



本章我们介绍RoPE的概念,为后续的模型实现打好基础知识。

大家好,我是写代码的中年人!
本章我们介绍RoPE的概念,为后续的模型实现打好基础知识。
在大模型中,怎么知道一个词在句子里是第几个?这就像是:“你看一本书的时候,怎么知道这一句话是在第一页还是最后一页?”
嗯……要是没有“位置感”,模型看到的只是一个个孤立的词向量,就像你看一本书时只看到拆散的字母。
早期 Transformer 用的是正弦位置编码(Sinusoidal Positional Encoding),相当于在每个单词的向量里混入一点“坐标信号”,让模型知道它在句子里的位置。
但这玩意有个小问题:它是直接加在词向量上的,像在纸条上贴标签模型能用,但对长文本、超长依赖不太友好,而且它的“旋律”是固定的,灵活性有限,后来人们发明了 RoPE(Rotary Position Embedding),中文名“旋转位置编码”,它干的事情很酷:不是直接给你贴标签,而是给你旋转一个角度。
01、什么是RoPE
比如我们在组织一场广场舞,舞者(词向量)站在一个圆圈上,每两人一组。音乐响起时,每组舞者按自己的节奏旋转:
第一组慢转(低频,0°、10°、20°……),第二组稍快(30°、60°、90°……),以此类推。
模型通过比较两组舞者的相对旋转角度(相位差),就能知道他们离得多远,角度差越大,距离越远。旋转是连续的,即使新舞者加入(序列变长),他们也能按同样规则旋转,模型无需重新学习,就能判断新舞者的位置。
这就是RoPE的厉害之处:通过旋转的相位编码位置,高效捕捉相对距离,还能适应超长序列!
02、RoPE数学公式
在自注意力里,Q(查询向量)和 K(键向量)要做点积:
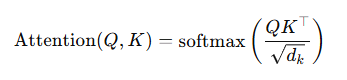
RoPE 的思路是:在做这个点积前,先把 Q、K 各自旋转一下:
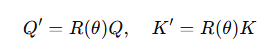
这里的 R(θ) 是一个二维旋转矩阵(其实是对向量的每一对分量旋转):
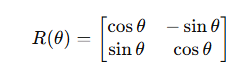
而 θ 跟位置 p 有关,比如:
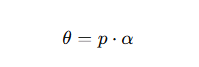
α是不同维度的频率参数,就像正弦编码那样安排。
结果是什么?
相对位置关系自然保留:Q 和 K 的旋转差值就是它们的相对位置
外推能力强:没见过的长序列也能用,因为旋转是周期性的
03、用代码实现RoPE
复制
# -*- coding: utf-8 -*-
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import jieba
import matplotlib.pyplot as plt
import numpy as np
plt.rcParams['font.sans-serif'] = ['SimHei'] # 中文字体
plt.rcParams['axes.unicode_minus'] = False
# ===== 准备《水浒传》样本文本 =====
text_samples = [
"""张天师祈禳瘟疫,洪太尉误走妖魔。话说大宋天子仁宗皇帝在位年间,
京师瘟疫流行,百姓多有染病。天子召张天师入宫祈禳,命洪太尉押送香火,
不料误开封印,放出妖魔。""",
"""王教头私走延安府,九纹龙大闹史家村。史进自幼好武,学成十八般武艺,
因打死恶霸,被官府缉拿。王进教头见势不妙,离开东京前往延安府,
途经史家村。""",
"""史大郎夜走华阴县,鲁提辖拳打镇关西。史进与鲁达结义,路遇镇关西郑屠,
见其欺压妇女,鲁达愤然出手,三拳打死郑屠,遂落草为寇。"""
]
# ===== 中文分词 =====
def tokenize_texts(text_list):
tokenized = []
for t in text_list:
words = list(jieba.cut(t))
words = [w.strip() for w in words if w.strip()]
tokenized.append(words)
return tokenized
sentences = tokenize_texts(text_samples)
# ===== 构建词表 =====
vocab = {}
for sent in sentences:
for w in sent:
if w not in vocab:
vocab[w] = len(vocab)
vocab["<PAD>"] = len(vocab)
vocab_size = len(vocab)
embed_dim = 32
seq_len = max(len(s) for s in sentences)
# 将句子转为索引,并pad
def encode_sentences(sentences, vocab, seq_len):
data = []
for s in sentences:
idxs = [vocab[w] for w in s]
if len(idxs) < seq_len:
idxs += [vocab["<PAD>"]] * (seq_len - len(idxs))
