



值得注意的是,Qwen 官方宣布:“我们决定停止使用混合思维模式。”这意味着,在 A22B-2507 系列中,Instruct 与 Thinking 模型将分别独立训练与发布。尽管官方尚未详细解释背后原因,但混合思维一度被认为是行业趋势,Qwen 此举很可能是在技术层面有了新的发现。
Qwen 深夜上新!
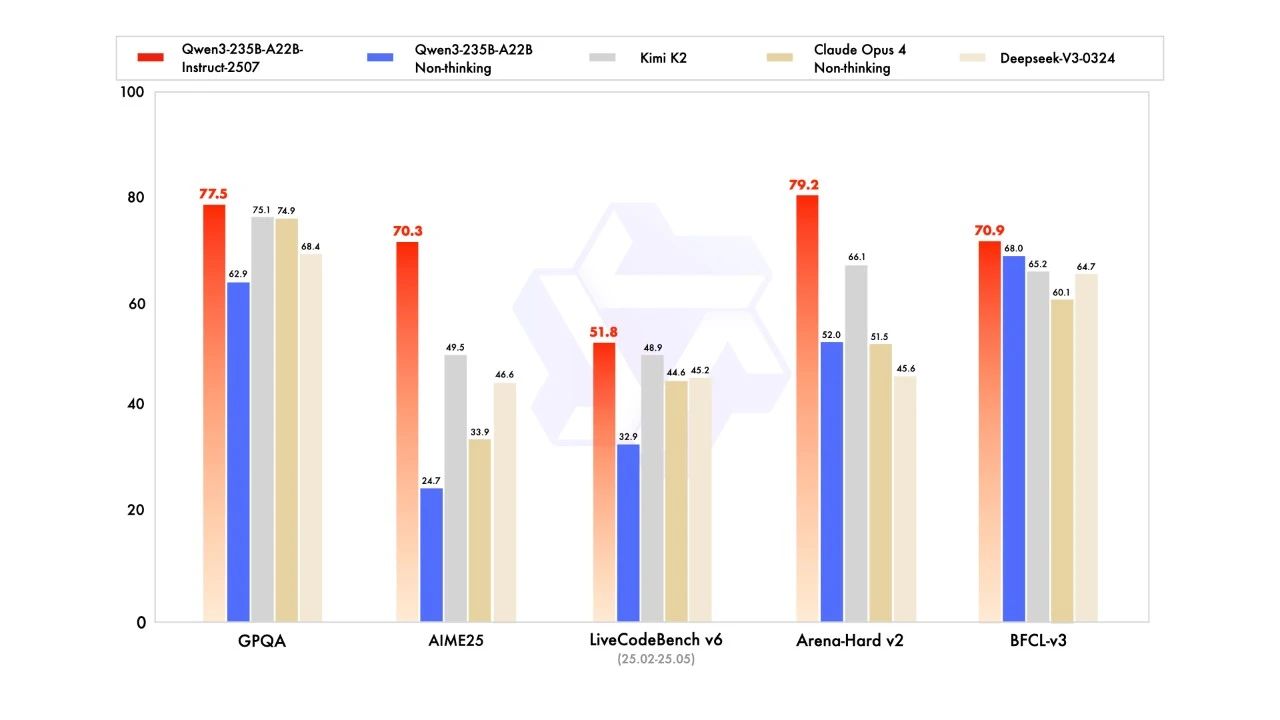
Qwen3-235B-A22B-2507 系列正式启动,今天率先登场的是非思考模型 —— Qwen3-235B-A22B-Instruct-2507。
在最新基准测试中,新模型全面超越 Kimi K2,开源王冠再度回到 Qwen 头上!
四大关键升级:
1.在通用能力方面有显著提升,包括:指令跟随、逻辑推理、文本理解、数学、科学、编程与工具使用等。
2.在多语言的长尾知识覆盖方面取得了实质性进展。
3.在主观性强和开放式任务中,对用户偏好的适配显著改善,生成的回答更有帮助,文本质量更高。
