






在当前的大数据热潮中,大数据已经渗入各行各业了,遍地开花,包括传统的制造业,工业也纷纷重视起来。但是所谓兵无常势,水无常形,不同行业,有不同行业的特点,业务不同,因此知道如何根据行业,根据业务去进行数据建模,数据分析,建立起适用的数据仓库很重要。
上篇我们讲了数据仓库的构建过程,其中的底层数据库到中间层 OLAP 的过程就是我们的数据建模了。
一、数据建模的流程
数据建模是建立数据仓库的核心,也叫数据集市。数据建模划分为几个阶段,如下图所示 
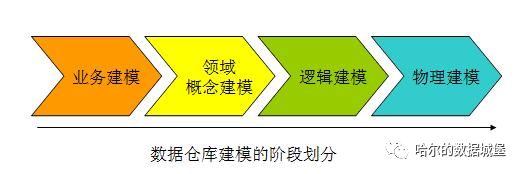
简单说明下这几个阶段
业务建模:对业务进行划分,理清业务之间的关系
领域概念建模:抽象关键业务概念,通过抽象业务之间的关联,形成完整的领域概念模型,得出业务,事件,说明。
逻辑模型:业务概念实体化,事件概念实体化,说明概念实体化
物理模型:针对物理平台,比如数据库,做出技术调整,生成脚本。
二、数据建模方法
上面我们对数据建模过程,那么数据建模有哪些方法呢。有我们做web时熟悉的ER建模,关系建模(适合 OLTP ), 还有专门针对数据仓库的维度建模,本文重点介绍维度建模。
维度建模, Kimball 最先提出这个概念,按照事实表,维度表来构建数据仓库。
可能有读者大人会有疑问,事实表是什么,维度表又是什么。
维度表(dimension):比如销售业务中,产品维,地域维,时间维,每个维度都有一张维度表,维度表里放着这些维度的属性。比如产品维度表,里面有产品id,产品类别,产品名,产品价格等等属性。
事实表(fact table):根据某些维度聚合形成的表。根据上面的例子,它的事实表中字段有 product_id(来自产品表),time (来自时间表),SalesAmount (销售额),count(销售数量)。
由上面的事实表,这边引出两个概念,维以及度量。
维:的具体描述信息记录在维表,事实表中的维属性只是一个关联到维表的键,并不记录具体信息。
度量:记录事件的相应数值,比如这里的产品的销售数量、销售额。
三、维度建模模型
维度建模本身也有现成的建模方法论给我们的 。维度建模有三种模型可以供我们选择,分别是星形模型,雪花模型,星座模型。
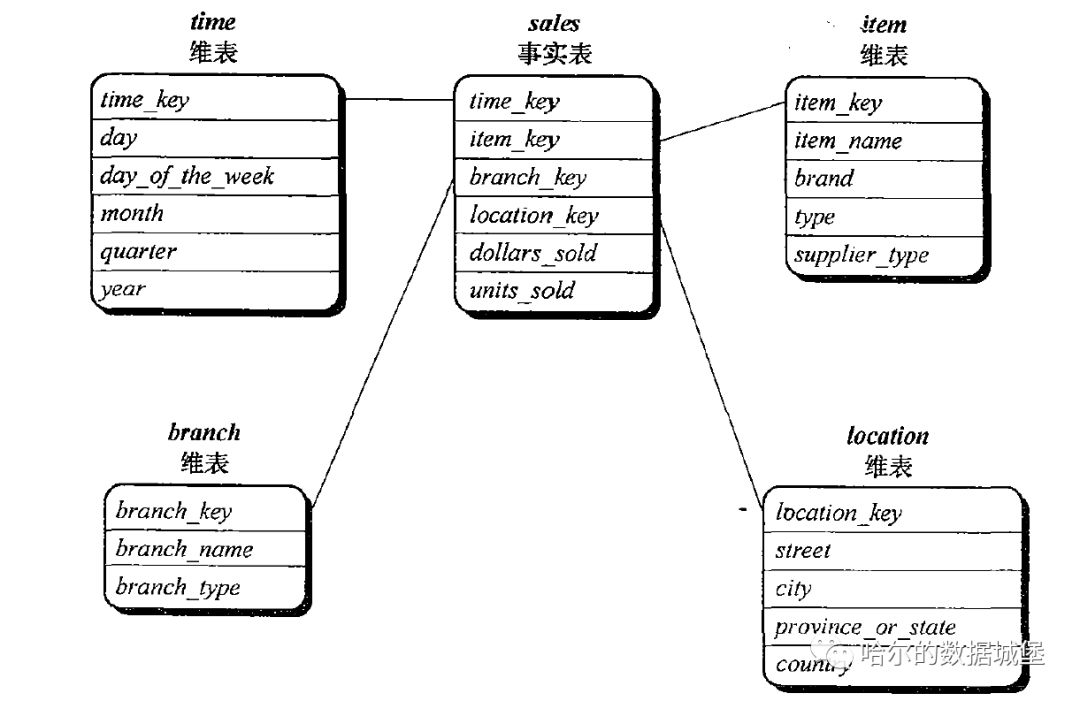
