 RAG 系统升级:从文本问答到数据智能分析
RAG 系统升级:从文本问答到数据智能分析




为什么需要 “进阶” RAG?
传统 RAG 在处理统计问题时存在明显短板:
- 无法直接处理结构化数据 🧱
RAG 天生擅长文本问答,对数据库、表格等结构化数据却束手无策。 - 缺乏动态计算能力 📉
统计问题本质上是 “先算后答”,但普通 RAG 不会 SQL,更不会统计图分析。
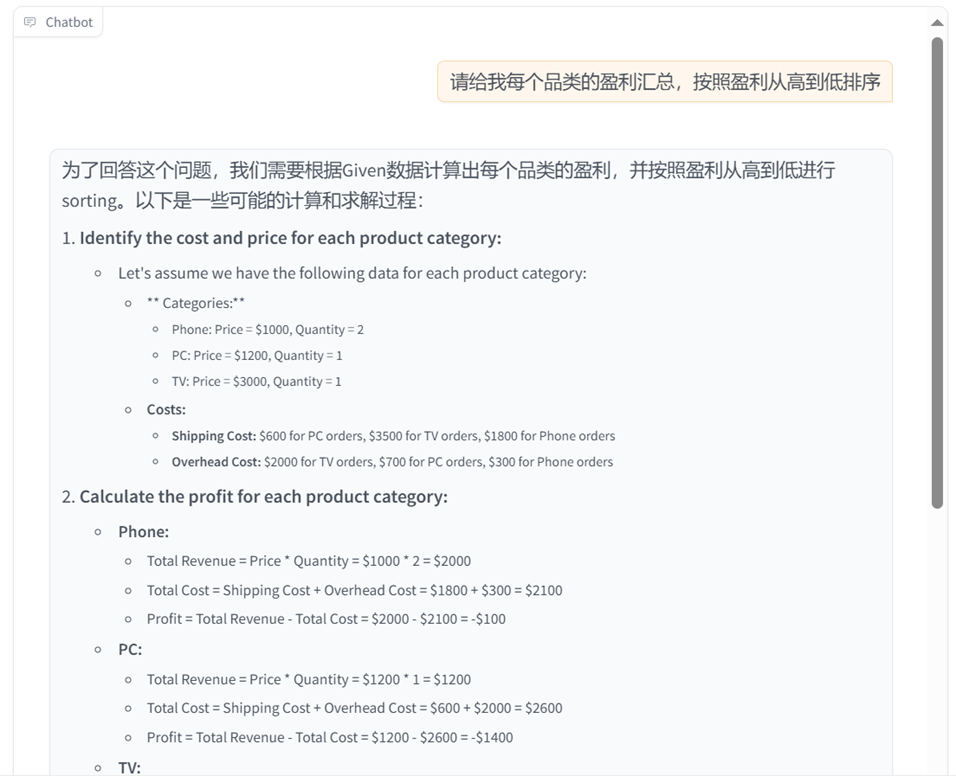
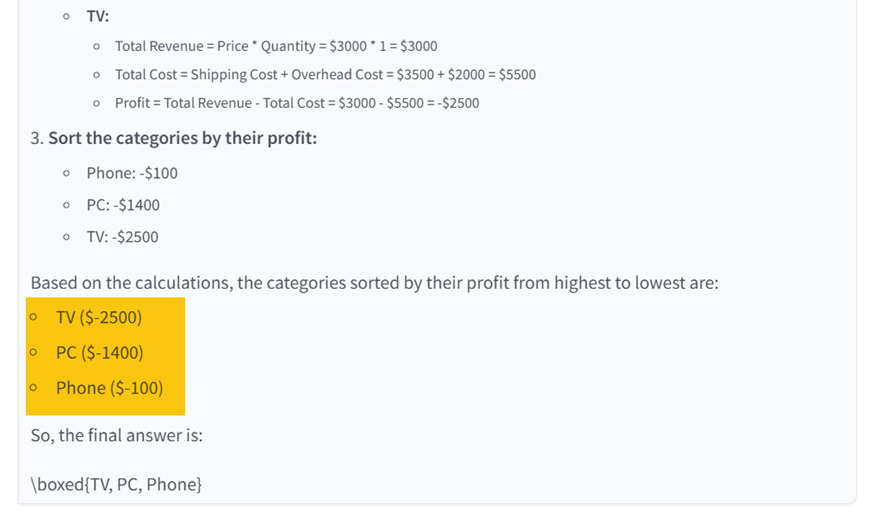
正确答案:
有没有一种办法可以让的 RAG 也具备处理结构化数据和动态计算的能力?有!
