




1.没有免费午餐定理
机器学习的基本思路是:我们从已知的数据集D出发,经过训练,让机器得到一个好的函数g,利用函数g我们可以对未知的数据进行预测。但是,这种方法真的行的通吗?我们来看一个列子:
如下图所示,有三个标签为+1的九宫格,和三个标签为-1的九宫格,根据这6个样本,我们需要判断出g(x)g(x)g(x)的取值是+1还是-1。我们可以认为g(x)g (x)g(x)=+1。因为根据之前的样本,凡是等于+1的样本都是对称的,所以g(x)g(x)g(x)=1,这样来分析好像很有道理。
但是,也有人说g(x)g(x)g(x)=-1,理由是:凡是等于-1的样本,左上角第一个小正方形为黑色,很明显g(x)g(x)g(x)满足这个要求。
除了以上两种分法,我们还可以根据其他不同的分法,得到不同的分类方式。并且都是正确的。因为对于所给的这六个样本点来说,我们的分类方式都是有效果的。

上述列子告诉我们,我们的g可能在训练集D上有很好的表现,但是在D之外的数据集上的表现,可能就没有那么优秀了。机器学习中称这种现象为没有免费午餐定理(NO Free Lunch)。NFL定理表明在任何领域,没有一个学习算法,可以完美的完成任务 但是,有的时候我们会说,一个算法得到的结果比另一个算法更好。这是针对特定的问题,特定的数据集,特定的场景。NLF算法表明:无法保证在D之外的数据上做出更好的分类或者说是预测。既然机器学习无法在新的数据集上有更好的表现,那么我们干嘛还要费劲心力的进行机器学习的研究。这是接下来进行分析的重点。
2.可能性估计
