




 本文深入探讨了线性回归与线性分类的区别,重点介绍了线性回归的原理和最小二乘法求解过程。线性回归通过最小化误差来确定最佳权重,而线性分类则涉及NP-hard问题。尽管两者输出空间不同,但线性回归的误差衡量方法在某些情况下也可应用于线性分类。此外,文章还讨论了线性回归的泛化能力和几何意义。
本文深入探讨了线性回归与线性分类的区别,重点介绍了线性回归的原理和最小二乘法求解过程。线性回归通过最小化误差来确定最佳权重,而线性分类则涉及NP-hard问题。尽管两者输出空间不同,但线性回归的误差衡量方法在某些情况下也可应用于线性分类。此外,文章还讨论了线性回归的泛化能力和几何意义。
线性回归
之前介绍的信用卡发放列子,我们从数据集出发进行训练,最后得出的结论是:给或者不给,输出空间为{+1,-1}。但是,我们想要从这些数据出发,最后让机器告诉我们给他们多大的额度是最合适的,输出空间为R+R^+R+。这就是不同于之前提到的Linear Classification的Linear Regression线性回归问题。二者的对比我们可以从下图中进行区分:

还是以信用卡为列,输入空间和之前的相同,如年龄、性别、月收入等等。也即X=[x0,x1,x2.......xd]X=[x_0,x_1,x_2.......x_d]X=[x0,x1,x2.......xd]特征空间为d+1d+1d+1维,其中第一个维度是维常数项,因为输出空间的变化,导致假设函数和二元分类略有不同,但基本思想相差不大。仍然需要考虑每个分量的不同加权,然后求和。最终得出结果。唯一不同的是最终结果不需要sign()sign()sign()函数的作用。

所谓的线性回归本质上就是:根据训练样本的数据,画出一条线。类似于已知函数的点,求出函数的解析式。然后根据这个解析式,可以求出任意点的对应的函数值。线性回归的任务就是找到这个函数的解析式,然后在预测某一个点对应值,可能会有少许的误差。如下图所示:
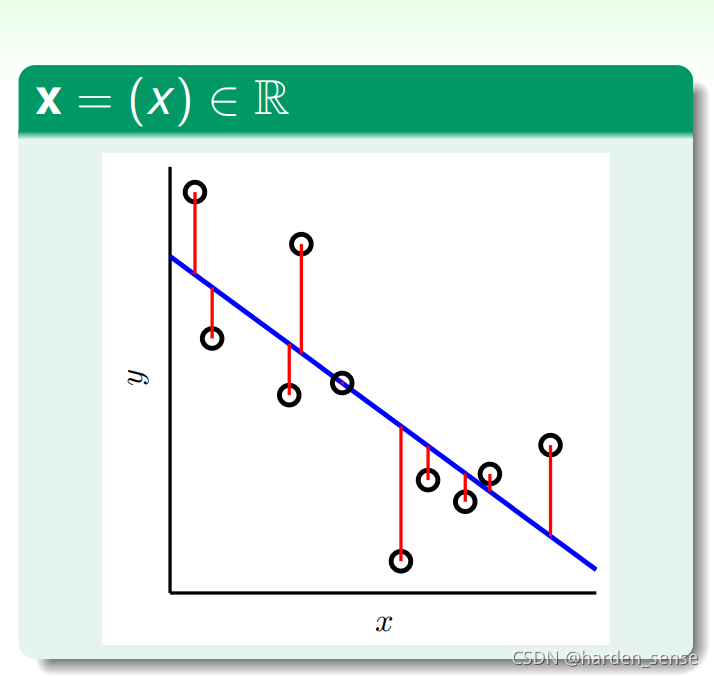
蓝色的线为我们根据训练集画出的预测函数,圈圈是真实的数据点,二者可能会存在一定的偏差。线性回归的演算法要做的事情是:让误差最小。最常用的误差衡量方式是基于最小二乘法的思想,其目标是计算最小误差,和对应权重www。误差的计算形式为最小均方误差:

在这个问题中假设函数hhh对应于权重和特征的乘积,如上图(9-5)所示可以将hhh进行变形。这里使用的数据集是含有误差的,因此(X,y)(X,y)(X,y)服从联合概率分布。
1.最小化误差
有了Ein(w)E_{in}(w)Ein(w)的计算方式,现在要考虑的问题就是将误差最小化,在误差最小化之前先对误差的衡量公式进行一个变形,用矩阵的形式来表示:

(X,y)都是已知数据,所以目标就转化为,寻找www使误差最小,在此之前我们先考虑一维的情况。很明显图像为一个开口向上的抛物线
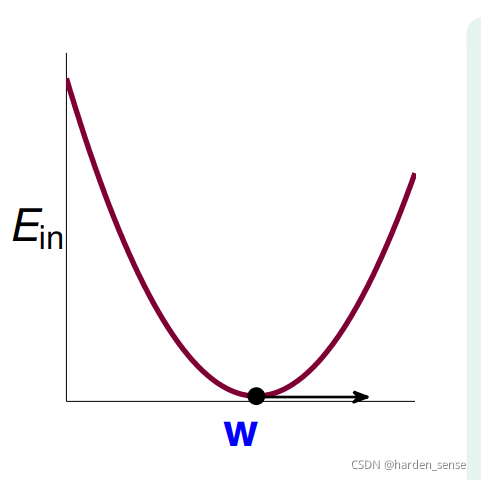
显然该函数在一维的情况下是一个凸函数,可微,连续。该函数存在最小值,最小值点在导数为0时取得。在X是多维的时候仍然满足凸函数的条件,由此我们可以得到:

接下来需要寻找一个WWW让误差的微分为0,在此之前先对上面推导出来的公式进行简单变形得到如下形式:
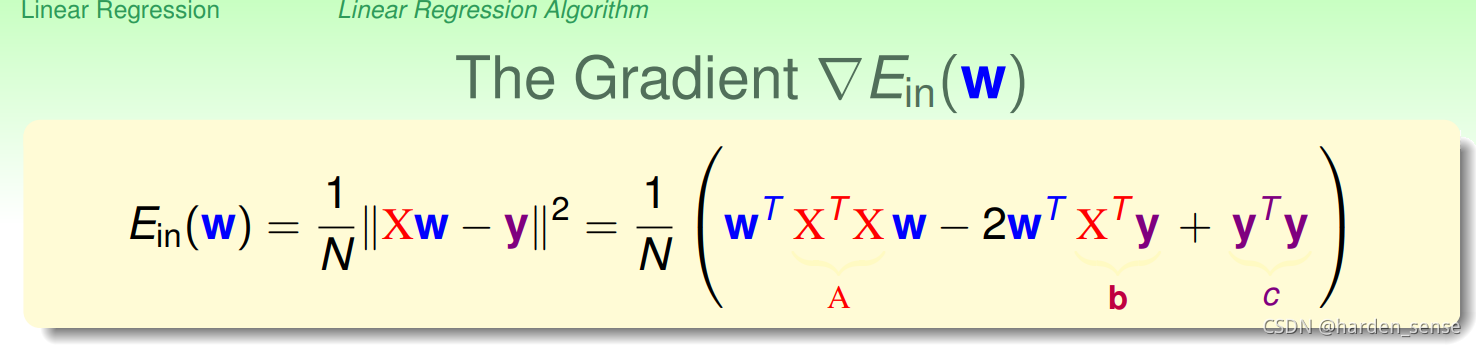
然后对该式子进行求导:

具体利用的为矩阵求导的内容,关于矩阵求导,可以参考知乎的文章https://zhuanlan.zhihu.com/p/273729929。然后将一些值代入:
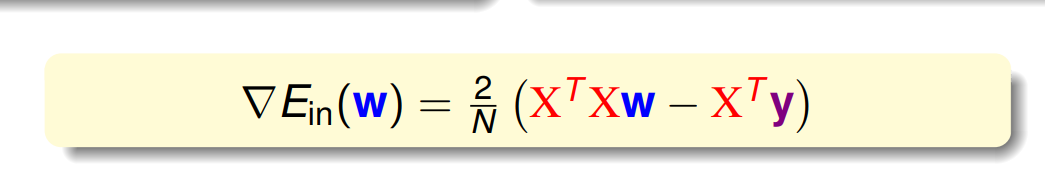 令上式为0可以得出如下结论:
令上式为0可以得出如下结论:
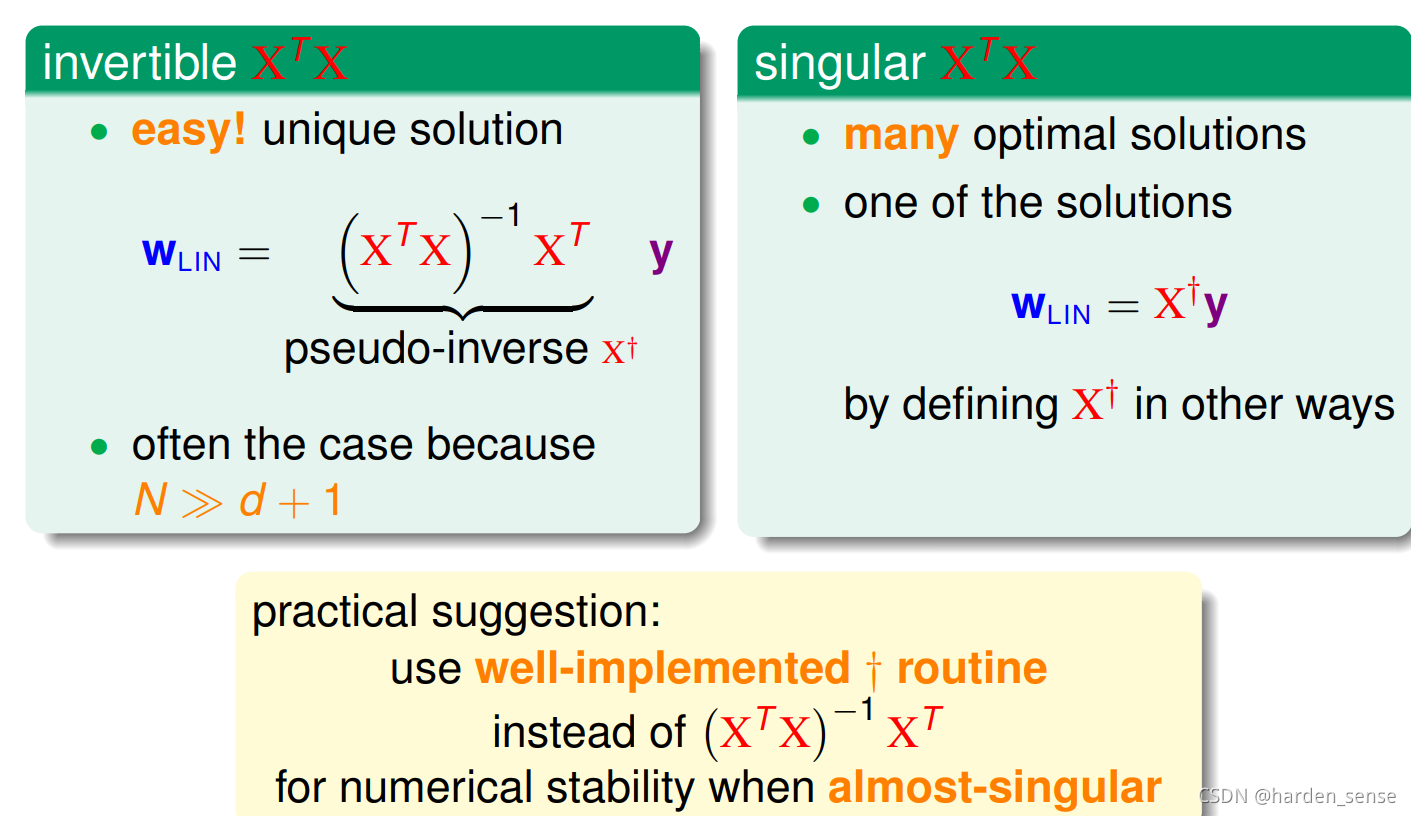
用X+X^+X+来代替(XTX)−1XT(X^TX)^{-1}X^T(XTX)−1XT可以简化为右图所示的形式。其中X+X^+X+表示矩阵的XXX的违逆。矩阵X只有当N=d+1N=d+1N=d+1才是方阵,伪逆矩阵和逆矩阵有很多相似之处。