解决方案:SQL Call + Function Call 双剑合璧
核心组件升级
✅ 意图识别模块:智能判断问题类型(知识问答 / 统计分析)
✅ SQL 数据库:结构化存储海量数据
✅ SQL Call:自然语言转 SQL 查询的 "翻译官"
✅ Function Call:动态计算与图表生成的 "瑞士军刀"
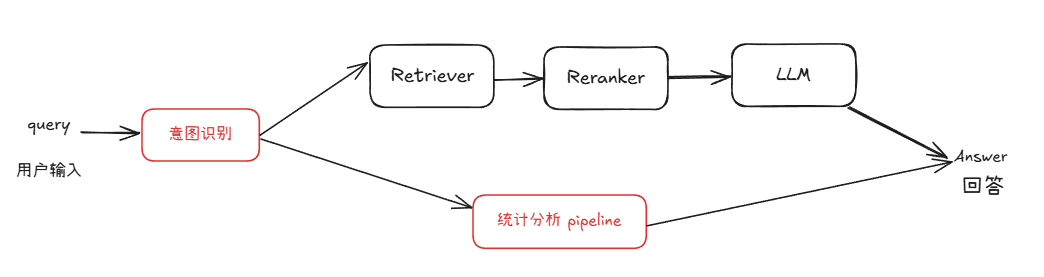
第一步:识别用户意图 —— 是知识问答?还是统计问题?
我们构建了一个 IntentClassifier 模块,自动判断用户问题属于:
- 传统 RAG 知识问答 🤖
- 结构化统计问答 📊
不同类型的问题,走不同的 pipeline👇
import lazyllm
from lazyllm.tools import IntentClassifier
classifier_llm = lazyllm.OnlineChatModule()
chatflow_intent_list = ["翻译服务", "天气查询", "内容推荐", "金融行情查询"]
classifier = IntentClassifier(classifier_llm, intent_list=chatflow_intent_list)
while True:
query = input("输入您的问题:\n")
print(f"\n识别到的意图是:\n {classifier(query)}\n" + "-"*40)
# 今天天气怎么样 ➔ 天气查询
# A股行情怎么样 ➔ 金融行情查询
# 给我推荐一部科幻电影 ➔ 内容推荐
# 帮我把这边论文译为中文 ➔ 翻译服务
第二步:数据准备 —— 下载论文 + 构建数据库
在这一阶段,我们要为 RAG 系统准备 “两套粮草”:
- 🗃️ 一份用于 RAG 检索的论文 PDF 文档;
- 🧮 一份用于 SQL 统计分析的结构化数据库。
🎓 小科普:SQL 数据库到底是个啥?
在深入使用 SQL 之前,我们先搞清楚几个基本概念:
🗝️数据库按照结构可分为两类:
-
关系型数据库(如 MySQL、PostgreSQL、SQLite):擅长处理结构化数据,数据以 “表格” 形式存储。
-
非关系型数据库:适合非结构化或半结构化数据,如:
📌文档型(MongoDB)
📌键值型(Redis)
📌向量型(FAISS、Milvus)
我们此次实战使用的是最常见的 SQLite —— 轻量级、零配置、超适合上手!
