




传统自动评估指标为何总与人类判断"脱节"?MAJ-EVAL框架通过"基于证据的角色构建"和"多智能体辩论机制",让自动化评估真正理解教育专家为何更关注"教育价值"而非"语法正确性"。这一创新解决了角色设计任意性和框架不可迁移性两大难题,更为NLP评估开辟了新范式。

大家好,我是肆〇柒,看到一个关于多 Agent 系统应用在“评估”的论文。这是一篇由斯坦福大学人机交互实验室和谷歌研究院联合发表的研究——MAJ-EVAL框架。这项工作解决了NLP长期存在的评估难题,通过创新的多智能体辩论机制,让自动化评估真正理解为什么教育专家更关注"教育价值"而非"语法正确性"。下面,我们一起看看这一框架如何从领域文档自动提取评估维度,以及多智能体辩论如何模拟真实人类评估过程,为构建真正对齐人类多维度评估的自动化系统提供新思路。
评估困境:当指标与人类判断"渐行渐远"
有这样一个假设的场景:精心开发了一个用于儿童教育的AI故事生成系统,ROUGE-L指标显示高质量,但教育专家却皱着眉头说:"内容缺乏教育价值"。这种评估断层在医疗、法律等专业领域尤为突出——传统自动评估指标只能衡量表面相似度,无法捕捉"儿童教育适宜性"或"干预效果方向"等关键维度。
问题出在哪里?现有评估方法面临两大根本挑战。首先是角色设计的任意性:手工定义的"教师"或"医生"角色缺乏客观依据。在ChatEval中,"批评者"角色在不同任务中可能表现出截然不同的评估优先级,导致评估结果难以复现。例如,一项研究可能手工地为"教师"智能体设计关注"语法准确性",而另一项研究则可能让同一角色优先考虑"学生参与度",这使得研究结果无法在不同研究之间可靠地复制。
其次是框架的不可迁移性:为医疗摘要设计的"临床一致性"维度对儿童教育任务毫无意义,而"儿童参与度"对医疗摘要又不相关。这些维度硬编码在特定任务中,导致评估框架无法跨领域复用。例如,一个为医疗摘要设计的评估流水线可能包含维度如"临床一致性",但这些维度对类似儿童教育的摘要任务并不适用,后者更需要"儿童参与度"等指标。由于这些维度和角色定义针对特定任务硬编码,评估框架通常需要完全重新设计才能处理新领域,这严重限制了其可扩展性和可转移性。
正如研究中指出:"在评估儿童互动故事内容时,教师可能优先考虑教育价值,而家长则关注情感互动。这种多样性既必要又难以通过传统人类评估协议规模化。"在现实世界中,由于多利益相关者的复杂性,如护理人员、家庭护理人员和患者在评估LLM生成的患者摘要时有不同的需求,而评估儿童阅读理解的LLM生成问答对则需要儿童、家长和教师的反馈。
更为关键的是,现有方法未能充分模拟真实世界中多利益相关者如何讨论、辩论并最终达成评估共识的过程。人类评估中的反思、挑战和修正环节在自动化评估中常被简化或忽略,导致评估结果缺乏深度和全面性。
从"单一裁判"到"专家委员会":评估范式的根本转变
MAJ-EVAL (Multi-Agent-as-Judge Evaluation)框架应运而生,通过两大创新解决了上述痛点:基于证据的角色构建和多智能体辩论机制。这一框架代表了从"单一裁判"向"专家委员会"演进的评估范式,更贴近真实世界复杂评估需求。
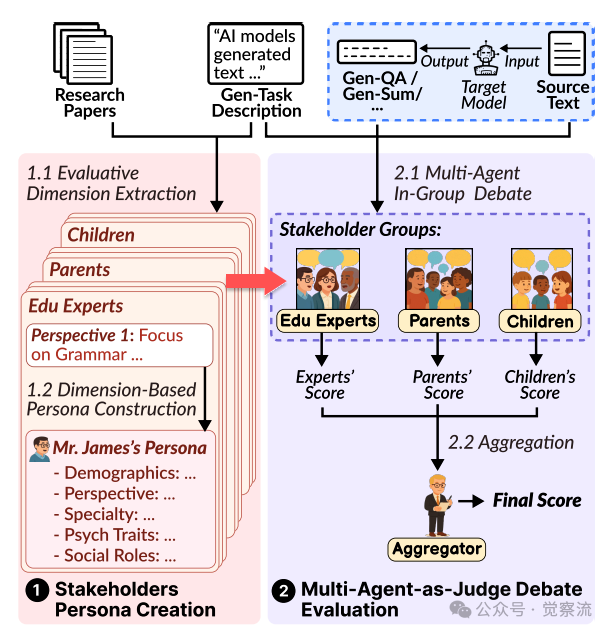
MAJ-EVAL框架概述
上图,MAJ-EVAL的两步设计流程。第一步,从研究文献中提取利益相关者视角并构建角色;第二步,通过多智能体辩论生成评估结果。
为什么我们需要这种转变?因为在当今社会,几乎所有人类工作都具有协作性质,这意味着现实世界中NLP应用的评估往往需要考虑多个维度,以反映不同人类视角的多样性。在儿童故事书问答生成任务中,教师关注"问题是否能激发批判性思维",家长重视"问题是否能促进情感互动",而孩子们最关心的是"问题是否有趣"。同样,在医疗摘要评估中,临床医生重视"干预效果方向是否明确",患者则希望"语言通俗易懂",而护理人员可能更关注"护理建议的实用性"。
传统自动评估指标如ROUGE-L、BLEU和BERTScore虽然简单可扩展,但主要计算生成文本与参考文本之间的词汇级或嵌入级相似度,无法评估深层的上下文理解、事实正确性和任务特定适宜性。例如,在医疗摘要生成中,ROUGE可能无法惩罚那些表达流畅但缺乏证据支持的幻觉内容;研究指出:"该摘要传达了当前证据的一般不确定性和局限性,但在临床应用、医学教育和AI驱动决策支持所需的精确性和特异性方面有所欠缺。"在儿童教育QA生成中,词汇相似度无法判断问题是否具有教育意义。研究发现,家长对AI工具的评价是"很愚蠢",实质是表达对缺乏启发性问题的不满——AI生成的问题往往"严肃专业",不符合儿童认知水平和心理年龄,导致孩子难以理解。比如,有研究指出:"我们的参与者表示,当他们使用工具如C5和C6回答儿童故事相关问题时,生成的答案往往严肃专业,没有特别针对儿童的认知水平和心理年龄,导致孩子难以理解。"
为解决这些挑战,"LLM-as-a-Judge"(Large Language Model-as-a-Judge)范式被提出,利用大型语言模型(LLM)替代人类评估者。单LLM评估方法如G-Eval通过链式思维提示引导GPT-4进行结构化评估,而PandaLM则微调LLaMA-7B模型用于偏好排序。然而,这些方法存在"单一模型偏差",其判断受限于模型自身的训练数据和推理风格,难以模拟真实世界评估所需的多利益相关者视角。
多智能体框架进一步扩展了这一范式,使用多个扮演不同角色的LLM智能体进行协作或辩论以达成最终评估。例如,ChatEval为智能体分配"公众"或"批评者"等预定义角色,而MADISSE则将评估框架化为持有对立初始立场的智能体之间的辩论。尽管前景广阔,现
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









