






 XML是一种可扩展标记语言,用于存储和传输数据,常作为配置文件使用。与HTML不同,XML的标签是自定义的,并且有严格的语法规则,如必须正确关闭标签,区分大小写等。XML文档需要遵循一定的约束,如DTD或Schema,以确保其结构正确。解析XML有DOM、SAX、JDOM和DOM4J等多种方式,每种方式各有优缺点。在Java中,Jsoup库提供了方便的API来解析和操作XML文档。
XML是一种可扩展标记语言,用于存储和传输数据,常作为配置文件使用。与HTML不同,XML的标签是自定义的,并且有严格的语法规则,如必须正确关闭标签,区分大小写等。XML文档需要遵循一定的约束,如DTD或Schema,以确保其结构正确。解析XML有DOM、SAX、JDOM和DOM4J等多种方式,每种方式各有优缺点。在Java中,Jsoup库提供了方便的API来解析和操作XML文档。
XML概述
什么是xml?
可扩展的标记语言 Extensible Markup Language,
跟html相似(也是标记语言,不能扩展)
标记:<英文名字>
可扩展:标签都是自定义的。
xml 与 html的区别:
- html:
- 在网页中展示数据的。
- 标签是固定的,每一个标签都有单独的作用
- xml:
- 存储数据,持久化,配置文件。
- 可扩展的标签
XML作用
存储数据、持久化
配置文件(最常用的功能就是xml做为一个配置文件 )
数据传输(在网络传输数据,慢,安全)–> 被json替代(json本质就是一个字符串)
XML基础语法
- xml文档的后缀名
.xml - xml第一行必须为
文档声明文档声明前面有空格,空行都不行 - xml文档中有且仅有一个
根标签(一对标签包裹住全部的标签)(内部的标签的内容可以重复) - 属性值必须使用
引号(单双都可)引起来 - 标签必须正确关闭,不能交叉关闭
正确关闭: < stu> < /stu>
错误的写法:< stu> < p>< /stu>< /p> - xml标签名称
严格区分大小写 - 自闭合标签 只有属性没有标签体
- 标签体必须有开始标签结束标签
XML快速入门
需求:使用xml描述学生信息(姓名,年龄,性别),如果有多个学生信息又该如何描
述?
1.新建文件 student.xml
2.写文档声明 <?xml version="1.0" encoding="utf8"?>
3.写根标签 < students>
4.写标签–>写标签体 < name>zhangsan</ name>
5.用浏览器打开xml文件不报错,说明没有格式错误
6.用属性进行区分,但是需要用约束文档约一下,否则手写重复也是可以的
<?xml version="1.0" encoding="utf8"?>
<students>
<student id='1'>
<name>zhangsan</name>
<age>23</age>
<gender>male</gender>
<address />
</student>
<student id='2'>
<name>lisi</name>
<age>24</age>
<gender>female</gender>
<address />
</student>
</students>
XML组成部分
文档声明
- 举例 <?xml version="1.0" encoding="utf8"?>
- 格式
<?xml 属性列表 ?> - 属性列表
version:版本号,必须的属性【1.0】 (始终都是1.0)
encoding:编码方式。告知解析引擎当前文档使用的字符集,默认值:ISO-8859-1(一般不用此字符集,它不支持中文)。一般用utf8可以使用中文
standalone:是否独立(一般不要此属性)
取值:
yes:不依赖其他文件
no:依赖其他文件
指令
引入css文件,现在不需要了。现在存储数据,不展示数据
<?xml-stylesheet type="text/css" href="a.css" ?>
标签
- 标签命名规则
- 名称可以包含字母、数字以及其他的字符
- 名称不能以数字或者标点符号开始
- 名称不能以字母 xml(或者 XML、Xml 等等)开始
- 名称不能包含空格
- 最佳命名习惯
- 名称应当比较简短,比如:<book_title>,而不是:<the_title_of_the_book>。
- 避免 “-” 字符。如果您按照这样的方式进行命名:“first-name”,一些软件会认为你需要提取第一个单词。
- 避免 “.” 字符。如果您按照这样的方式进行命名:“first.name”,一些软件会认为 “name” 是对象 “first” 的属性。
- 避免 “:” 字符。冒号会被转换为命名空间来使用(稍后介绍)。
- XML 文档经常有一个对应的数据库,其中的字段会对应 XML 文档中的元素。有一个实用的经验,即使用数据库的名称规则来命名 XML 文档中的元素。
- 非英语的字母比如 éòá 也是合法的 XML 元素名,不过需要留意当软件开发商不支持这些字符时可能出现的问题。
属性