4.对 256K 超长上下文的理解能力也得到了增强。
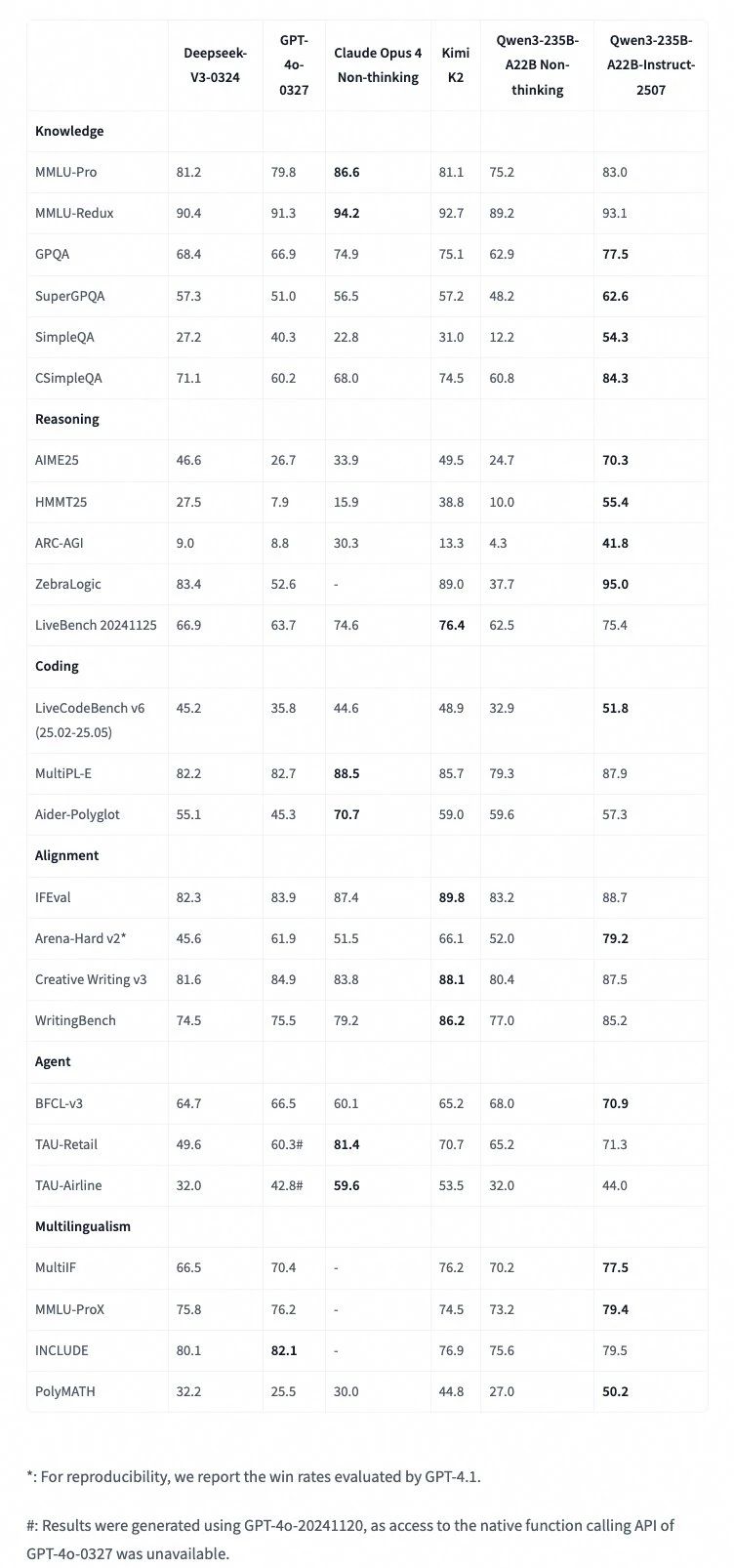
值得注意的是,Qwen 官方宣布:“我们决定停止使用混合思维模式。”
这意味着,在 A22B-2507 系列中,Instruct 与 Thinking 模型将分别独立训练与发布。尽管官方尚未详细解释背后原因,但混合思维一度被认为是行业趋势,Qwen 此举很可能是在技术层面有了新的发现。
有网友在评论区提到:看好这次更新,think模式会影响模型的指令遵循能力。不知道这个观点是否与官方不谋而合,Qwen后续技术报告,值得期待!
Qwen 也放出预告:“今天只是一个小更新,更大的更新即将到来!”

















 1301
1301

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