XTXX^TXXTX在大部分情况下是可逆的,原因是在机器学习中,样本数量远远大于特征向量的维数。因此在XTXX^TXXTX存在足够的自由度满足可逆的条件。如果该矩阵不可逆,说明最佳的WWW有很多个,只需要找到一个满足条件的即可。
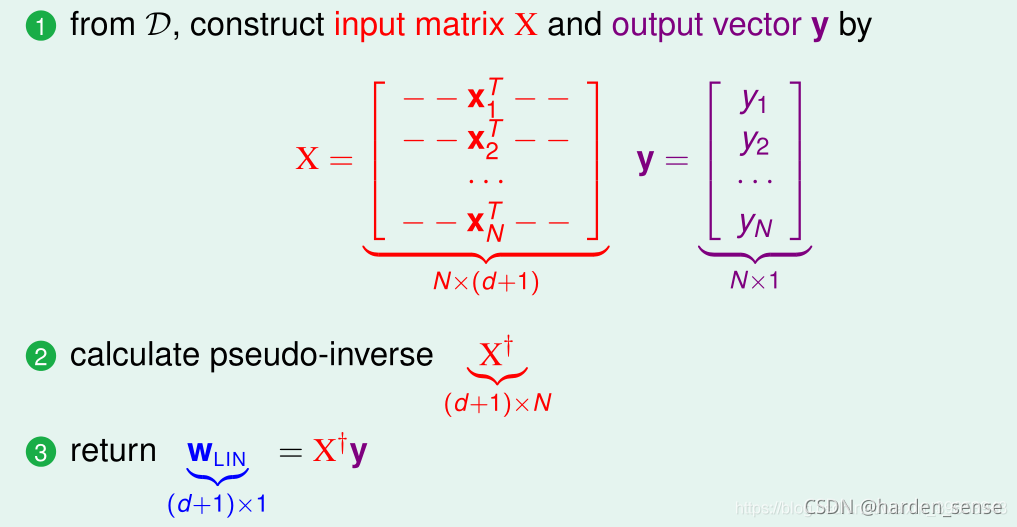
线性回归的算法求解如下:
- 首先通过已知的数据集XXX,构建输入矩阵XXX与输出向量y的标签:
- 然后构造输入矩阵和输出向量,求解伪逆
- 最后通过伪逆求出假设函数
2.泛化问题
上面的方法是否为机器学习?或者说该方法是否具有很好的泛化能力。

