







需要源码和数据集请点赞关注收藏后评论区留言私信~~~
人们在面对大量未知事物时,往往会采取分而治之的策略,即先将事物按照相似性分成多个组,然后按组对事物进行处理。机器学习里的聚类就是用来完成对事物进行分组的任务
一、样本处理
聚类算法是对样本集按相似性进行分簇,因此,聚类算法能够运行的前提是要有样本集以及能对样本之间的相似性进行比较的方法。
样本的相似性差异也称为样本距离,相似性比较称为距离度量。
设样本特征维数为n,第i个样本表示为x_i={x_i^(1),x_i^(2),…,x_i^(n)}。因此,样本也可以看成n维空间中的点。当n=2时,样本可以看成是二维平面上的点。
二维平面上两点x_i和x_j之间的欧氏距离:
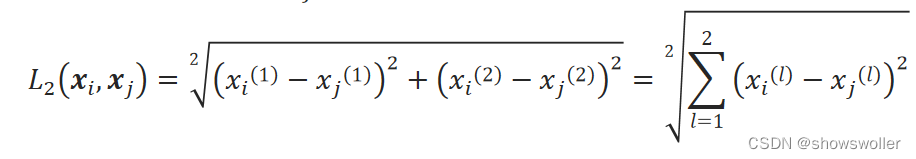
K均值聚类算法常采用欧氏距离作为样本距离度量准则。
二维平面上两点间欧氏距离的计算公式推广到n维空间中两点x_i和x_j的欧氏距离计算公式:
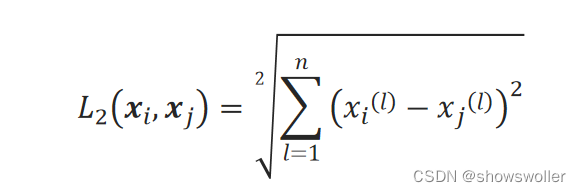
二、基本思想
设样本总数为m,样本集为S={x_1,x_2,…,x_m}。K均值聚类算法对样本集分簇的个数是事先指定的,即k。设分簇后的集合表示为C={
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











