



Stable Diffusion 究竟是如何施展它的魔法,将我们输入的文字描述转化为一幅幅精美绝伦的图像的呢?今天,就让我们一同揭开它神秘的面纱,深入探索其背后的工作原理。

在当今数字化时代,AI 绘画技术以其令人惊叹的创造力和表现力,为我们开启了一个全新的视觉艺术世界。其中,Stable Diffusion 作为一款开源的文本到图像生成模型,更是备受瞩目,成为众多艺术家、设计师和创意爱好者的得力助手。
那么,Stable Diffusion 究竟是如何施展它的魔法,将我们输入的文字描述转化为一幅幅精美绝伦的图像的呢?今天,就让我们一同揭开它神秘的面纱,深入探索其背后的工作原理。
什么是 Stable Diffusion
简单来说,Stable Diffusion 是一个 文本生成图像(Text-to-Image)的深度学习模型。它的神奇之处在于:只要给它一个文字提示(Prompt),它就能一步步把一张“噪声图”变成一幅有意义的画作。
和 DALL·E、Midjourney 等 AI 相比,Stable Diffusion 最大的特点是 开源,这意味着任何人都可以在本地运行、修改和扩展它,从而诞生了各种各样的玩法和应用。
核心原理:从噪声到图像的逆向过程
Stable Diffusion 背后的基本思路叫做 扩散模型(Diffusion Model),其核心思想是学习数据分布的生成过程。