回答不是的理由:求解只需要一步就完成,不想像前面的算法,都是经过了很多步的。用该方法好像就是,我们只要有数据集自己完全可以根据公式进行计算,得出最佳的假设函数。好像机器学习并没有什么用处。
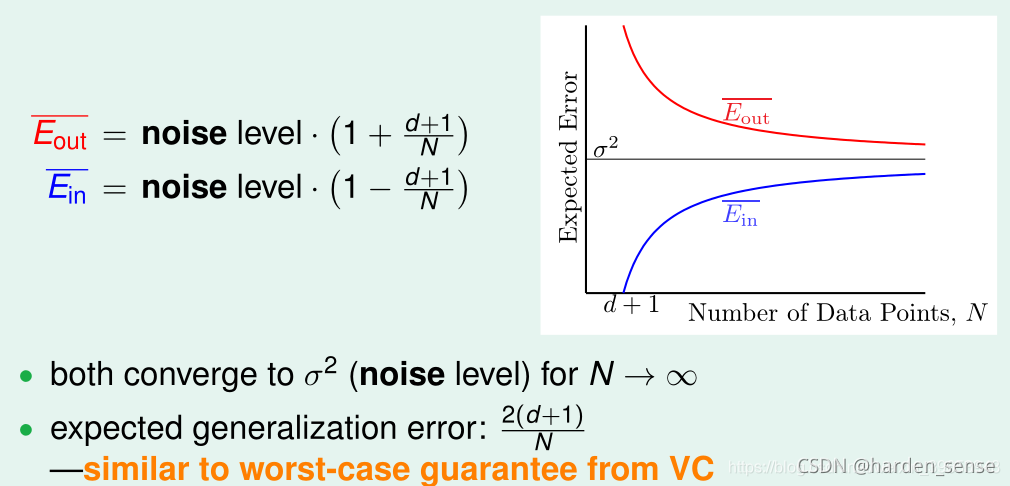
回答是的理由:更看重结果,这种直接求解方式是数学推导中的精确解,因此求出的W一定是让误差最小的解,而且求解伪逆的方法也是需要经过不同的迭代才能完成,并非我们看到的那样直接得出结果。而怕判断机器学习最主要的标准是学习到的EoutE_{out}Eout是否足够好。
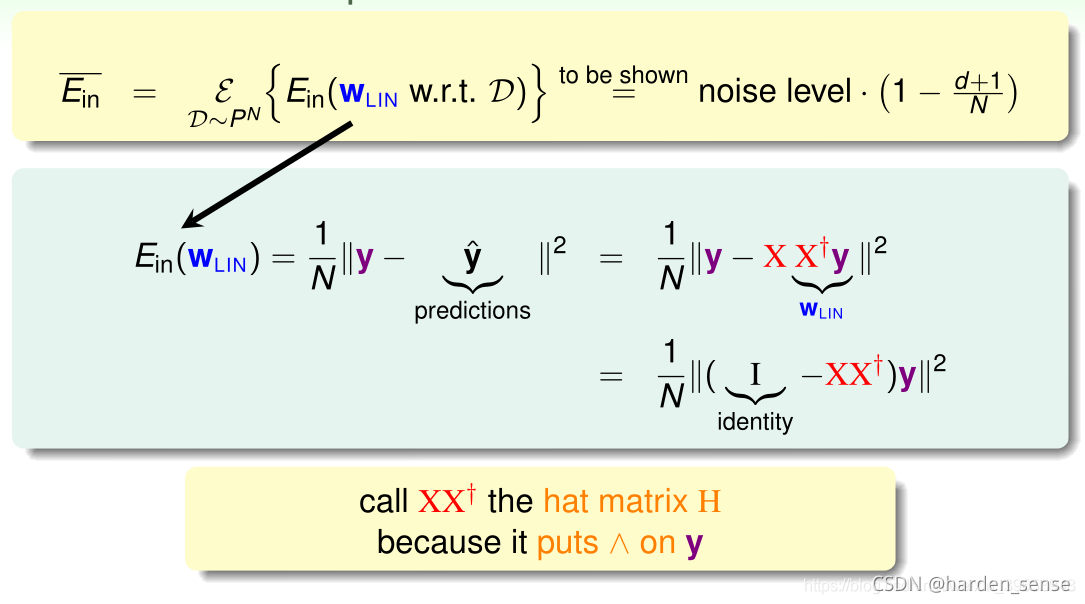
通过改进VC-bound,也可以证明在线性回归问题中VC起到了很好的约束作用,即找到了好的Ein(w)E_{in}(w)Ein(w)就可以保证Eout(w)E_{out}(w)Eout(w)足够的好。下面通过一种更简单的方法,证明线性回归问题是可以通过线下最小二乘法方法计算得到好的Ein(w)E_{in}(w)Ein(w)和Eout(w)E_{out}(w)Eout(w)。