data.append(idxs)
return torch.tensor(data)
input_ids = encode_sentences(sentences, vocab, seq_len)
# ===== RoPE实现 =====
def apply_rope(x):
"""
支持输入维度:
- (B, T, D) 或
- (B, T, H, D)
返回相同形状,且对最后一维做 RoPE(要求 D 为偶数)
"""
orig_shape = x.shape
if len(orig_shape) == 3:
# (B, T, D) -> 转为 (B, T, 1, D) 方便统一处理
x = x.unsqueeze(2)
squeezed = True
else:
squeezed = False
# 形状为 (B, T, H, D)
# 现在 x.shape = (B, T, H, D)
bsz, seqlen, nheads, head_dim = x.shape
assert head_dim % 2 == 0, "head_dim must be even for RoPE"
device = x.device
dtype = x.dtype
half = head_dim // 2
# theta: (half,)
theta = 10000 ** (-torch.arange(0, half, device=device, dtype=dtype) / half) # (half,)
# seq positions: (seqlen,)
seq_idx = torch.arange(seqlen, device=device, dtype=dtype) # (seqlen,)
# freqs: (seqlen, half)
freqs = torch.einsum('n,d->nd', seq_idx, theta)
cos = freqs.cos().view(1, seqlen, 1, half) # (1, T, 1, half)
sin = freqs.sin().view(1, seqlen, 1, half) # (1, T, 1, half)
x1 = x[..., :half] # (B, T, H, half)
x2 = x[..., half:] # (B, T, H, half)
x_rotated = torch.cat([x1 * cos - x2 * sin,
x1 * sin + x2 * cos], dim=-1) # (B, T, H, D)
if squeezed:
x_rotated = x_rotated.squeeze(2) # back to (B, T, D)
return x_rotated
# ===== 多头注意力 with RoPE =====
class MultiHeadSelfAttentionRoPE(nn.Module):
def __init__(self, embed_dim, num_heads, dropout=0.1):
super().__init__()
self.embed_dim = embed_dim
self.num_heads = num_heads
self.head_dim = embed_dim // num_heads
self.dropout = dropout
self.q_proj = nn.Linear(embed_dim, embed_dim)
self.k_proj = nn.Linear(embed_dim, embed_dim)
self.v_proj = nn.Linear(embed_dim, embed_dim)
self.out_proj = nn.Linear(embed_dim, embed_dim)
self.last_attn_weights = None
def forward(self, x):
B, T, C = x.size()
q = self.q_proj(x).view(B, T, self.num_heads, self.head_dim)
k = self.k_proj(x).view(B, T, self.num_heads, self.head_dim)
v = self.v_proj(x).view(B, T, self.num_heads, self.head_dim)
# 应用 RoPE
q = apply_rope(q)
k = apply_rope(k)
# 注意力计算
attn_scores = torch.einsum('bthd,bshd->bhts', q, k) / (self.head_dim ** 0.5)
attn_weights = F.softmax(attn_scores, dim=-1)
attn_weights = F.dropout(attn_weights, p=self.dropout, training=self.training)
self.last_attn_weights = attn_weights.detach()