属性值必须被引号包围,不过单引号和双引号均可使用。比如一个人的性别,person 标签可以这样写:
<person sex="female">
或
<person sex='female'>
id属性
有时候会向元素分配 ID 引用。这些 ID 索引可用于标识 XML 元素
一般来说描述的意思是唯一的,但是现在还不能保证唯一,因为没有写约束
注意事项
id属性值唯一,(id字母也可以用其他的代替,但是还是要规定一下叫什么)
<messages>
<note id="501">
<to>George</to>
<from>John</from>
<heading>Reminder</heading>
<body>Don't forget the meeting!</body>
</note>
<note id="502">
<to>John</to>
<from>George</from>
<heading>Re: Reminder</heading>
<body>I will not</body>
</note>
</messages>
文本
就是标签体的内容
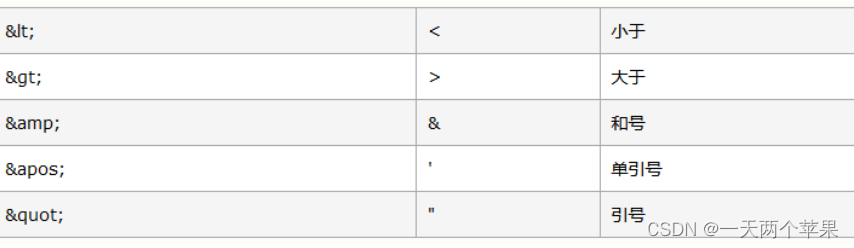
CDATA区(标签体):在该区域中的数据会被原样展示 (< > “” ‘’ 这些符号都需要转义)
< to> < ; 尖括号就转成的普通文本& gt;< /to>
如果特殊字符太多,需要用下面的方法,统统转成普通文本
语法
<![CDATA[把要写的数据写在此处]]>
< to> <![CDATA[ < > ]]> < /to>
XML约束
一个良好的 XML 文档要满足以下规则:
- XML 文档必须有根元素
- XML 文档必须有关闭标签
- XML 标签对大小写敏感
- XML 元素必须被正确的嵌套
- XML 属性必须加引号
什么是约束
规定xml文档的书写规则

约束的使用
定义xml标签约束,使开发者按照定义书写,也可以约束html文件
约束的分类
DTD约束
Schema约束
DTD约束
document type definition 文档类型定义
DTD约束编写
新建一个文件student.dtd,文件的扩展名是.dtd。本质还是一个XML文件
<!ELEMENT students (student*) > 规定根标签的名字是students,括号里规定有哪些子标签,*0次或多次;+至少有一个;?1次或者0次
<!ELEMENT student (name,age,sex)> 规定子标签可以只有哪些子元素,还得有顺序
<!ELEMENT name (#PCDATA)> PCDATA 文本
<!ELEMENT age (#PCDATA)>
<!ELEMENT sex (#PCDATA)>
<!ATTLIST student number ID #REQUIRED> student标签中的number是ID属性是唯一的
DTD约束引入,使用
- 格式
* 内部dtd:将约束规则定义在xml文档中
* 外部dtd:将约束的规则定义在外部的dtd文件中
* 本地:<!DOCTYPE 根标签名 SYSTEM "dtd文件的位置">
* 网络:<!DOCTYPE 根标签名 PUBLIC "dtd文件名字" "dtd文件的位置URL">
- 案例演示 引入外部的本地的约束
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE students SYSTEM "student.dtd">
<students>
<student number="D001">
<name>tom</name>
<age>18</age>
<sex>male</sex>
</student>
</students>
Schema约束
比dtd 更能更加强大。 提供了更加丰富的数据类型
XML Schema 可针对未来的需求进行扩展
XML Schema 更完善,功能更强大
XML Schema 基于 XML 编写 (schema本质上就是一个 xml文件)
XML Schema 支持数据类型 (提供的更加丰富的数据类型)
XML Schema 支持命名空间
Schema约束编写
student.xsd
扩展名是:xsd
<?xml version="1.0"?>
<xsd:schema xmlns="http://www.itfxp.com/xml" 命名空间相当于根元素
xmlns:xsd="http://www.w3.org/2001/XMLSchema" 固定写法,代表用这种文档的约束
targetNamespace="http://www.itfxp.com/xml" 命名空间(写公司的域名就可以了)代表唯一的
elementFormDefault="qualified">
<xsd:element name="students" type="studentsType"/> 根标签是students 类型是studentsType
<xsd:complexType name="studentsType"> 用的studentsType类型
