 Java字符与Unicode编码详解
Java字符与Unicode编码详解





 本文介绍了Java中字符的相关知识,包括字符编码采用的Unicode标准,Unicode与ASCII码的关系,char型变量的使用,以及字符常量和Unicode转义序列的细节。通过实例展示了字符编码在Java编程中的应用。
本文介绍了Java中字符的相关知识,包括字符编码采用的Unicode标准,Unicode与ASCII码的关系,char型变量的使用,以及字符常量和Unicode转义序列的细节。通过实例展示了字符编码在Java编程中的应用。
字符
一、字符
人类和计算机之间传递信息时必不可少的一项内容就是字符。人类通过拼写和发音来识别字符,而计符机则使用赋给各个字符的整数值,即“编码”来识别字符;字符通过整数值编码来表示并被识别
Unicode
字符编码有很多种,Java采用的是Unicode,Unicode采用下述方针来创建字符编码体系:
• 将特有的编号赋给所有字符
• 不依赖于平台
• 不依赖于程序
• 不依赖于语言
Unicode也在不断完善,Java版本和Unicode版本的对应关系如下:
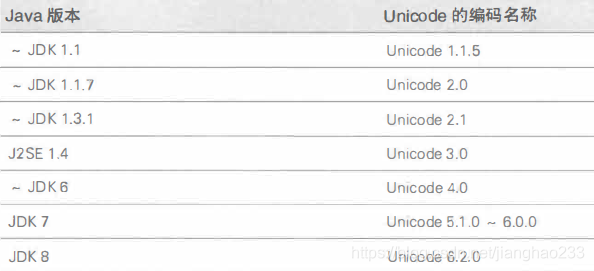
在开发、运行Java程序的环境中也可以使用Unicode之外的字符编码;无需关注字符编码的不同,Java编译器会自动执行字符编码的转换,再执行编译操作。
ASCII码
在Unicode中,各个字符基本都使用16位来表示,字符编码的值就为0~65535,其中, 最开始的128个字符与ASCII码一致
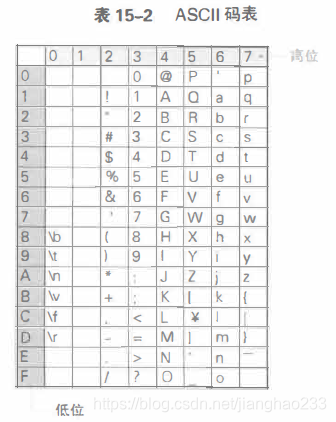
该表中所示的字符编码为十进制数的0~127, 用2位的十六进制数来表示就是0x00~0x7F;表中的0~F为十六进制数表示的各个位的值;例如, 字符'R'的编码为0x52, 字符'g'的编码为0x67;不要混淆数值和数字字符。数字字符'1'的字符编码并不是1, 而是十六进制数的0x31, 十进制数的49;
二、char型
char用于表示字符,char型为16位无符号整型,表示0-65535的数值;给char型变量赋值并显示:
// 字符和字符常量
class CharTester {
public static void main(String[] args) {
char c1 = 50;
char c2 = 'A';
char c3 = '字';
System.out.println("c1 = " + c1);
System.out.println("c2 = " + c2);
System.out.println("c3 = " + c3);
}
}
输出:
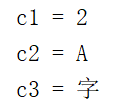
变量c1初始化为50,char型变量中可以赋入整数值,这是因为字符本身就是字符编码(整数值);
十进制数的50用十六进制数表示为0x32,,字符编码为0x32的字符是数字‘2’,因此使用println方法来显示变量c1时,会显示"2"
三、字符常量
变量c2和c3分别初始化为‘A’和’字‘,像这样用两个单引号将字符括起来的就是字符常量;使用字符常量进行初始化的变量c2和c3中分别赋入了‘A’和‘字’的字符编码
字符常量的示例如下:
1、'A' --- 字母"A"
2、'字' --- 汉字'字'
3、“\” --- 单引号
4、‘\n’---换行符
Unicode转义
Unicode转义通过在\u后而加上4位十六进制数来表示字符,如果将前面示例中的4个字符用Unicode转义来表示的话,则如下所示(十六进制数的a-f也可以写为大写字丹A-F)

ASCII编码中包含的字符,只需在十六进制数的编码前面加上\u00, 就能变成Unicode转义
程序的编译分为儿个阶段、其中最开始的阶段就是Unicode转义被替换为相应的字符,下面的程序会发生编译错误
System.out.println("ABC\u000aDEF"); //错误
这是因为在进行实际的编译操作之前,\u000a会被替换为真正的换行符,如下:
System.out.println("ABC
DEF");
Unicode转义并不是说仅仅将八进制的转义表示的基数由8变为16就可以了,原则上它只用于表示外语字符或特殊符号等情况;换行符和同车符不可以书写为\u000a和\u000d,在Unicode转义中,\后面可以放置多个u。例如字母A可以写成\uu0041或者\uuu0041 (这是为了区别在编译过程中可被替换的字符和不可被替换的字符的语法规格)。

















 8488
8488

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