通过几何图形更具体的了解HHH矩阵的物理含义:
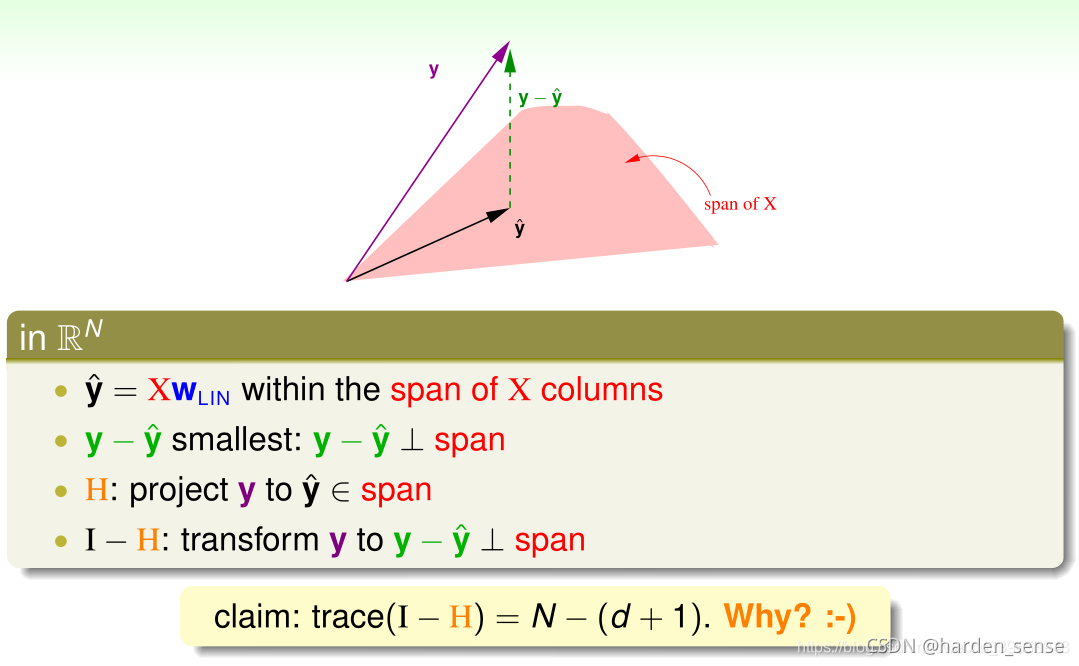


可以这样理解:如果不存在噪声,我们得到的是y向粉色空间的投影,该投影就是预测值,有了噪声的存在我们得到的预测值就是f(x)f(x)f(x)粉色空间里面的那条红线。