<xsd:sequence> 顺序
<xsd:element name="student" type="studentType" minOccurs="0" maxOccurs="unbounded"/>
子标签student
</xsd:sequence>
</xsd:complexType>
<xsd:complexType name="studentType"> 用的studentsType类型
<xsd:sequence> 顺序
<xsd:element name="name" type="xsd:string"/> name是string类型
<xsd:element name="age" type="ageType" /> age的类型是自定义类型ageType
<xsd:element name="sex" type="sexType" /> sex的类型是自定义类型sexType
</xsd:sequence>
student的属性叫number,它的类型是numberType,唯一required
<xsd:attribute name="number" type="numberType" use="required"/>
</xsd:complexType>
<xsd:simpleType name="sexType"> 只能写male和female两种名称的string类型
<xsd:restriction base="xsd:string">
<xsd:enumeration value="male"/>
<xsd:enumeration value="female"/>
</xsd:restriction>
</xsd:simpleType>
<xsd:simpleType name="ageType">
<xsd:restriction base="xsd:integer"> 年龄是integer类型0~130
<xsd:minInclusive value="0"/>
<xsd:maxInclusive value="130"/>
</xsd:restriction>
</xsd:simpleType>
<xsd:simpleType name="numberType">
<xsd:restriction base="xsd:string"> 属性的值:itfxp_4位数字
<xsd:pattern value="itfxp_\d{4}"/>
</xsd:restriction>
</xsd:simpleType>
</xsd:schema>
Schema约束引入,使用
1.填写xml文档的根元素
2.引入xsi前缀. xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
3.引入xsd文件命名空间. xsi:schemaLocation="http://www.itfxp.com/xml student.xsd"
4.为每一个xsd约束声明一个前缀(防止引入的多个约束中有相同的标签),作为标识
xmlns:context="http://www.XXX/context" <context:name></context:name>
student.xml
<?xml version="1.0" encoding="UTF-8" ?>
<students
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" 1.固定写法
xmlns="http://www.itfxp.com/xml" 2.跟约束命名空间对应
xsi:schemaLocation="http://www.itfxp.com/xml student.xsd"> 约束文件名称
<student number="itfxp_0001">
<name>tom</name>
<age>18</age>
<sex>male</sex>
</student>
</students>
真实的配置文件
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:context="http://www.springframework.org/schema/context"
xmlns:mvc="http://www.springframework.org/schema/mvc"
xsi:schemaLocation="
http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/context
http://www.springframework.org/schema/context/spring-context.xsd
http://www.springframework.org/schema/mvc
http://www.springframework.org/schema/mvc/spring-mvc.xsd">
<context:annotation-config />