星形模型:由一个大的中心表(事实表),它包含大批数据并且不冗余以及一组小的附属表,每维一个。
直接上图,清晰明了
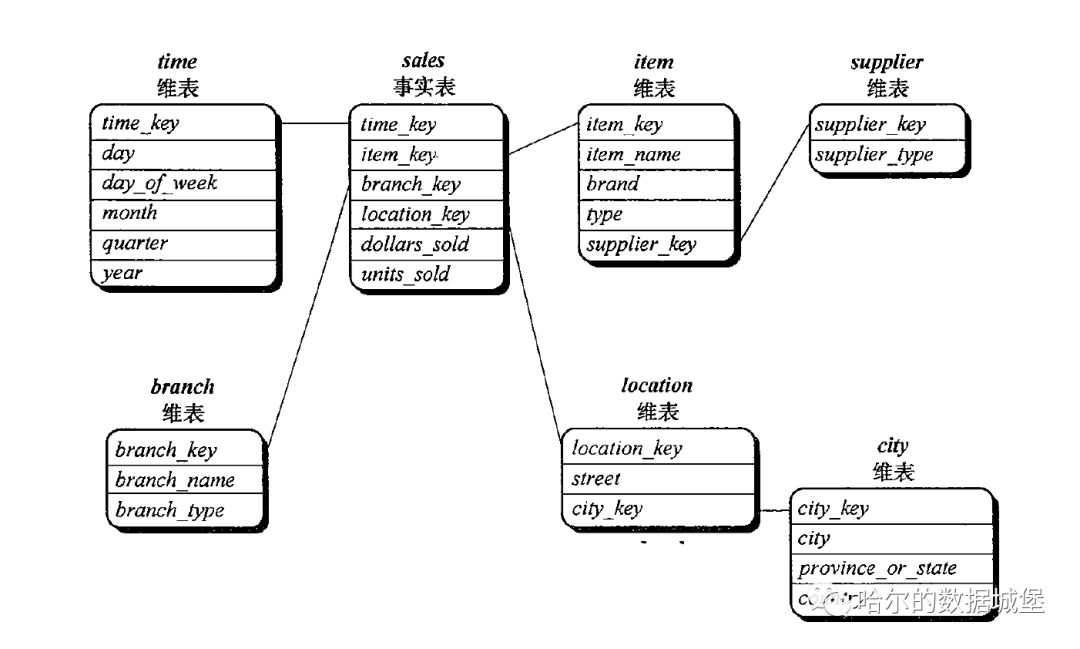
雪花模型:星形模型的变种,其中某些维表被规范化,因而把数据进一步分解到附加的表中。
星座模型:复杂的应用可能需要多个事实表共享维表。这种模式可以看作是星形模型的汇集。
对比
在性能上,星座模型是相对简洁也比较友好,因为它结构简单,跟雪花模型相比,少了一层 join 。跟星座模型相比,逻辑较简单。但如果遇到维度比较复杂的业务,雪花模型会是比较好的选择。不过很多时候事实表不止一个,一个维表可能被多个事实表关联。
四、OLAP
通过上面一系列的逻辑建模后,我们就要开始 OLAP 操作了。首先我们先要了解数据立方体的概念。 我们从一堆数据里提取信息,之后形成数据报告。这些数据报告通常使用二维表示,是行和列组成的二维表格。但在实际业务中,数据立方体可以理解为就是维度扩展后的二维表格。下面是一个三维立方体:
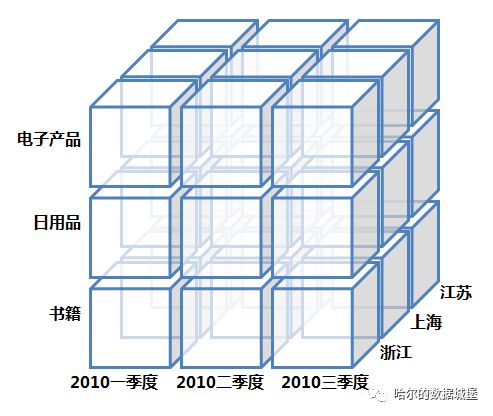
OLAP 以查询为主,也就是数据库的‘SELECT’,可以结合关系数据库的查询进行多表关联,同时也可以直接使用 COUNT,AVG,SUM 等聚合函数。
OLAP 的操作包括
上卷(Roll-up):通过沿一个维的概念分层向上攀升或者通过维归约在数据立方体上进行聚集。例如从城市层往省层聚集。
钻取(Drill-down):是上卷的逆操作。比如从国家层往省层聚集
切片(Slice):在给定的立方体的一个维上操作。比如选择time=‘2010第一季度’,对time维选择销量数据。
切块(Dice):跟切片相似,当时在两个或多个维上进行选择。比如 location =‘江苏’ and time = ‘2010第一季度’ or ‘2010第二季度’。
旋转(Pivot): 维的位置互换。比如在二维立方体上, 将行和列的位置互换。
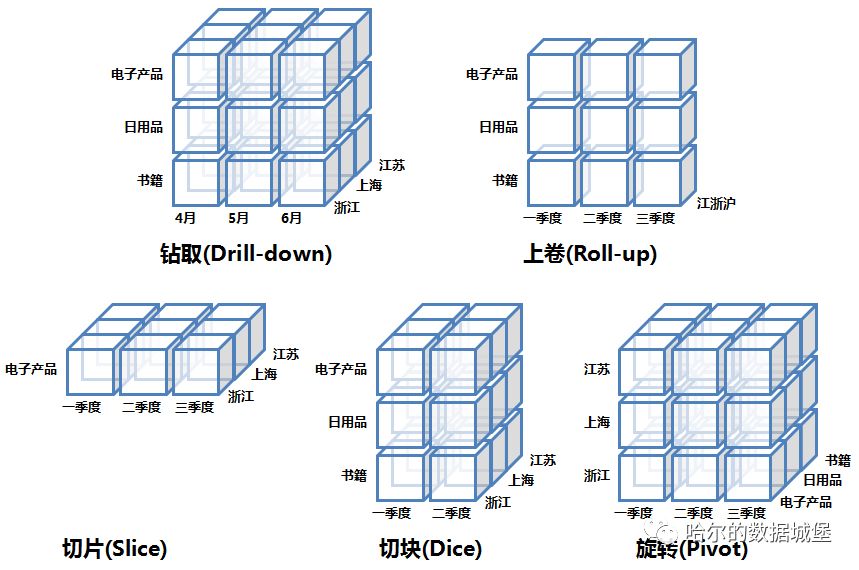
具体操作,举个例子
比如上卷
查询语法:
SELECT...GROUP BY ROLLUP(GROUPING_
COLUMN_REFERENCE_LIST);
例: 选择时间,地点,产品,总和(收入)AS销售收益 GROUP BY ROLLUP(时间,地点,产品);