🗝️SQL(结构化查询语言)是操作这类数据库的 “指令语言”。比如下面一句话就能筛选出工资高于 5000 的员工:
SELECT name FROM employees WHERE salary > 5000;
🛠 动手实战:创建论文数据库(papers.db)
我们以 ArXivQA 为例,一次性搞定:
import sqlite3
import json
def write_into_table():
with open('test.txt', 'r')as f:
data = json.load(f)
data = data['data']
# 连接到 SQLite 数据库(如果数据库不存在,它会被创建)
conn = sqlite3.connect('papers.db')
cursor = conn.cursor()
# 创建表格
cursor.execute('''
CREATE TABLE IF NOT EXISTS papers (
id INTEGER PRIMARY KEY AUTOINCREMENT,
title TEXT,
author TEXT,
subject TEXT
)
''')
# 插入数据
for paper in data:
cursor.execute('''
INSERT INTO papers (title, author, subject)
VALUES (?, ?, ?)
''', (paper['title'], paper['author'], paper['subject']))
# 提交并关闭连接
conn.commit()
conn.close()
这样系统就既有 “文本知识”,也有 “结构化信息” 啦!
第三步:SQL Call —— 会写 SQL,还得能查!
要让 RAG 真的能处理结构化数据,光有数据库还不够,还得有 “翻译官” 能听懂自然语言,把 “人话” 转成 “数据库语言”—— 这正是 Text2SQL 的任务。
⚙️ 什么是 Text2SQL?
Text2SQL 是一种自然语言处理(NLP)技术,核心任务就是把用户用 “人话” 问的问题 ➡️ 自动转成能在数据库执行的 SQL 查询语句。
工作流程如下图所示:
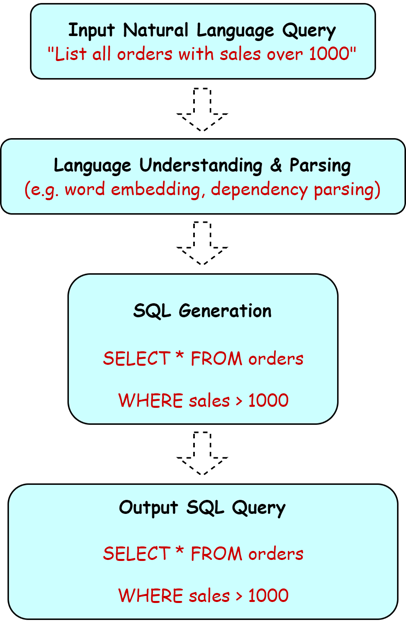
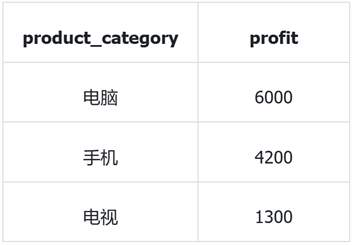
例如,针对 “请给我每个品类的盈利汇总,按盈利从高到低排序”,生成 SQL 如下:
SELECT product_category,
SUM(product_price * quantity) - SUM(cost_price * quantity) AS profit
FROM orders
GROUP BY product_category
ORDER BY profit DESC;
是不是瞬间高大上了?😉
🛠 动手实战:让大模型具备 Text2SQL 能力
构建一个 SqlManager 和 SqlCall,让大模型具备 Text2SQL 能力:
from lazyllm.tools import SqlManager, SqlCall
sql_manager = SqlManager("sqlite", None, None, None, None, db_name="papers.db", tables_info_dict=table_info)
sql_llm = lazyllm.OnlineChatModule()
sql_call = SqlCall(sql_llm, sql_manager,
use_llm_for_sql_result=False)
query = "库中一共多少篇文章"
print(sql_call(query))
>>> [{"total_papers": 200}]
while True:
query = input("请输入您的问题:")
print("answer:")
print(sql_call(query))
# 库中一共多少篇论文
# 库中最多的三个subject是什么
# 查询数据库并返回 subject 包含Computer Vision的论文题目的结果
✔️ 动态 SQL 生成
✔️ 执行数据库查询
✔️ 返回结构化结果
第四步:Function Call —— 数据分析 + 图表生成!
SQL Call 帮 RAG 跨入了结构化数据的门槛,但你有没有发现 ——
有些统计问题并不是 “查数据”,而是 “做计算”,甚至 “生成图表”!
比如👇:
- “过去 12 个月的平均营收是多少?”
- “哪类产品盈利最多,能不能画个图?”
这时候,传统 RAG + SQL 就不够用了,我们需要 Function Call!