<context:component-scan base-package="cn.cisol.mvcdemo">
<context:include-filter type="annotation"
expression="org.springframework.stereotype.Controller" />
</context:component-scan>
<mvc:annotation-driven />
<mvc:resources mapping="/resources/**" location="/resources/" />
<bean
class="org.springframework.web.servlet.view.ContentNegotiatingViewResolver">
<property name="order" value="1" />
<property name="mediaTypes">
<map>
<entry key="json" value="application/json" />
<entry key="xml" value="application/xml" />
<entry key="htm" value="text/html" />
</map>
</property>
<property name="defaultViews">
<list>
<bean
class="org.springframework.web.servlet.view.json.MappingJackson2JsonView">
</bean>
</list>
</property>
<property name="ignoreAcceptHeader" value="true" />
</bean>
<bean
class="org.springframework.web.servlet.view.InternalResourceViewResolver">
<property name="viewClass"
value="org.springframework.web.servlet.view.JstlView" />
<property name="prefix" value="/WEB-INF/jsps/" />
<property name="suffix" value=".jsp" />
</bean>
<bean id="multipartResolver"
class="org.springframework.web.multipart.commons.CommonsMultipartResolver">
<property name="maxUploadSize" value="209715200" />
<property name="defaultEncoding" value="UTF-8" />
<property name="resolveLazily" value="true" />
</bean>
</beans>
XML解析
操作xml文档,将文档中的数据读取到内存中
操作XML两种情况
解析(读取):将文档中的数据读取到内存中 【实际开发中,框架提供者进行xml文件解析】
写入:将内存中的数据保存到xml文档中。持久化的存储, 使用代码的形式,在xml中写数据,根本就不做
常见解析XML方式
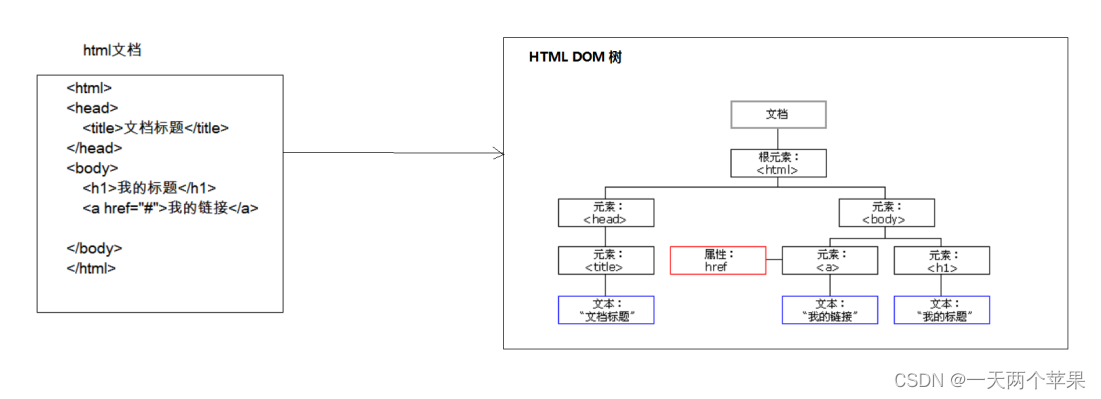
DOM
DOM(Document Object Model). 是用与平台和语言无关的方式表示XML文档的官方W3C标准,将标记语言文档一次性加载进内存,在内存中形成一颗dom树
SAX
SAX处理的优点类似于流媒体的优点。分析能够立即开始,而不是等待所有的数据被处理。逐行读取,基于事件驱动的
什么是事件驱动:一种基于回调机制的程序运行方法。由外至内一层一层解析。
-
优点
①不需要等待所有数据都被处理,分析就能立即开始。
②只在读取数据时检查数据,不需要保存在内存中。
③可以在某个条件得到满足时停止解析,不必解析整个文档。
④效率和性能较高,能解析大于系统内存的文档。 -
缺点
只能读取,不能增删改
很难同时访问同一文档的不同部分数据,不支持XPath
JDOM
JDOM(Java-based Document Object Model)的目的是成为Java特定文档模型,它简化与XML的交互并且比使用DOM实现更快
DOM4J
dom4j是一个Java的XML API,类似于jdom,用来读写XML文件的。性能优异功能强大简单易用开放源代码。
常见的XML解析器
-
JAXP:sun公司提供的解析器,支持dom和sax两种思想 -
DOM4J:一款优秀的解析器(常用) -
Jsoup:jsoup 是一款Java 的HTML解析器,可直接解析某个URL地址、HTML文本内容。它提供了一套省力的API,可通过DOM,CSS以及类似于jQuery的操作方法来取出和操作数据。 -
PULL:Android操作系统内置的解析器,sax方式的。
Jsoup
Jsoup概述 什么是Jsoup?