根据没有免费午餐定理,我们知道:没有任何一个算法可以在D之外的数据上做到正确的分类或者预测。那么是否有一些方法,让目标函数在D之外的数据上尽可能的做到完美。看一个简单的列子:
有一个罐子,罐子里面装有橙色和绿色两种颜色的小球。能否推断出橙色球所占据的比uuu?在统计学上会这样处理这个问题:随便从罐子里面抓一把球出来作为sample,看一下在sample里面,橙色球占据的比列vvv,用vvv来近似的代替uuu。特别的当sample越随机,越大的时候vvv会更加的接近uuu。
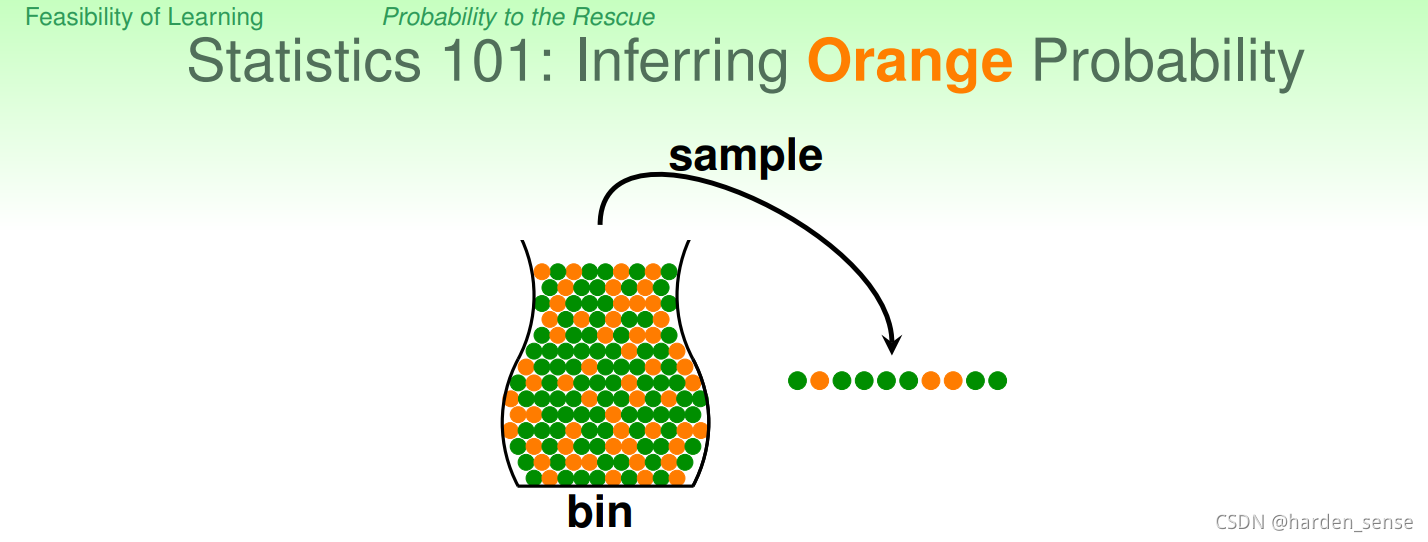
无论我们做的怎么好,sample取得多么完美,都不可能确保vvv完全等于uuu。下面用一个公式来衡量vvv与uuu的接近程度。也即霍夫定不等式:P[∣v−u∣>ϵ]≤2exp(−2ϵ2N)P[∣v−u∣>ϵ]≤2exp(−2ϵ ^2 N)P[∣v−u∣>ϵ]≤2exp(−2ϵ2N)
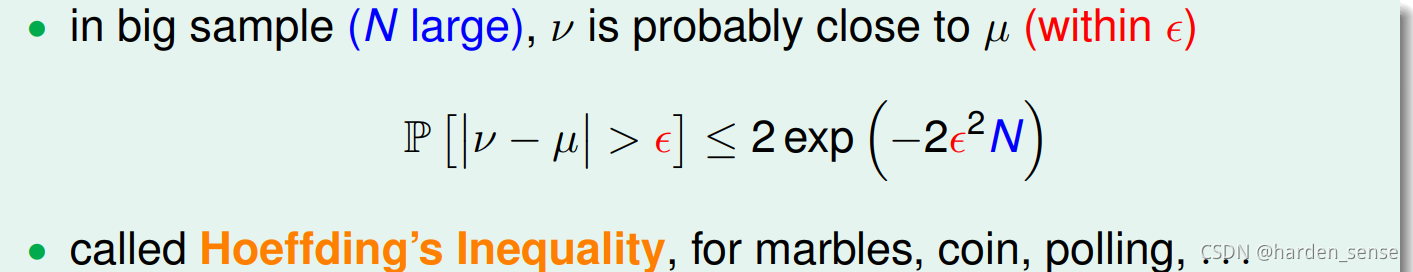
该不等式告诉我们当N足够大的时候,∣v−u∣∣v−u∣∣v−u∣的差值会足够的小。特别的当v=uv=uv=u我们称其为 probably approximately correct(PAC)
机器学习的可能性
将上面分析的列子与机器学习进行关联,推算机器学习的hypothesis h(x)与目标函数fff相等的可能性。罐子里的一颗颗弹珠类比于机器学习样本空间的中的xxx ,里面的绿色小球表示h(x)=fh(x)=fh(x)=f,橙色小球表示h(x)≠fh(x)\neq{f}h(x)=f
