



目录
一、简介
1、概述
Kafka是最初由Linkedin公司开发,是一个分布式、分区的、多副本的、多订阅者,基于zookeeper协调的分布式日志系统,常见可以用于web/nginx日志、访问日志,消息服务等等,Linkedin于2010年贡献给了Apache基金会并成为顶级开源项目。Kafka凭借着自身的优势越来越受到互联网企业的青睐,如今已经成为商业级的消息中间件
2、消息中间件
消息中间件是利用高效可靠的消息传递机制进行异步的数据传输,并基于数据通信进行分布式系统的集成。通过提供消息队列模型和消息传递机制,可以在分布式环境下扩展进程间的通信
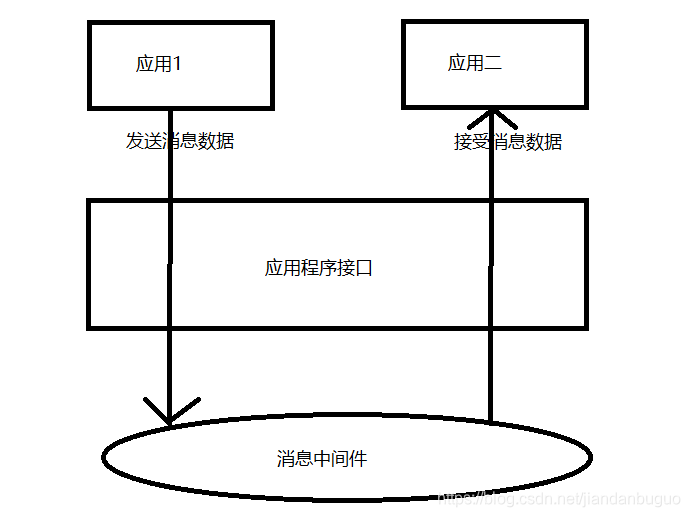
消息中间件两种主要的消息传递模式:点对点传递模式、发布-订阅模式
-
点对点传递模式
在该模式下,当一个消息持久化到一个队列中,将会有一个或多个消费者消费队列中的数据。但是一条消息只能被消费一次。当一个消费者消费了队列中的某条数据之后,该条数据则从消息队列中删除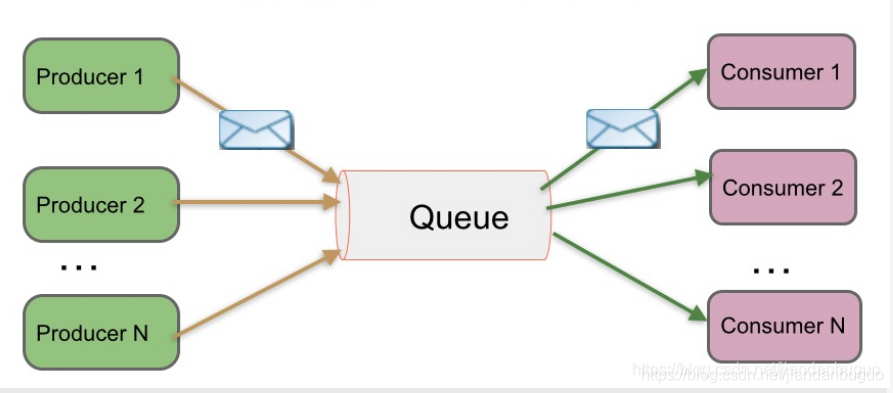
-
发布-订阅模式
在该模式下,消息被持久化到一个topic(主题)中。与点对点消息模式不同的是,消费者可以订阅一个或多个topic,消费者可以消费该topic中所有的数据,同一条数据可以被多个消费者消费,数据被消费后不会立马删除。
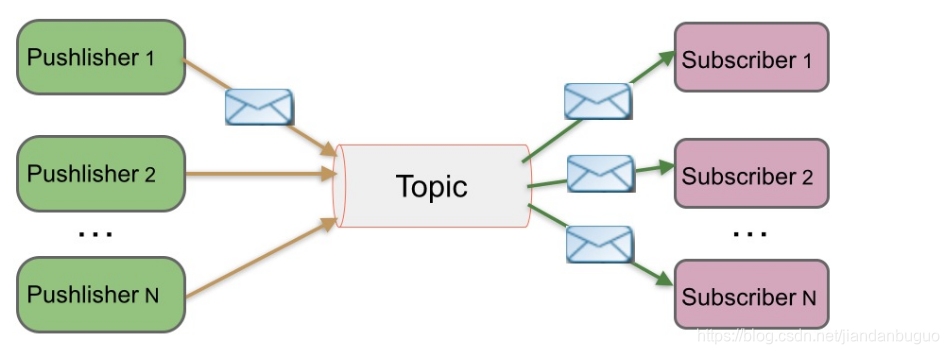
kafka就是基于发布-订阅模式的一种消息系统
3、Kafka的体系架构
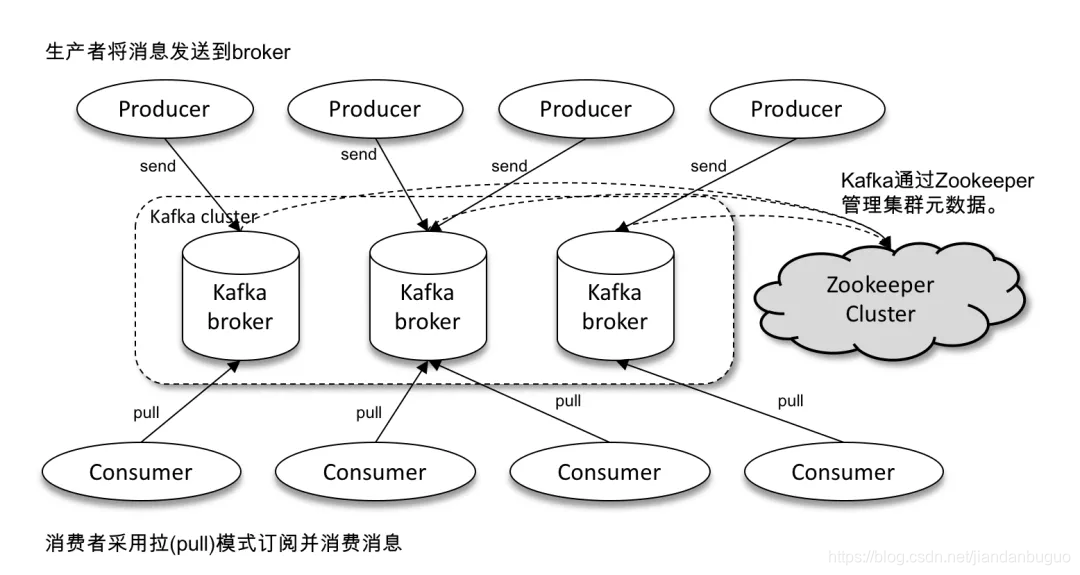
