







线性回归是预测分析的基本常用方法。它是一种用于对因变量和一个自变量之间的关系进行建模的统计方法。 多元线性回归只是它的扩展版本。它尝试对两个或多个特征之间的关系进行建模,以拟合线性方程来预测一个因变量。
多元线性回归的步骤
执行多元线性回归的步骤几乎与简单线性回归的步骤相似 d不同 在评估中。我们可以使用它来找出哪个因素对预测输出的影响最大,以及不同的变量如何相互关联。
多元线性回归的方程为:
y=β0+β1X1+β2X2+⋯+βnXn
- y是因变量
- X1,X2,⋯XnX1,X2,⋯Xn是自变量
- β0β0是截距
- β1,β2,⋯βnβ1,β2,⋯βn是斜率
该算法的目标是找到可以根据自变量预测值的最佳拟合线方程。回归模型从数据集中学习一个函数(具有已知的 X 和 Y 值),并使用它来预测未知 X 的 Y 值。
使用虚拟变量处理分类数据
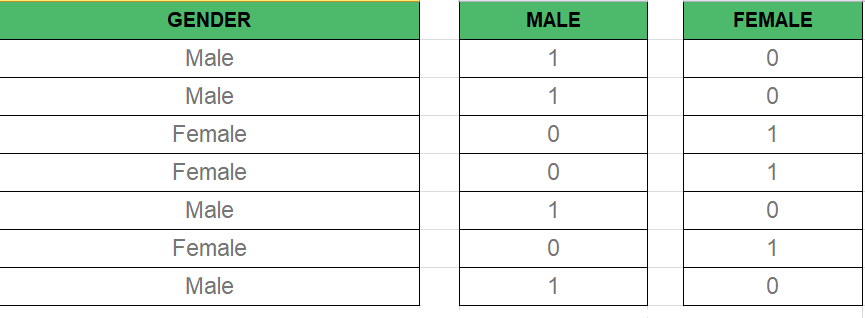
在多元回归模型中,我们经常会遇到分类数据,例如性别(男性/女性)、位置(城市/农村)等。由于回归模型通常需要数字输入,因此必须将分类数据转换为可用形式。
这就是 Dummy Variables 发挥作用的地方。虚拟变量是二进制变量(0 或 1),表示每个类别的存在或不存在。例如:
- 男性:如果男性为 1,否则为 0
- 女性:如果女性为 1,否则为 0
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1360
1360

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