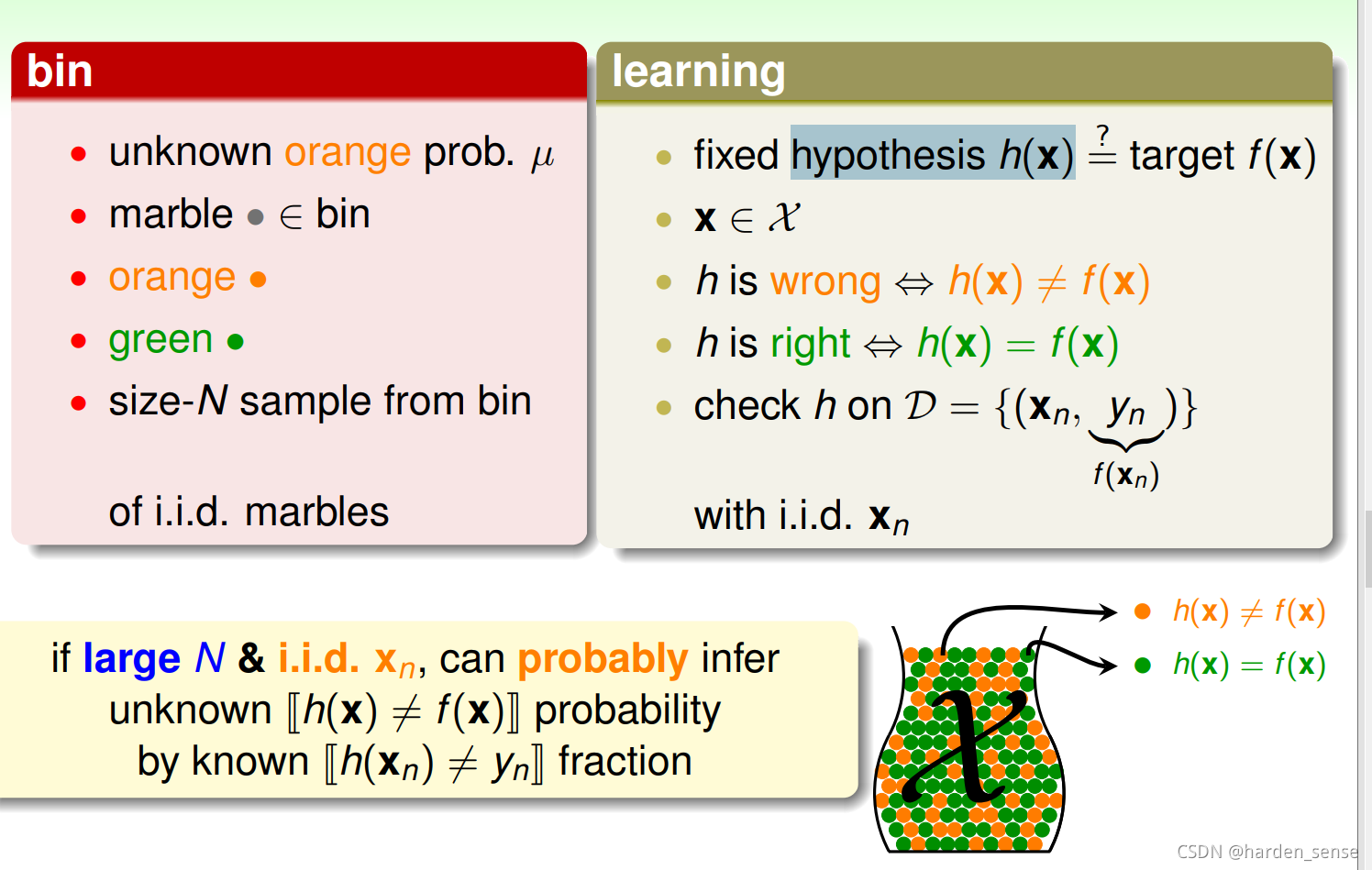 从罐子中取出的N个球,表示训练数据集D,且这两种抽样的样本与总体样本之间是独立同分布的。如果抽样样本 N够大,且是独立同分布的,那抽样样本中 h(x)=fh(x)=fh(x)=f的概率就能推广到抽样样本之外的h(x)=fh(x)=fh(x)=f。
从罐子中取出的N个球,表示训练数据集D,且这两种抽样的样本与总体样本之间是独立同分布的。如果抽样样本 N够大,且是独立同分布的,那抽样样本中 h(x)=fh(x)=fh(x)=f的概率就能推广到抽样样本之外的h(x)=fh(x)=fh(x)=f。
有一个关键问题将抽样样本中绿球的概率,视为训练集D上的正确的概率,在推广到训练集D之外的数据上这是机器学习能学到东西的本质。为什么训练集上得到的结果可以进行推广呢?这是因为二者的PCA是接近的。
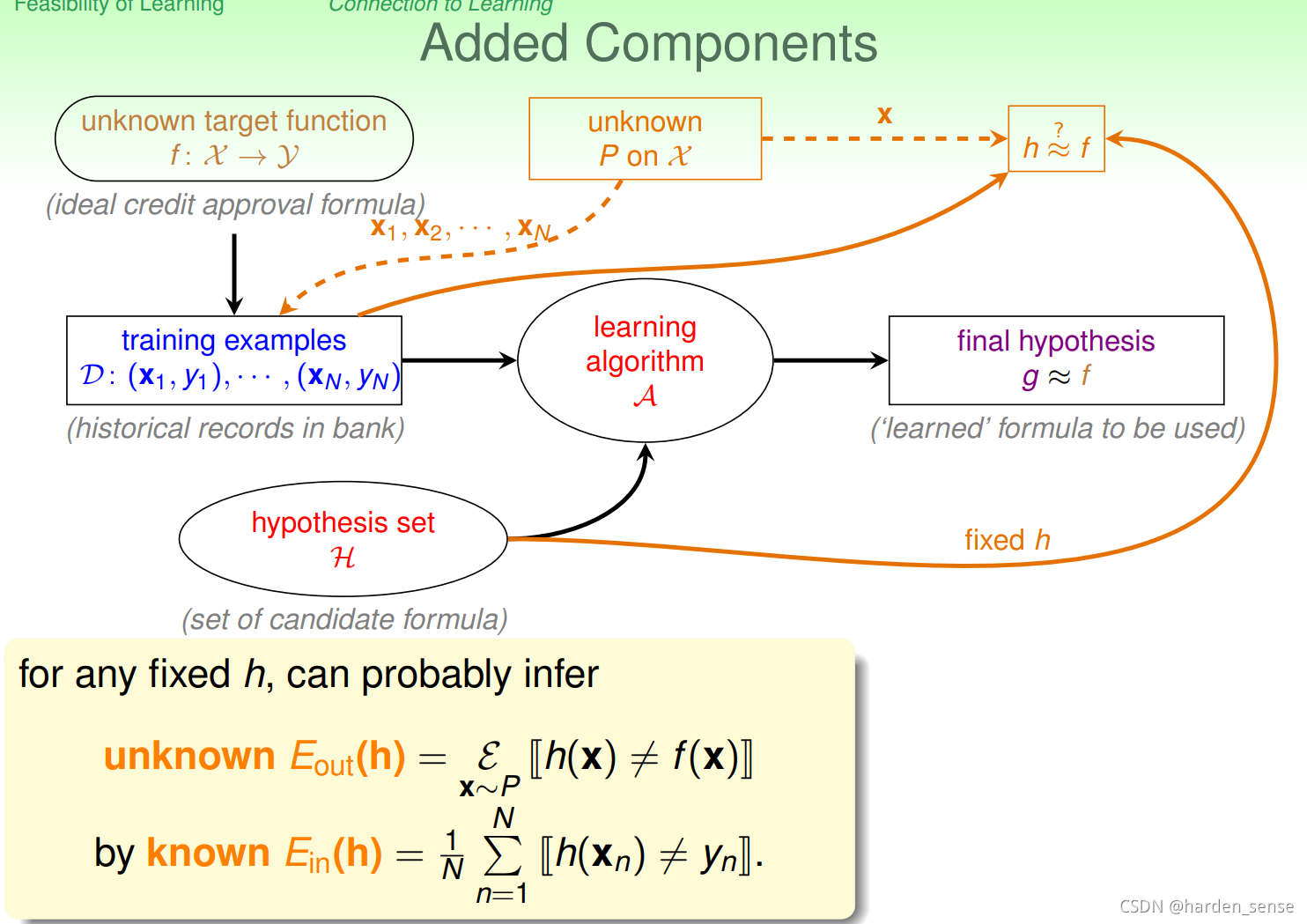
先引入两个记号:Ein(h)E_{in}(h)Ein(h):训练集上的错误率。Eout(h)E_{out}(h)Eout(h)所有数据集上的错误率。根据霍夫定不等式:P[∣Ein(h)−Eout(h)∣>ϵ]≤2exp(−2ϵ2N)P[∣E_{in}(h)−E_{out}(h)∣>ϵ]≤2exp(−2ϵ ^2N)P[∣Ein(h)−Eout(h)∣>ϵ]≤2exp(−2ϵ2N),Ein(h)E_{in}(h)Ein(h)和Eout(h)E_{out}(h)Eout(h)的PAC大概是相等的。 