如上图所示,Kafka 体系架构包括若干 Producer、若干 Broker、若干 Consumer,以及一个 ZooKeeper 集群。kafka通过zookeeper管理集群,选举leader。
4、kafka常用名词解释
-
Broker
已发布的消息保存在一组服务器中,它们被称为代理(Broker)或Kafka集群。一个kafka节点即是一个broker,多个broker组成kafka集群 -
Producer
消息生产者,一个向broker发布消息的客户端应用程序。 -
Consumer
消息消费者,表示一个从消息队列中取得消息的客户端应用程序 -
Topic
主题,kafka通过topic对消息进行分类,每条消息都要指定topic。 -
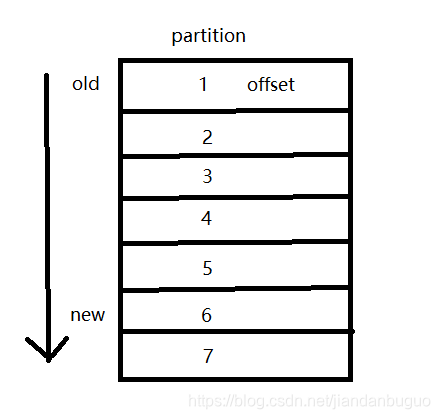
Partition
分区,一个topic可以分成多个partition。topic是逻辑上的概念,partition是物理上的概念,以文件的形式存在,每条消息在文件中有自己的offset(偏移量),当新的消息被存储到partition中时,会被追加到文件的末尾。
-
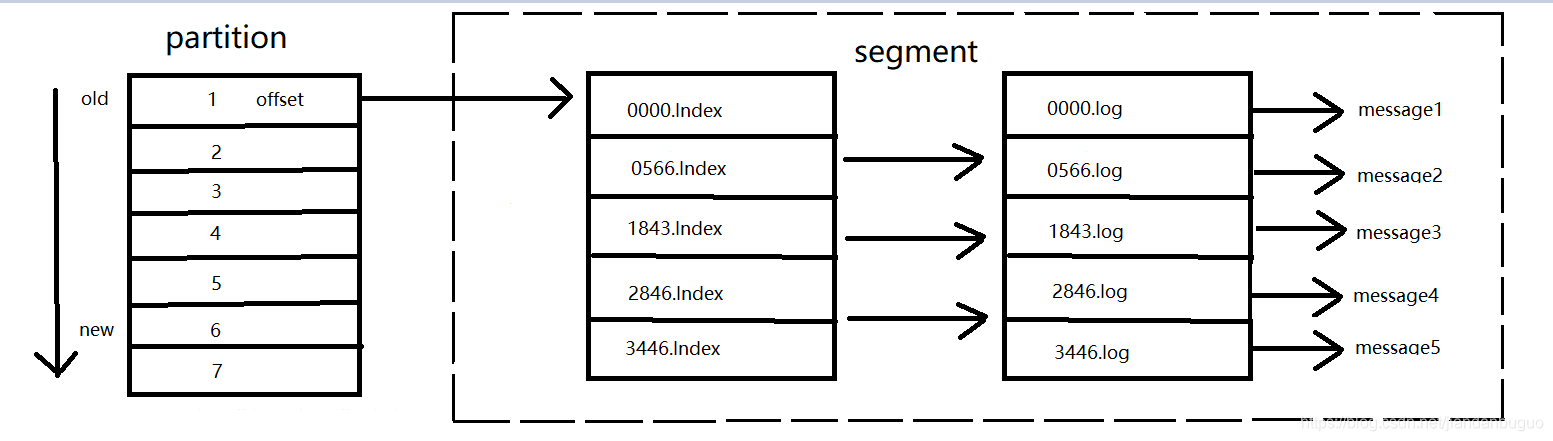
segment
partition 物理上由多个 segment 组成。 index(索引文件),log(数据文件)组成一个segment。
其中索引文件中保存了 offset 和 position, offset 是具体那一条消息,position 表示具体消息存储在 log 中的物理地址,但kafka 并不是每个 offset 都保存了,每隔 6 个 offset 存储一条索引数据。log 数据文件中并不是直接存储数据,而是通过许多的 message 组成,message 包含了实际的消息数据。