jsoup 是一款Java 的HTML解析器,可直接解析某个URL地址、HTML文本内容。它提供了一套非常省力的API,可通过DOM,CSS以及类似于jQuery的操作方法来取出和操作数据。
Jsoup快速入门
- 实现步骤
- 导入jar包

- 获取Document对象
- 获取对应的标签Element对象
- 获取数据
- 文档student.xml
用流读放到与src同级(src下流读不到因为他是受保护的,src下的全部编译成class文件),放到src下用类加载器读
<?xml version="1.0" encoding="UTF-8" ?>
<students>
<student number="itfxp_0001">
<name>
<xing>张</xing>
<ming>三</ming>
</name>
<age>18</age>
<sex>male</sex>
</student>
<student number="itfxp_0002">
<name>jack</name>
<age>18</age>
<sex>female</sex>
</student>
</students>
- 代码实现
//一、文件放到src同级
//将xml路径封装为File对象
File file = new File("模块名\\student.xml");
//获取Document对象
Document document = Jsoup.parse(file, "utf-8");
Elements elements = document.getElementsByTag("student");
for (Element element : elements) {
System.out.println(element.text());
}
//二、文件放到src内
//1获取student.xml的path
String path = JsoupDemo.class.getClassLoader().getResource("student.xml").getPath();
//2解析xml文档,加载文档进内存,获取dom树--->Document
Document document = Jsoup.parse(new File(path), "utf-8");
//3根据标签获取元素对象 Element
Elements elements = document.getElementsByTag("name");
System.out.println(elements.size());
//3.1获取第一个name的Element对象
Element element = elements.get(0);
//3.2获取数据
String name = element.text();
Jsoup常见对象
Document
Jsoup:工具类,可以解析html或xml文档,返回Document
| 方法名 | 说明 |
|---|---|
| parse(File in, String charsetName) | 解析xml或html文件的 |
| parse(String html) | 解析xml或html字符串 |
| parse(URL url, int timeoutMillis) | 通过网络路径获取指定的html或xml的文档对象 |
| getElementById(String id) | 根据id属性值获取唯一的element对象 |
| More ActionsgetElementsByTag(String tagName) | 根据标签名称获取元素对象集合 |
| getElementsByAttribute(String key) | 根据属性名称获取元素对象集合 |
| getElementsByAttributeValue(String key, String value) | 根据对应的属性名和属性值获取元素对象集合 |
/**
* Jsoup对象功能
*/
public class JsoupDemo2 {
public static void main(String[] args) throws IOException {
//2.1获取student.xml的path
File file = new File("day17_javaOOP_xml\\student.xml");
//2.2解析xml文档,加载文档进内存,获取dom树--->Document
/* Document document = Jsoup.parse(file, "utf-8");
System.out.println(document);*/
//2.parse(String html):解析xml或html字符串
/* String str = "<?xml version=\"1.0\" encoding=\"UTF-8\" ?>\n" +
"\n" +
"<students>\n" +
"\t<student number=\"itfxp_0001\">\n" +
"\t\t<name>tom</name>\n" +
"\t\t<age>18</age>\n" +
"\t\t<sex>male</sex>\n" +
"\t</student>\n" +
"\t<student number=\"itfxp_0002\">\n" +
"\t\t<name>jack</name>\n" +
"\t\t<age>18</age>\n" +
"\t\t<sex>female</sex>\n" +
"\t</student>\n" +
"\n" +
"</students>";
Document document = Jsoup.parse(str);
System.out.println(document);*/
//3.parse(URL url, int timeoutMillis):通过网络路径获取指定的html或xml的文档对象
URL url = new URL("https://baike.baidu.com/item/jsoup/9012509?fr=aladdin");//代表网络中的一个资源路径
Document document = Jsoup.parse(url, 10000);
System.out.println(document);
}
}
Elements
Element元素对象的集合。可以当做 ArrayList< Element>来使用