什么是 Function Call?
Function Call 就是让大模型调用你定义好的 “外部函数”。比如你定义了一个绘图函数、一个均值计算函数,模型就可以:
👂 听懂你的问题
🧠 选出对应的函数
🧪 输入参数、执行逻辑
🗣️ 把结果自然语言描述或图表展示出来
它就像大模型身边的 “工具箱”,有问题直接 “调工具”。
常用的 Function Call 算法
|
Function Call |
ReAct (Reason + Act) |
PlanAndSolve |
ReWOO (ReAct with Working Memory) | |
|
工作流程 |
最大循环次数内循环: - 试参调用工具; - 观察工具输出,完成任务就结束循环。 |
最大循环次数内循环: - 思考; - 试参调用工具; - 观察工具输出,完成任务就结束循环。 |
最大循环次数内循环: - (重)计划并分解任务; - 调用工具解处理当前前子任务; - 观察工具输出,确定是否完成子任务,完成整个任务就结束循环 |
- 计划并分解任务; - 调用工具逐步解决所有子任务 - 综合所有步骤结果进行反馈 |
|
工作特点 |
简单直接,思考过程不可见 |
引入思考环节,思考可见 |
强调任务的分解和任务的动态调整 |
强调整体规划和综合反馈 |
📌 更多有关 Function Call 的内容与详细实战操作,请关注后续 RAG 教程。
Function Call 流程展示
示例问题:请问汤姆的同桌的姐姐的家乡明天的气温怎样?
Plan:大模型把问题分解成若干步骤
Q1:汤姆的同桌是谁?得到答案 A1
Q2:A1 的姐姐是谁?得到答案 A2
Q3:A2 的家乡是哪个城市?得到答案 A3
Q4:A3 明天的气温是多少?得到最终答案 A4
下面为 LazyLLM 中的简单示例流程代码。
def get_sister_name(name: str) -> str: ...
def get_hometown(name: str) -> str: ...
def get_deskmate(name: str) -> str: ...
def get_tomorrow_temperature(city: str) -> Optional[float]: ...
agent = PlanAndSolveAgent(llm=TrainableModule("internlm2-chat-7b").start(),
tools=[get_sister_name, get_hometown, get_deskmate,
get_tomorrow_temperature])
ret = agent("请问汤姆的同桌的姐姐的家乡明天的气温怎样?")
Solve:大模型从工具列表中选择合适的工具解答问题