5.topic、partition和segment
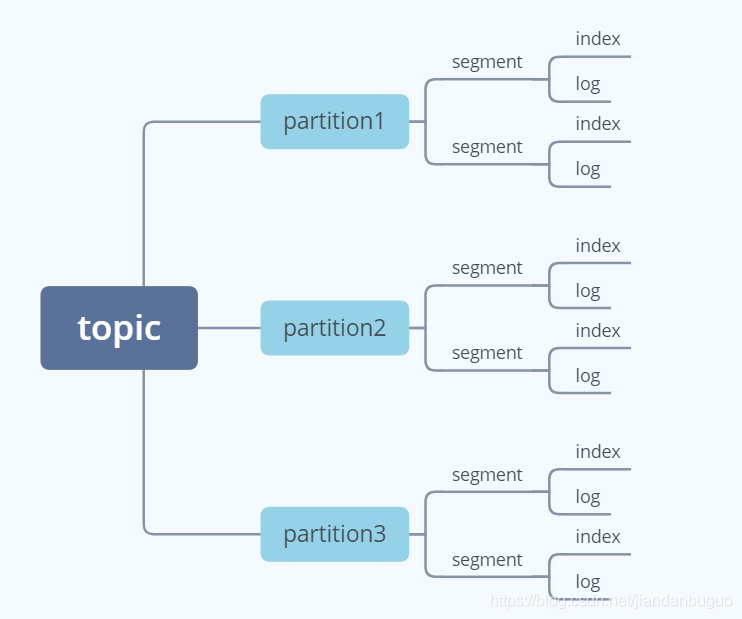
6.topic、partition和replication
Kafka 中的消息以topic进行归类,topic是一个逻辑上的概念,它还可以细分为多个分区,一个分区只属于单个主题。而kafka又为partition引入了多副本(replication)机制,来提升kafka的容错性。
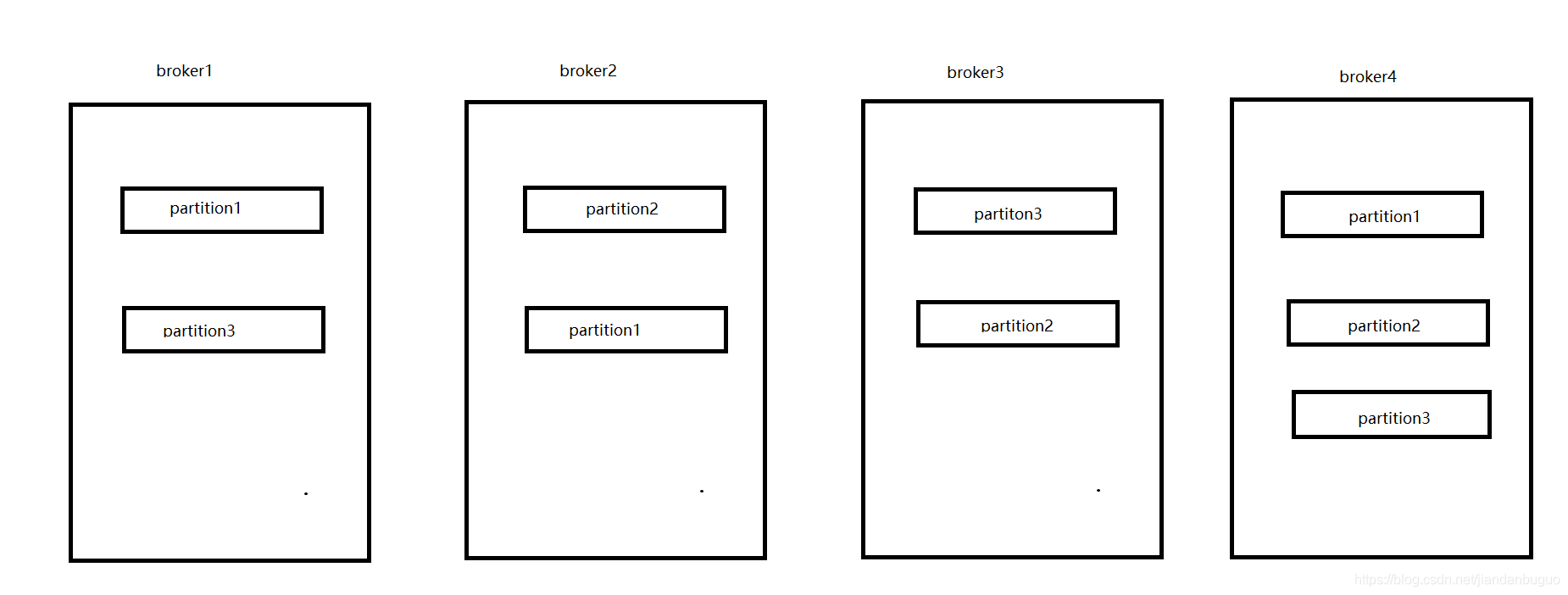
如上图,kafka集群有4个broker,每个topic有三个分区,每个分区有三个replication(副本)
二、Kafka存储的可靠性
1、文件存储机制
在上面kafka名词中介绍了kafka以topic分类,一个topic可以分成若干个分区,每个分区又由若干segment组成
我们通过以下命令新建一个名为testTopic的topic,并指定3个分区,1个副本
kafka-topics.sh --create --zookeeper 192.168.233.133:2181 --topic firstTopic --partitions 3 --replication-factor 1

如上图在我们指定/kafka-logs 路径下,会生成以topic 名称-分区数命名的文件,进入该文件,可看到如下图所示的segment文件,文件命名是以上一个segment文件最后一条消息的offset值,数值大小为64位,20位数字字符长度,没有数字用0填充

对于在分区中查找的策略是:
假设有三个segment文件,分别为00000000000000000000.index、0000000000000010000.index、00000000000000020000.index,想要读取offset为15002的消息,首先我们知道index文件是以上个segment文件的最后offset命名的,故第一个文件的初始偏移量为0,第二个为10001,第三个为20001,所以15000在第二个文件,由于命名规则的特殊性,只需根据二分法就能够很快找到对应文件。找到文件后,依次定位到 000000000000000010000.index 的元数据物理位置和 000000000000000010000.log 的物理偏移地址,由于每隔 6 个 offset 存储一条索引数据,故只能拿到 15000 的物理偏移地址,后再通过 log 顺序查找直到 offset=15002 为止
- 为什么有了 partition 还需要 segment ?
如果不引入 segment,那么一个 partition 只对应一个文件(log),随着消息的不断发送这个文件不断增大,由于 kafka 的消息不会做更新操作都是顺序写入的,如果做消息清理的时候只能删除文件的前面部分删除,不符合 kafka 顺序写入的设计,如果多个 segment 的话那就比较方便了,直接删除整个文件即可保证了每个 segment 的顺序写入。 - 为什么kafka 并不是每个 offset 都保存了,而是每隔 6 个 offset 存储一条索引数据?