/**
* Document/Element对象功能
*/
public class JsoupDemo3 {
public static void main(String[] args) throws IOException {
//1.获取student.xml的path
String path = JsoupDemo3.class.getClassLoader().getResource("student.xml").getPath();
//2.获取Document对象
Document document = Jsoup.parse(new File(path), "utf-8");
//3.获取元素对象了。
//3.1获取所有student对象
Elements elements = document.getElementsByTag("student");
System.out.println(elements);
System.out.println("-----------");
//3.2 获取属性名为id的元素对象们
Elements elements1 = document.getElementsByAttribute("id");
System.out.println(elements1);
System.out.println("-----------");
//3.2获取 number属性值为heima_0001的元素对象
Elements elements2 = document.getElementsByAttributeValue("number", "itfxp_0001");
System.out.println(elements2);
System.out.println("-----------");
//3.3获取id属性值的元素对象
Element itfxp = document.getElementById("itfxp");
System.out.println(itcast);
}
}
Element
- 获取子元素对象
| 方法名 | 说明 |
|---|---|
| getElementById(String id) | 根据id属性值获取唯一的element对象 |
| getElementsByTag(String tagName) | 根据标签名称获取元素对象集合 |
| getElementsByAttribute(String key) | 根据属性名称获取元素对象集合 |
| getElementsByAttributeValue(String key, String value) | 根据对应的属性名和属性值获取元素对象集合 |
- 获取属性值
| 方法名 | 说明 |
|---|---|
| String attr(String key) | 根据属性名称获取属性值 |
- 获取文本内容
| 方法名 | 说明 |
|---|---|
| String text() | 获取文本内容 -->文本内容 |
| String html() | 获取标签体的所有内容(包括字标签的字符串内容) --> < font>文本内容< /font> |
/**
*Element对象功能
*/
public class JsoupDemo4 {
public static void main(String[] args) throws IOException {
//1.获取student.xml的path
String path = JsoupDemo4.class.getClassLoader().getResource("student.xml").getPath();
//2.获取Document对象
Document document = Jsoup.parse(new File(path), "utf-8");
/*
Element:元素对象
1. 获取子元素对象
* getElementById(String id):根据id属性值获取唯一的element对象
* getElementsByTag(String tagName):根据标签名称获取元素对象集合
* getElementsByAttribute(String key):根据属性名称获取元素对象集合
* getElementsByAttributeValue(String key, String value):根据对应的属性名和属性值获取元素对象集合
2. 获取属性值
* String attr(String key):根据属性名称获取属性值
3. 获取文本内容
* String text():获取所有字标签的纯文本内容
* String html():获取标签体的所有内容(包括子标签的标签和文本内容)
*/
//通过Document对象获取name标签,获取所有的name标签,可以获取到两个
Elements elements = document.getElementsByTag("name");
System.out.println(elements.size());
System.out.println("----------------");
//通过Element对象获取子标签对象
Element element_student = document.getElementsByTag("student").get(0);
Elements ele_name = element_student.getElementsByTag("name");
System.out.println(ele_name.size());
//获取student对象的属性值
String number = element_student.attr("NUMBER");
System.out.println(number);
System.out.println("------------");
//获取文本内容
String text = ele_name.text();
String html = ele_name.html();
System.out.println(text);
System.out.println(html);
}
}
Node
是Document和Element的父类


















 974
974

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