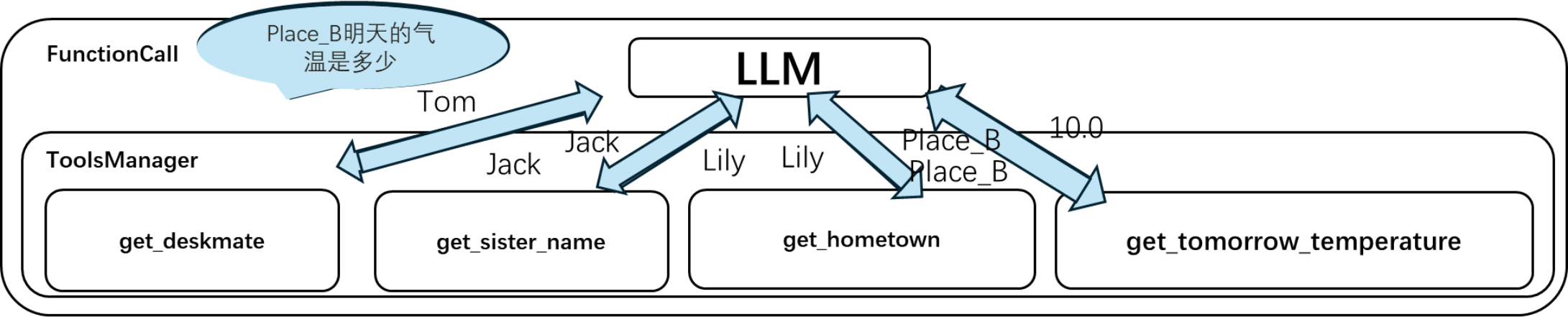
在得到问题后,大模型会把问题分成若干步骤,然后根据需要调用合适的工具。
常用可视化工具
|
工具包 |
核心能力 |
适用场景 |
优点 |
缺点 |
|
Matplotlib |
- 基础 2D/3D 绘图 - 高度自定义图表细节 - 支持多种图表类型(折线、柱状、散点、等高线等) |
- 科学计算 - 论文 / 出版物图表 - 底层绘图需求 |
- 高度灵活 - 兼容性强(几乎所有库都基于它) |
- API 较底层,代码冗长 - 默认样式较简陋 |
|
Seaborn |
- 统计可视化(分布、回归、分类等) - 高级封装(箱线图、热力图、小提琴图等) - 默认美观的样式 |
- 数据分布分析 - 统计建模可视化 - 快速生成美观图表 |
- 代码简洁 - 内置统计功能 - 默认样式优雅 |
- 依赖 Matplotlib - 自定义能力较弱 |
|
Plotly |
- 交互式可视化(缩放、悬停、点击等) - 支持动态 / 3D 图表 - 可导出为 HTML/Web 应用 |
- 交互式仪表盘 - Web 应用嵌入 - 动态数据展示 |
- 强大的交互性 - 支持复杂图表(如地理地图) - 与 Dash 集成 |
- 学习曲线较陡 - 不适合静态报告 |
|
Bokeh |
- 交互式可视化(适合大规模数据) - 支持流数据更新 - 可嵌入 Web 应用 |
- 实时数据监控 - 大规模数据集交互 - Web 应用开发 |
- 高性能(适合大数据) - 灵活的交互设计 |
- 文档较分散 - 默认样式一般 |
|
Pyecharts |
- 基于 ECharts 的交互式图表 - 支持动态 / 3D / 地理地图 - 可嵌入 Web/Jupyter |
- 中文环境友好 - 企业级仪表盘 - 复杂交互需求 |
- 图表类型丰富(如桑基图、日历图) - 配置灵活 - 中文文档完善 |
- 依赖 JavaScript 渲染 - 非纯 Python 生态 |
🛠 动手实战:统计分析 Agent
普通 SQL 搞不定的图表分析任务,Function Call 来搞定!
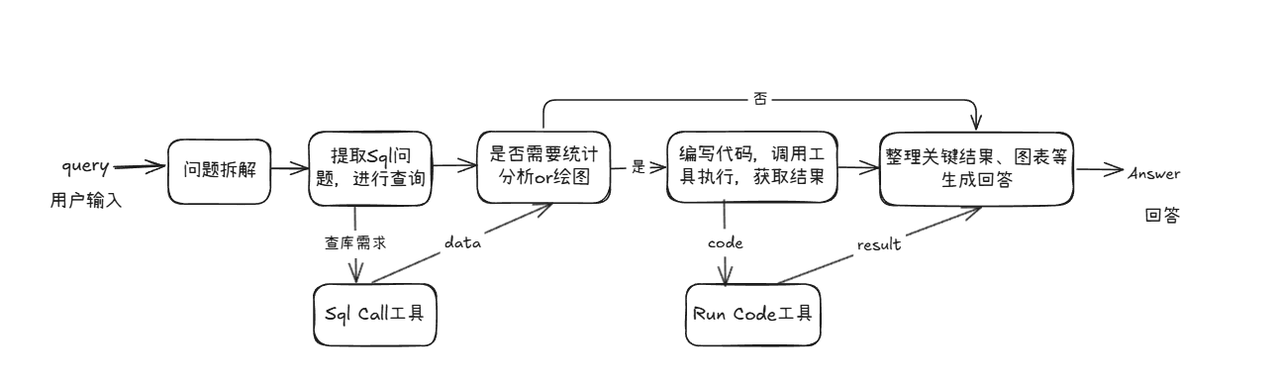
我们封装了两个工具函数:
run_sql_query:查询数据run_code:执行统计 / 绘图代码(支持 pandas、matplotlib 等)
@fc_register("tool")
def run_sql_query(query):
"""
Automatically generates and executes an SQL query based on a natural language request.