因为 index 文件中并没有为数据文件中的每条消息都建立索引,而是采用了稀疏存储的方式,每隔一定字节的数据建立一条索引。这样避免了索引文件占用过多的空间,从而可以将索引文件保留在内存中。但缺点是没有建立索引的 Message 也不能一次定位到其在数据文件的位置,从而需要做一次顺序扫描,但是这次顺序扫描的范围就很小了。
2、消息的复制机制
Kafka 中的消息以topic进行归类,topic是一个逻辑上的概念,它还可以细分为多个分区,一个分区只属于单个主题。当生产者传递进来一个消息时,会被顺序追加到partition中。
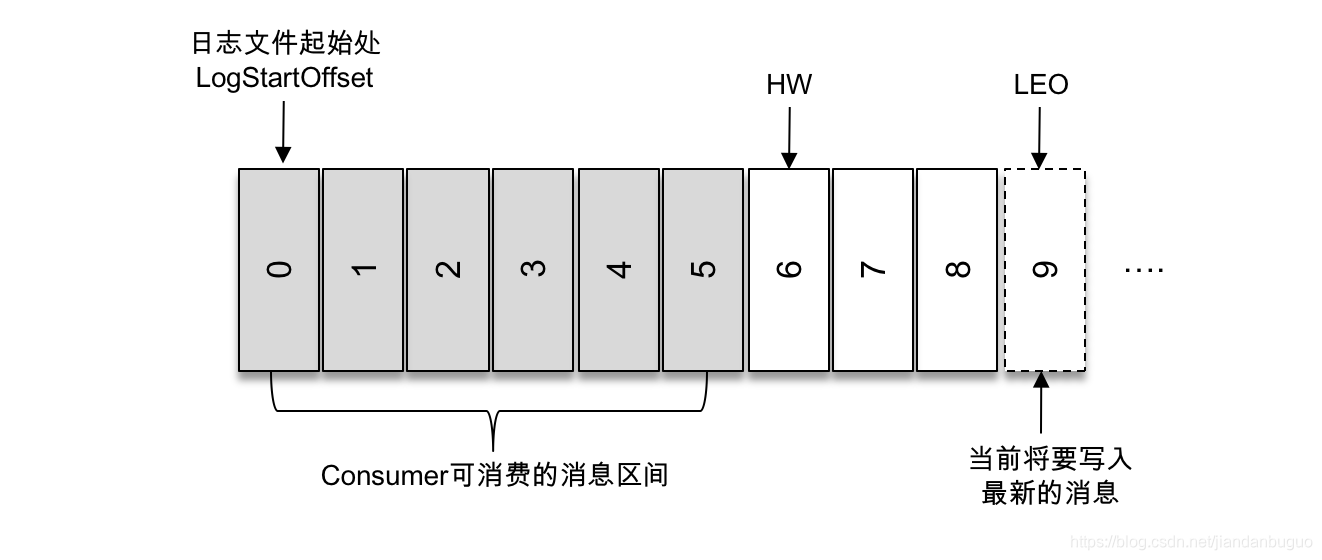
上图中,有两个新的概念HW和LEO,先解释一下他们的意思,具体用途稍后解释
- HW
HW是 High Watermark 的缩写,俗称高水位,它标识了一个特定的消息偏移量(offset),消费者只能拉取到这个 offset 之前的消息。如上图日志文件的 HW 为6,表示消费者只能拉取到 offset 在0至5之间的消息,而 offset 为6的消息对消费者而言是不可见的 - LEO
LEO 是 Log End Offset 的缩写,它标识当前日志文件中下一条待写入消息的 offset。如上图所示,第一条消息的 offset(LogStartOffset)为0,最后一条消息的 offset 为8,offset 为9的消息用虚线框表示,代表下一条待写入的消息。
而kafka又为partition引入了多副本机制,来提升kafka的容错性。如下图,kafka集群有4个broker,每个topic有三个分区,每个分区有三个replication(副本)
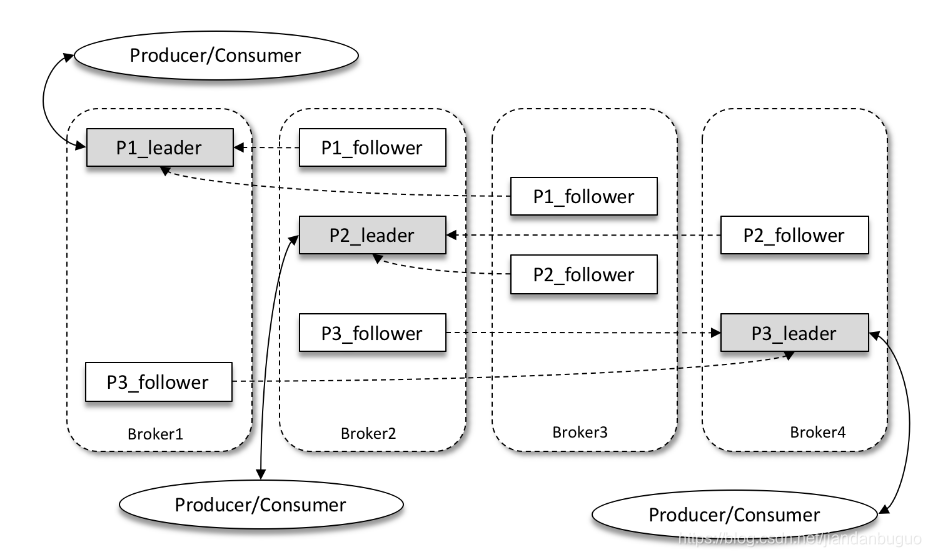
三个副本中会有一个leader和2个follower,leader负责处理partition的请求,follower会定期同步leader中接收的消息。
分区中的所有副本统称为 AR(Assigned Replicas)。所有与 leader 副本保持一定程度同步的副本组成ISR(In-Sync Replicas),ISR 集合是 AR 集合中的一个子集。
与 leader 副本同步滞后过多的副本组成OSR(Out-of-Sync Replicas),因此AR=ISR+OSR。在正常情况下,所有的 follower 副本都应该与 leader 副本保持一定程度的同步,即 AR=ISR,OSR 集合为空。(在OSR中的副本当消息同步的与leader一致时,会重新加入ISR)