1. 正向扩散(破坏图片)
假设我们有一张正常的图片,Stable Diffusion 会不断往里面添加随机噪声。
- 一开始图片还能看清内容
- 加到中间时,模糊得像被撒满沙子
- 最终,它会变成一张纯噪声图
这个过程就像不断往水里滴墨水,直到水完全变黑,看不出原来的样子。
2. 逆向扩散(生成图片)
AI 的训练目标就是 学会逆向这个过程:从一张噪声图中,逐步“去掉”噪声,恢复出一张清晰的图像。而在文本生成图像的场景里,AI 还要根据输入的提示词,把“恢复出来的图像”变成符合描述的画面。
换句话说:👉 训练时,AI学的是“如何从清晰图到噪声图”;👉 生成时,AI做的是“如何从噪声图回到清晰图”。
这就是扩散模型的核心逻辑。
Stable Diffusion 关键技术
Stable Diffusion 并不是简单的扩散,而是有几个“黑科技”加持:
1. 潜空间(Latent Space)
直接在高清图片上加噪声、去噪,计算量会非常大。为了解决这个问题,Stable Diffusion 使用了一个 变分自编码器(VAE),先把图片压缩到一个更小的潜空间(Latent Space)里,再进行扩散和去噪。
这样做的好处是:
- 节省计算资源(显卡更容易跑得动)
- 还能保留图片的主要特征
2. 文本理解(CLIP 模型)
AI 怎么知道“赛博朋克”是什么样的风格?这里就要用到 OpenAI 提出的 CLIP 模型。它能把文字和图像转化到同一个语义空间,从而帮助 Stable Diffusion 理解提示词。
比如,你输入“猫”,CLIP 会让模型在潜空间里往“猫”的方向去修正。
3. U-Net 神经网络
真正负责“去噪”的,是一个叫 U-Net 的深度神经网络。它会在每一步迭代中,根据提示词信息,把噪声修正成更接近目标图像的样子。
可以理解为:
- VAE 负责压缩/解压图片
- CLIP 负责理解文字
- U-Net 负责逐步绘制
三者配合,才让“文字变图”成为可能。
Stable Diffusion 的生成流程
整个生成过程可以简化为四步:
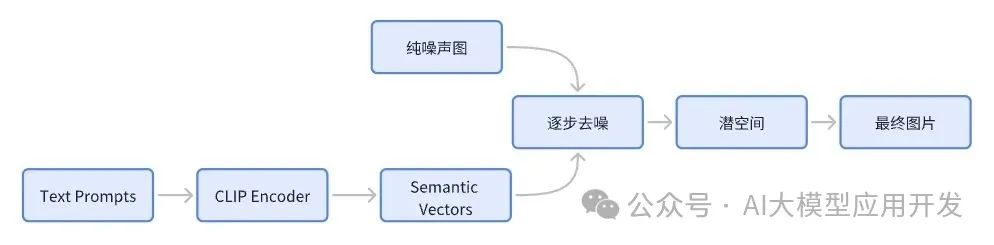
1. 随机起点:先生成一张纯噪声图
2. 逐步去噪:U-Net 每次迭代修正噪声
3. 受控引导:CLIP 根据提示词调整图像方向
4. 解码输出:VAE 把潜空间的结果还原为高清图片
最后,你就得到一张符合描述的 AI 绘画作品。
实战:ComfyUI+Stable Diffusion文生图
1. 安装uv和python 3.12
uv是一个用Rust编写的极其快速的Python包和项目管理器。
复制
powershell -ExecutionPolicy ByPass -c "irm https://astral.sh/uv/install.ps1 | iex"
uv安装成功后,安装python 3.12
uv python install 3.12
2. 安装ComfyUI
# 克隆代码
git clone https://github.com/comfyanonymous/ComfyUI
cd ComfyUI
# 创建虚拟环境
uv venv
.\.venv\Scripts\activate
python -m ensurepip
# 安装依赖
uv pip install torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/cu129
uv pip install -r requirements.txt
3. 下载模型
把模型下载到ComfyUI的models/checkpoints目录下。链接地址:https://huggingface.co/Comfy-Org/stable-diffusion-3.5-fp8/blob/main/sd3.5_medium_incl_clips_t5xxlfp8scaled.safetensors
4. 启动ComfyUI
通过uv run main.py启动服务。启动后,通过http://localhost:8188即可访问ComfyUI。
点击菜单【Workflow】 -> 【Browse Templates】,在弹出页面中选择模板"SD 3.5 Simple"
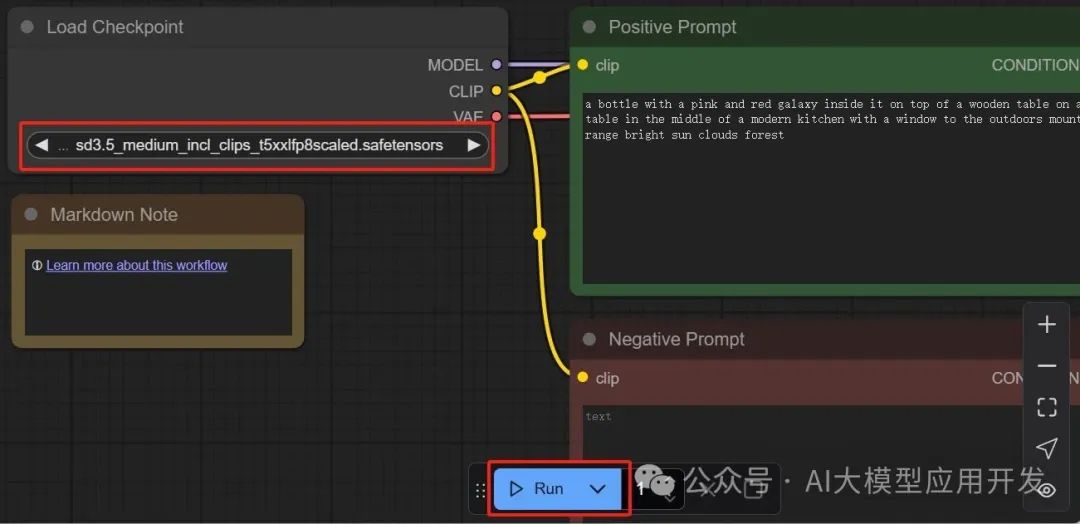
加载工作流后,调整模型为sd3.5_medium,按需调整提示词,点击下方【Run】即可生成图片
总结
Stable Diffusion 的原理,其实就是在潜空间里,借助扩散模型,从噪声中逐渐恢复出符合文字描述的图像。它结合了 VAE 的压缩、CLIP 的语义理解,以及 U-Net 的去噪能力,才让“文字变画”成为现实。

















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