如果Ein(h)E_{in}(h)Ein(h)≈\approx≈Eout(h)E_{out}(h)Eout(h), 并且Ein(h)E_{in}(h)Ein(h)足够的小, 那么Eout(h)E_{out}(h)Eout(h)也会很小, 我们就认为机器学习学到了东西。
4.机器学习的真实情况
通过上面的分析我们明白,当Ein(h)E_{in}(h)Ein(h)足够的小时,机器可能学到了一些有用的东西。但是,是不是说Ein(h)E_{in}(h)Ein(h)越小学习的效果就越好呢。在回答这个问题之前我们来思考一个关于抛硬币的列子。假如说有300个人,我们让每个人抛硬币5次,出现五次正面朝上的概率是大于0.99的,我们恰好选择了,五次正面朝上的那个结果作为样本。那么我们会得到一个Ein(h)E_{in}(h)Ein(h)=0。显然这个hhh并不是最好的,因为我们非常清楚,最好的结果应该是0.5。但是在300人都抛硬币的列子中,我们选出五次结果都是正面的概率是非常大的。这个列子告诉我们当样本的数量很多的时候可能会引发Bad Sample。
Bad Sample会导致Ein(h)E_{in}(h)Ein(h)和Eout(h)E_{out}(h)Eout(h)的差别过大。也就是过大的选择会使情况恶化。

我们进行多次抽样,得到不同的数据集D,霍夫定不等式能够保证大多数的D都是比较好的情况,但是也会有一些D使得Ein(h)E_{in}(h)Ein(h)和Eout(h)E_{out}(h)Eout(h)差别过大。当然这是小概率事件。