Leader 副本负责维护和跟踪 ISR 集合中所有 follower 副本的滞后状态,当 follower 副本落后太多或失效时,leader 副本会把它从 ISR 集合中剔除。默认情况下,当 leader 副本发生故障时,只有在 ISR 集合中的副本才有资格被选举为新的 leader(也可通过设置改变)。
介绍完以上的概念,那么一条消息是如何同步的呢?
在上面我们介绍了HW高水位,高水位是由在ISR中的同一个分区的最小LEO决定的,如下图一个分区在ISR中有3个,一个为leader,2个follower,假设当前状态他们消息同步的一致
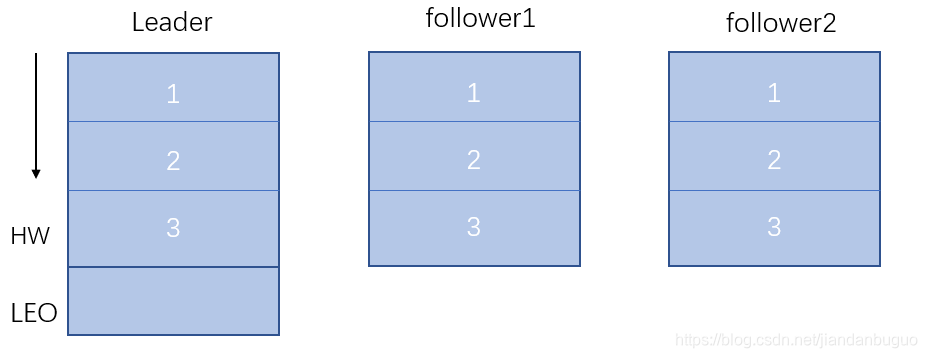
当producer向leader发送消息时,会通知follower来同步消息
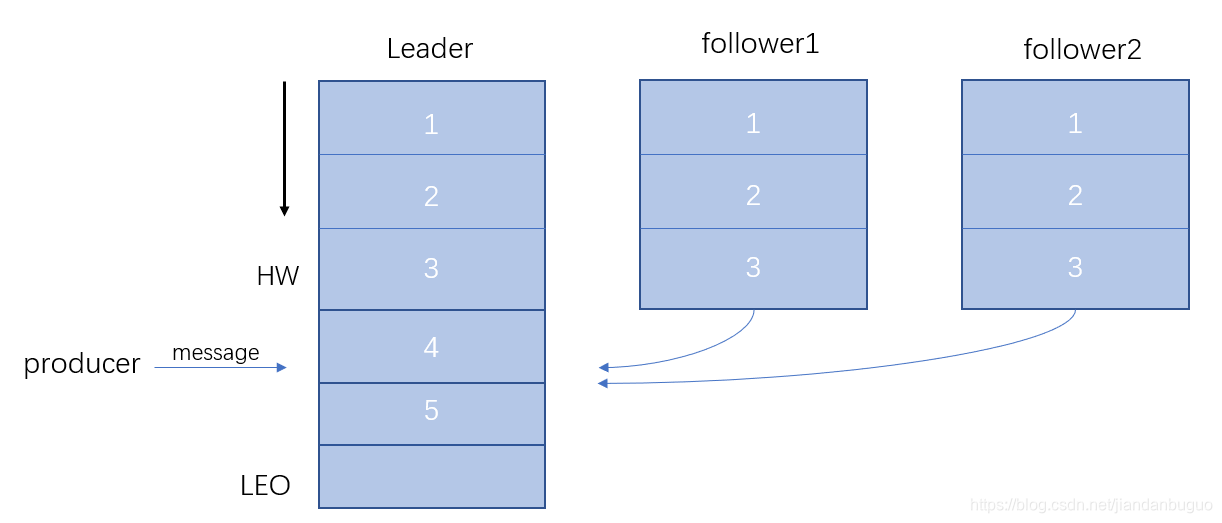
由于网络等原因,follower同步消息有快有慢,当一条消息被全部follower同步时,leader会将HW更新到当前消息
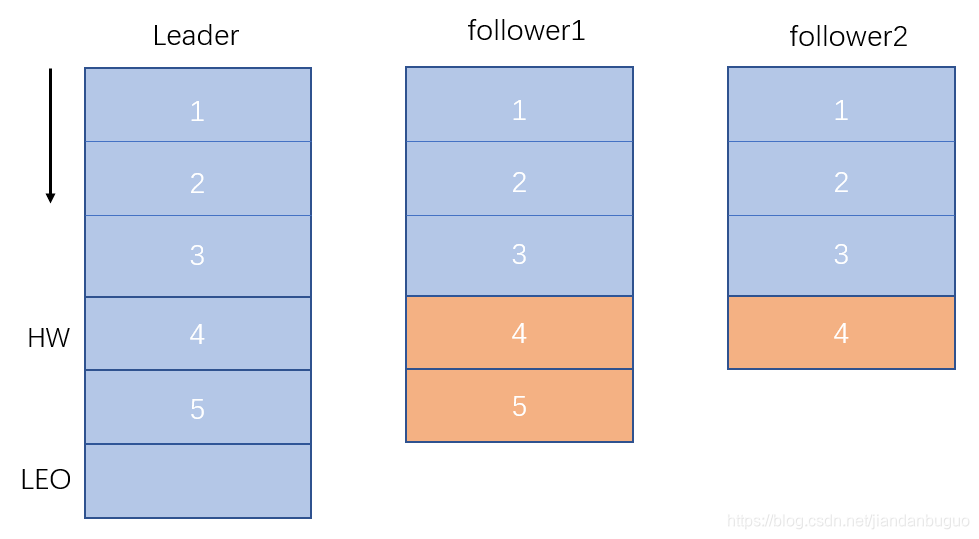
最终follower同步消息与leader一致
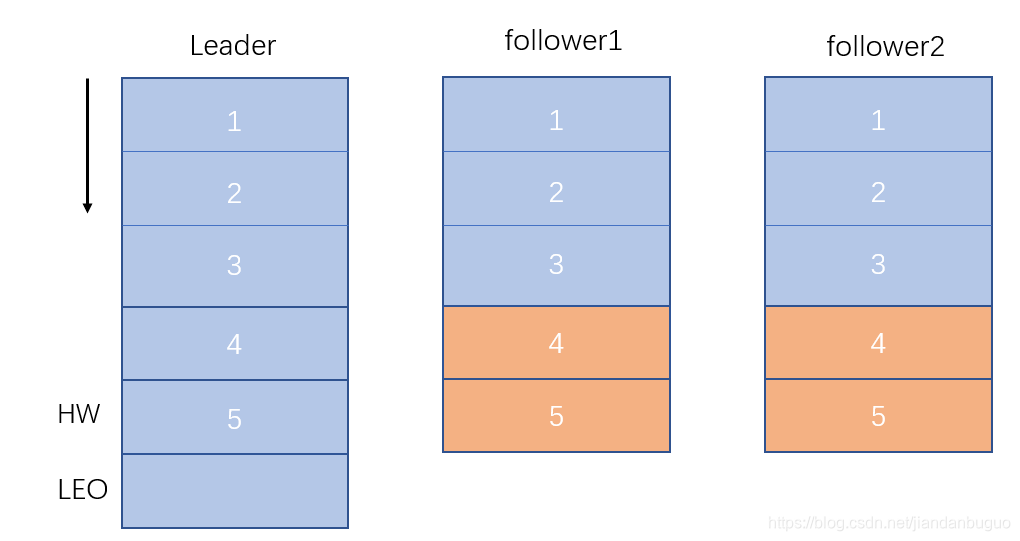
上述过程展示了消息的简单同步过程,在实际中Producer在发布消息到某个Partition时,先通过Zookeeper找到该Partition的Leader,然后无论该Topic的副本数为多少(也即该Partition有多少个Replica),Producer只将该消息发送到该Partition的Leader。Leader会将该消息写入其本地Log。每个Follower都从Leader pull数据。这种方式上,Follower存储的数据顺序与Leader保持一致。Follower在收到该消息并写入其Log后,向Leader发送ACK(应答机制,后面会介绍)。一旦Leader收到了ISR中的所有Replica的ACK,该消息就被认为已经commit了,Leader将增加HW(即offset)并且向Producer发送ACK。
