高质量、具备高复杂度的图像数据,我们的全部数据均为手动利用 Geogebra 专业化软件新渲染而成,我们希望先通过手动构造高精度的数据来验证这一思想的可行性。
目前不仅在 X 上收获了一定的关注度,并且荣登 Huggingface Paper 日榜第一名!
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 193
193

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