Given a natural language query describing a data retrieval task, this function generates the corresponding SQL
statement, executes it against the database, and returns the result.
Args:
query (str): A natural language description of the desired database query.
Returns:
list[dict]: A list of records returned from the SQL query, where each record is represented as a dictionary.
"""
sql_manager = SqlManager("sqlite", None, None, None, None, db_name="papers.db", tables_info_dict=table_info)
sql_llm = lazyllm.OnlineChatModule(source="sensenova")
sql_call = SqlCall(sql_llm, sql_manager, use_llm_for_sql_result=False)
return sql_call(query)
@fc_register("tool")
def run_code(code: str):
"""
Run the given code in a separate thread and return the result.
Args:
code (str): code to run.
Returns:
dict: {
"text": str,
"error": str or None,
}
"""
result = {
"text": "",
"error": None,
}
def code_thread():
nonlocal result
stdout = io.StringIO()
try:
with contextlib.redirect_stdout(stdout):
exec_globals = {}
exec(code, exec_globals)
except Exception:
result["error"] = traceback.format_exc()
result["text"] = stdout.getvalue()
thread = threading.Thread(target=code_thread)
thread.start()
thread.join(timeout=10)
if thread.is_alive():
result["error"] = "Execution timed out."
thread.join()
return result
搭配 ReactAgent,系统自动完成:
🔁 理解问题 → 数据查询 → Python 绘图 → 图像展示
from lazyllm.tools.agent import ReactAgent
agent = ReactAgent(
llm=lazyllm.OnlineChatModule(stream=False),
tools=['run_code', 'run_sql_query'],
return_trace=True,
max_retries=3,
)
一键整合两个流程:论文问答系统升级实录
我们将两个子工作流整合成一个 “超级论文问答系统”:
def build_paper_assistant():
llm = OnlineChatModule(source='qwen', stream=False)
intent_list = [
"论文问答",
"统计问答",
]
with pipeline() as ppl:
ppl.classifier = IntentClassifier(llm, intent_list=intent_list)
with lazyllm.switch(judge_on_full_input=False).bind(_0, ppl.input) as ppl.sw:
ppl.sw.case[intent_list[0], rag_ppl]
ppl.sw.case[intent_list[1], sql_ppl]
return ppl
只需输入一句自然语言,系统自动判断 + 自动处理!
图文并茂、数据可视、全自动分析 ✅
RAG 论文系统综合多模态方案
经过多讲实战拆解,我们已经从:
- ✍️ 基础 RAG 文档问答
- 🧠 意图识别模块拆分
- 📊 SQL Call 结构化检索
- 🧮 Function Call 动态分析
- 🖼️ 多模态图像理解
一路构建出了一个真正面向论文场景的 “通用型智能助手” 系统!
这不只是把模块 “拼上去”,而是真正形成了一个能问、能答、能查、能画图,还能跨图文内容理解的完整闭环系统!
👇 来看看系统架构总览图,你现在搭建的 RAG 已经不是 “小白问答机”,而是👇
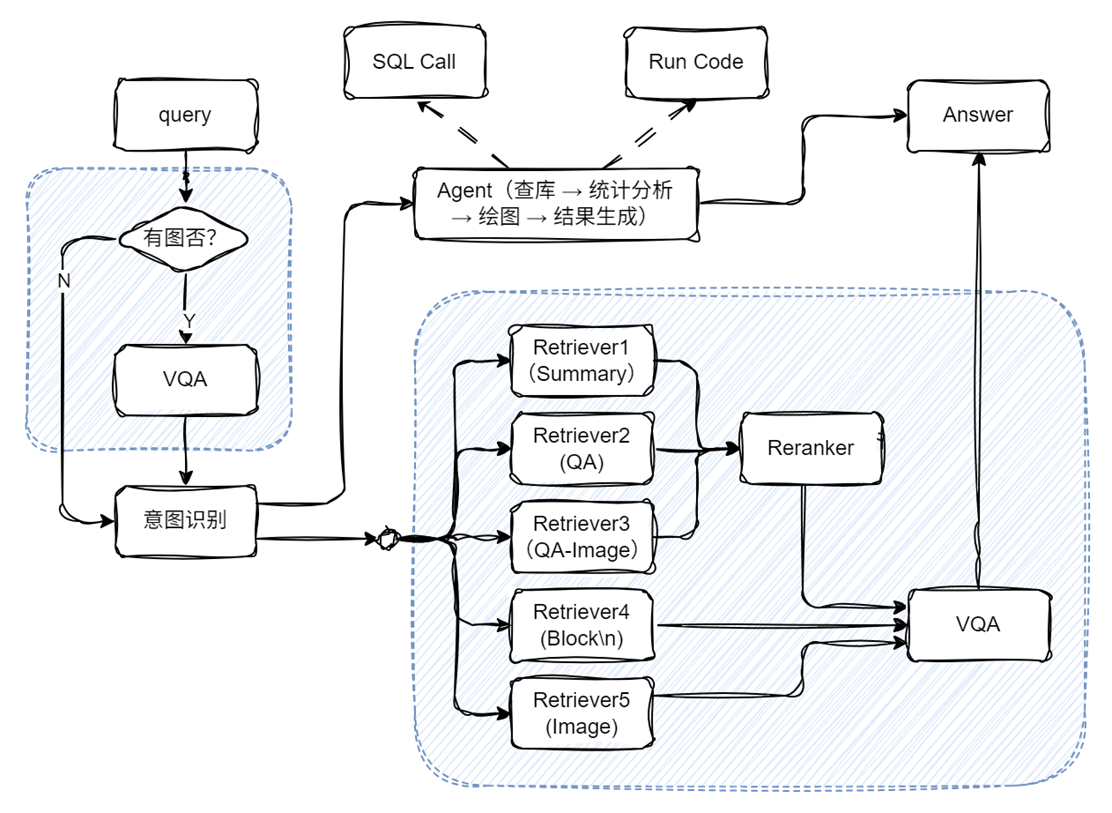
代码实现
# 构建 rag 工作流和统计分析工作流
rag_ppl = build_paper_rag()
sql_ppl = build_statistical_agent()
# 搭建具备知识问答和统计问答能力的主工作流
def build_paper_assistant():
llm = OnlineChatModule(source='qwen', stream=False)
vqa = lazyllm.OnlineChatModule(source="sensenova",\
model="SenseNova-V6-Turbo").prompt(lazyllm.ChatPrompter(gen_prompt))
with pipeline() as ppl:
ppl.ifvqa = lazyllm.ifs(
lambda x: x.startswith('<lazyllm-query>'),
lambda x: vqa(x), lambda x:x)
with IntentClassifier(llm) as ppl.ic:
ppl.ic.case["论文问答", rag_ppl]
ppl.ic.case["统计问答", sql_ppl]
return ppl
if __name__ == "__main__":
main_ppl = build_paper_assistant()
lazyllm.WebModule(main_ppl, port=23459, static_paths="./images", encode_files=True).start().wait()
一个总结:RAG,不止于问答!
从第 15 讲的理论铺垫,到第 16 讲的实战落地,我们一步步带你从传统 RAG 跃升至智能数据助手。RAG 系统不再是 “只会读文本” 的工具,而是一个:
✅ 会理解意图
✅ 能查结构化数据库
✅ 会写 SQL
✅ 能做统计分析、还能画图!
下次遇到数据分析类问题,不如试试你自己搭的 RAG 智能体吧~
通过这两讲的深入实战,我们不只是看懂了 RAG 如何 “接数据库、调代码、画图表”,更真正掌握了:一个能做宏观总结和统计分析的 RAG 系统,不只是能答题,更能思考,更能分析!
从意图识别让系统 “知你所问”,到 SQL Call 架起 RAG 与结构化数据之间的桥梁,再到 Function Call 让模型插上 “代码执行 + 图表生成” 的双翼,我们一步步,把 RAG 从文本问答助手,升级成了数据智能 + 图形交互的超级分析专家!
这不是简单的 “加功能”,而是一次认知和能力的全方位拓展!RAG 不再只是 “读文本”,它开始真正 “理解问题”、“提取数据”、“生成洞察”。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