3.线性回归的误差衡量用到线性分类
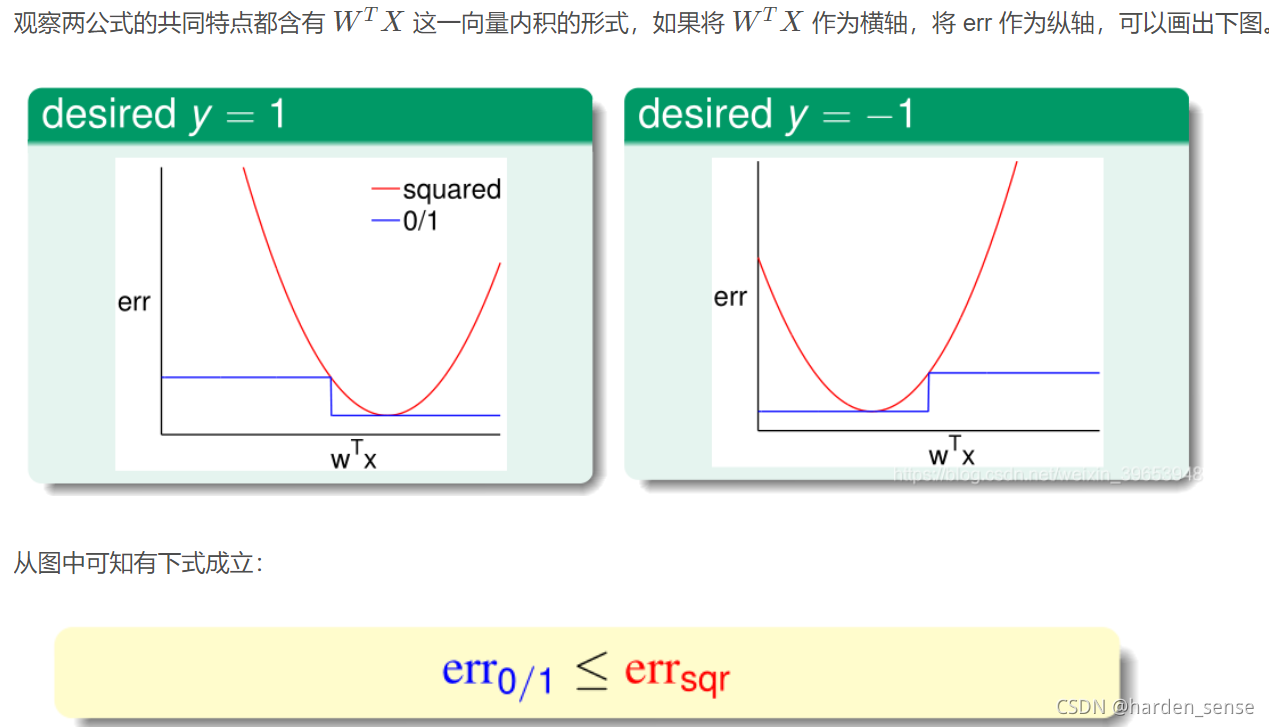
线性分类问题使用误差衡量方法是0/1 error,那么线性回归的平法误差能否应用到线性分类问题呢?
首先对比二元线性分类与线性回归之间的差异,分别在三个部分进行对比,输出空间、假设函数和错误衡量函数,如图所示。
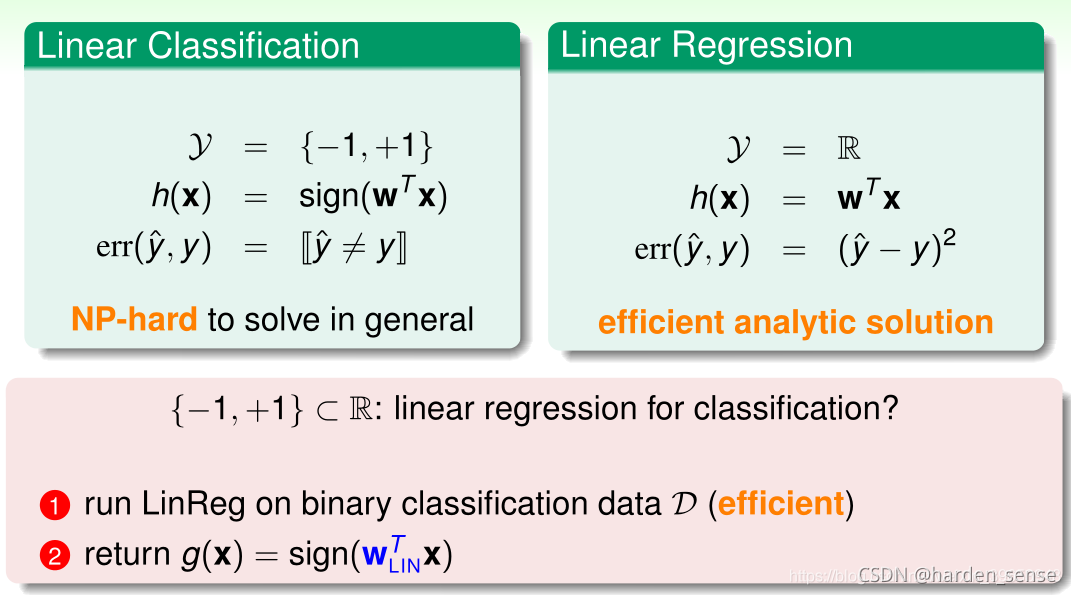
从求解问题的难度考虑,二元分类的求解是一个NP-hard问题,只能使用近似求解的方式,而线性回归通过求解析解,求解方便,程序编写也简单。
因此考虑能否通过求解线性回归的方式求二元分类问题,因为二元分类的输出空间 −1,+1{ − 1 , + 1 }−1,+1 属于线性回归的输出空间,即−1,+1∈R{ − 1 , + 1 } ∈ R−1,+1∈R ,其中数据集的标记大于零的表示+1,小于零的表示-1,通过线性回归求得的解析解 WLINW_{ L I N}WLIN,直接得出最优假设 g(X)=sign(WLINX)g ( X ) = s i g n ( W_{ L I N }X)g(X)=sign(WLINX)但是这种推理只符合直觉,而如何使用数学知识去说明这种方式的合理性呢?
参考:
https://www.cnblogs.com/ymingjingr/p/4306666.html
https://github.com/RedstoneWill/HsuanTienLin_MachineLearning
https://blog.youkuaiyun.com/weixin_39653948/article/details/105547804

















 2998
2998

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