具体操作:
# 上卷
SELECT Locates.地区, Products.分类, SUM(数量)
FROM Sales, Products, Locates
WHERE Sales.Locate_key = Locates.Locate_key
AND Sales.Product_key = Products.Product_key
GROUP BY Locates.地区, Products.分类
上卷跟下钻只要对 GROUP BY 进行操作
切片
查询语法:
使用<WHERE子句> <GROUP BY>选择某些属性的条件,并对某些属性进行聚合。
例: 选择产品,销售额(收入),其中PRODUCTS ='OPV'GROUP BY产品;
具体操作:
# 切片
SELECT Locates.地区, Products.分类, SUM(数量)
FROM Sales, Dates, Products, Locates
WHERE Dates.季度 = 2
AND Sales.Date_key = Dates.Date_key
AND Sales.Locate_key = Locates.Locate_key
AND Sales.Product_key = Products.Product_key
GROUP BY Locates.地区, Products.分类
切片跟切块主要对 WHERE 语句进行操作
五、小结
这篇文章,主要对数据仓库中的数据建模进行叙述。数据建模在整个数据仓库建立过程中起着至关重要的一步,甚至说是灵魂。是大数据工作的充分必要条件。数据建模其实是 从具体到抽象再到具体 的过程。底层思维就是一个客体与关系的哲学思想,从繁杂的现实业务整理提取出实体,并弄清楚以及实体与实体之间的关系。
两篇文章下来,可能大家都能感受到,建设数据仓库是很庞大,繁琐的一个过程,涉及业务,数据建模,技术架构等等。我们需要学习的还有很多。本文旨在对数据仓库中的数据建模有一个系统性的了解,具体需要我们在实践中慢慢学习。属于‘法’的层面吧。
推荐阅读:

喜欢就点一下【好看】呗~

















 6840
6840

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