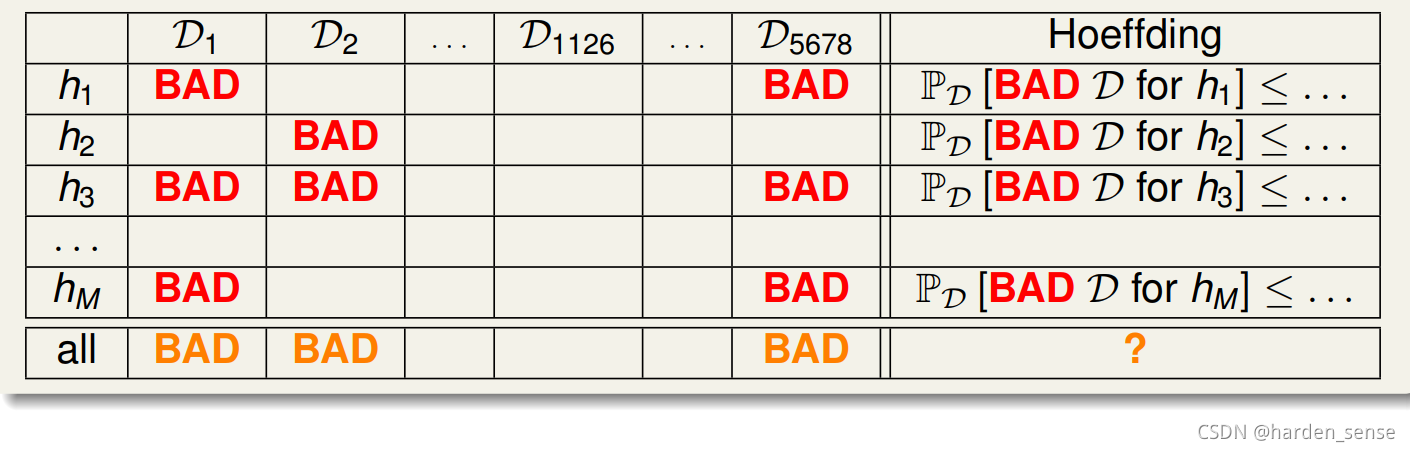
不同的数据集DnD_nDn,对于不同的hypotheses,有可能成为Bad Data。也就是说只要DnD_nDn在某个 hypotheses上表现为BAD,那么该DnD_nDn就是BAD。只有当DnD_nDn在所有的hypotheses表现为好的样本,那么该DnD_nDn才是好的。可以自由选择演算法进行建模,那么,根据 霍夫定不等式,Bad Data 的上界可以表示为 连级(union bound) 的形式:

其中,M是hypothesis的个数,N是样本D的数量,该union bound表明,当M有限,且N足够大的时候,Bad Data出现的概率就更低了,即能保证D对于所有的h都有Ein(h)E_{in}(h)Ein(h)≈\approx≈Eout(h)E_{out}(h)Eout(h)。所以,如果hypothesis的个数M是有限的,N足够大,那么通过演算法A任意选择一个 矩g,都有Ein(h)E_{in}(h)Ein(h)≈\approx≈Eout(h)E_{out}(h)Eout(h),如果Ein(h)E_{in}(h)Ein(h)≈\approx≈ 0那么我们就认为机器学到了东西。到目前为止,我们大概证明了机器学习是可行的。
思考:如果M是无限的又该怎么办呢?

















 4467
4467

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