为了提高性能,每个Follower在接收到数据后就立马向Leader发送ACK,而非等到数据写入Log中。因此,对于已经commit的消息,Kafka只能保证它被存于多个Replica的内存中,而不能保证它们被持久化到磁盘中,也就不能完全保证异常发生后该条消息一定能被Consumer消费。
3、数据可靠性的保障
消息发送模式
Kafka的发送模式由producer端的配置参数producer.type来设置,这个参数指定了在后台线程中消息的发送方式是同步的还是异步的,默认是同步的方式,即producer.type=sync。如果设置成异步的模式,即producer.type=async,该模式下producer以batch(批处理)的形式push数据,这样会极大的提高broker的性能,但是这样会增加丢失数据的风险。如果需要确保消息的可靠性,必须要将producer.type设置为sync。
对于异步模式,有如下四个参数可以设置:
| 参数 | 描述 |
|---|---|
| queue.buffering.max.ms | 默认值:5000。启用异步模式时,producer缓存消息的时间。比如设置成1000 ,它会缓存1s的数据然后发送出去,这样可以极大的增加broker的吞吐量,但是会降低数据的失效性 |
| queue.buffering.max.message | 默认值:10000。producer缓存队列里的最大缓存消息数,如果超过这个值,producer就会阻塞或者丢弃消息。 |
| queue.enqueue.timeout.ms | 默认值:-1。当达到上面参数时producer会阻塞等待的的时间。如果设置为0,队列满时producer不会阻塞,消息会被直接丢弃。若设置为-1,producer会阻塞,不会丢弃消息。 |
| batch.num.message | 默认值:200。启用异步模式时,一个batch缓存消息的数量,当达到这个数值时producer才会发送。 |
数据可靠性级别
当producer向leader发送数据时,可以通过request.required.acks参数来设置数据可靠性的级别。
| 参数 | 描述 |
|---|---|
| request.required.acks=1 | producer在数据replication的leader收到数据并且得到确认后发送下一条数据。如果leader宕机,消息丢失。 |
| request.required.acks=0 | producer无需确认leader的回复而继续发送,这种情况下数据可靠性最低,但是传输效率最高。 |