out = torch.einsum('bhts,bshd->bthd', attn_weights, v)
out = out.reshape(B, T, C)
return self.out_proj(out)
# ===== 模型训练 =====
embedding = nn.Embedding(vocab_size, embed_dim)
model = MultiHeadSelfAttentionRoPE(embed_dim, num_heads=4, dropout=0.1)
criterion = nn.MSELoss()
optimizer = optim.Adam(list(model.parameters()) + list(embedding.parameters()), lr=1e-3)
epochs = 200
for epoch in range(epochs):
model.train()
x = embedding(input_ids)
target = x.clone()
out = model(x)
loss = criterion(out, target)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if (epoch + 1) % 50 == 0:
print(f"Epoch {epoch+1}, Loss: {loss.item():.6f}")
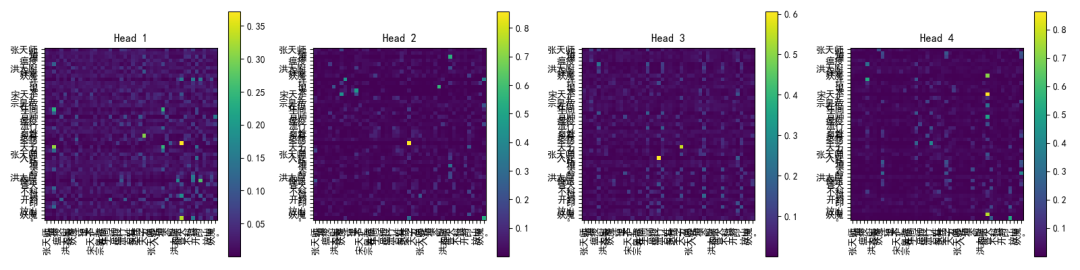
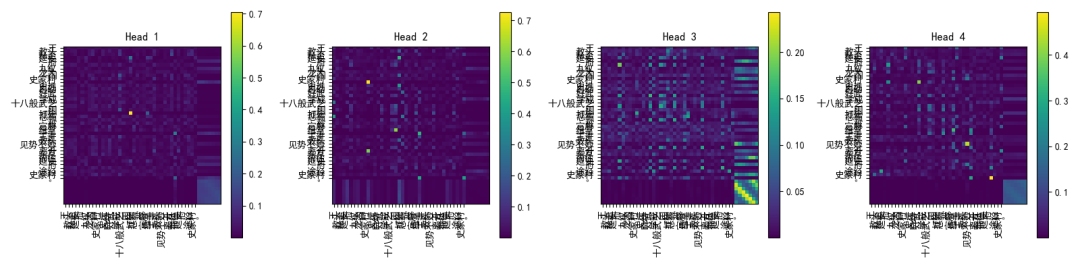
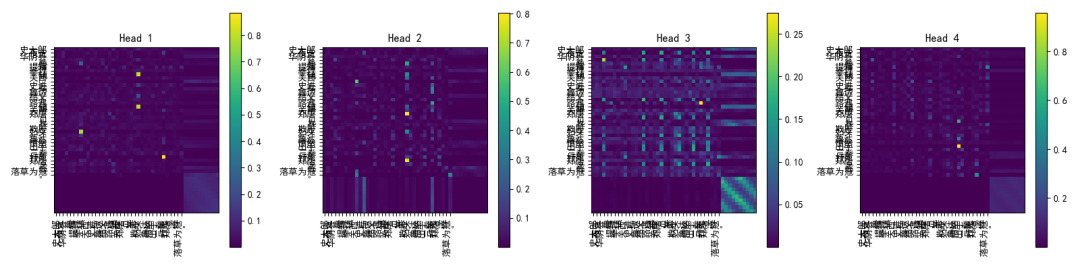
# ===== 注意力热图可视化 =====
def plot_attention(attn, sentence_tokens, filename):
heads = attn.shape[0]
fig, axes = plt.subplots(1, heads, figsize=(4*heads, 4))
if heads == 1:
axes = [axes]
for h in range(heads):
ax = axes[h]
attn_head = attn[h].numpy()
im = ax.imshow(attn_head, cmap='viridis')
ax.set_xticks(np.arange(len(sentence_tokens)))
ax.set_yticks(np.arange(len(sentence_tokens)))
ax.set_xticklabels(sentence_tokens, rotatinotallow=90)
ax.set_yticklabels(sentence_tokens)
ax.set_title(f"Head {h+1}")
fig.colorbar(im, ax=ax)
plt.tight_layout()
plt.savefig(filename)
plt.close()
model.eval()
with torch.no_grad():
x = embedding(input_ids)
_ = model(x)
attn_weights = model.last_attn_weights # (batch, heads, seq, seq)
for i, tokens in enumerate(sentences):
attn = attn_weights[i]
plot_attention(attn.cpu(), tokens, f"rope_attention_sentence{i+1}.png")
print("RoPE多头注意力热图已生成,文件名为 rope_attention_sentenceX.png")
结束语
经过这次实战,我们不仅从《水浒传》的古文中“偷”来了一点文学气息,还把它喂进了现代的多头自注意力网络里,加上 RoPE 旋转位置编码,让模型在捕捉长距离依赖关系时不再“迷路”。
通过可视化注意力热图,我们能直观看到词与词之间的微妙联系,就像在显微镜下观察一场无声的对话。这一切的意义,不仅仅是跑通了一段代码,更是把理论、实现与效果验证串成了一条完整的链条。
接下来,我们继续探索更多高级技巧!技术的世界没有终点,只有下一段旅程。
AI大模型学习福利
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

因篇幅有限,仅展示部分资料,需要点击文章最下方名片即可前往获取
二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

因篇幅有限,仅展示部分资料,需要点击文章最下方名片即可前往获
三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

因篇幅有限,仅展示部分资料,需要点击文章最下方名片即可前往获
四、AI大模型商业化落地方案

因篇幅有限,仅展示部分资料,需要点击文章最下方名片即可前往获
作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