| request.required.acks=-1 | producer需要等待replication中所有的follower都确认收到数据后才发送下一条数据。可靠性最高,但是当只有leader而没有follower的时候和request.required.acks=1一样 |
副本同步机制
kafka每个topic的partition有N(N>=1)个副本,其中N由replica factor这个配置项决定。kafka通过多个副本实现故障的自动转移,当kafka集群中一个节点挂掉后可以保证服务仍然正常。多个副本中有一个副本为leader,其余为follower。
关于leader和follower之间的数据复制,考虑下面几个问题:
1.当leader挂掉后,会通过选举机制从follower中产生一个新的leader。加入之前的leader已有的数据条数为5,被选举的follower只复制了其中三条,那么consumer从新的leader获取数据就会出现问题,这种情况下如何保证数据正确性?
一个partition中取ISR中最小的LEO作为HW,consumer最多只能消费到HW所在的位置。另外每个replica都有HW,leader和follower各自负责更新自己的HW的状态。对于leader新写入的消息,consumer不能立刻消费,leader会等待该消息被所有ISR中的replicas同步后更新HW,此时消息才能被consumer消费。这样就保证了如果leader所在的broker失效,该消息仍然可以从新选举的leader中获取。对于来自内部broker的读取请求,没有HW的限制。
由此可见,Kafka的复制机制既不是完全的同步复制,也不是单纯的异步复制。同步复制要求所有能工作的follower都复制完,这条消息才会被commit,这种复制方式极大的影响了吞吐率。而异步复制方式下,follower异步的从leader复制数据,数据只要被leader写入log就被认为已经commit,这种情况下如果follower都还没有复制完,落后于leader时,突然leader宕机,则会丢失数据。而Kafka的这种使用ISR的方式则很好的均衡了确保数据不丢失以及吞吐率。
2.若某个follower出现故障,导致复制数据出现异常,该如何保证系统可靠性?
对于这两个问题的解决的方法,kafka引入了HW和ISR,概念在上面已经解释,对于问题的解决在消息的复制机制中得以体现。
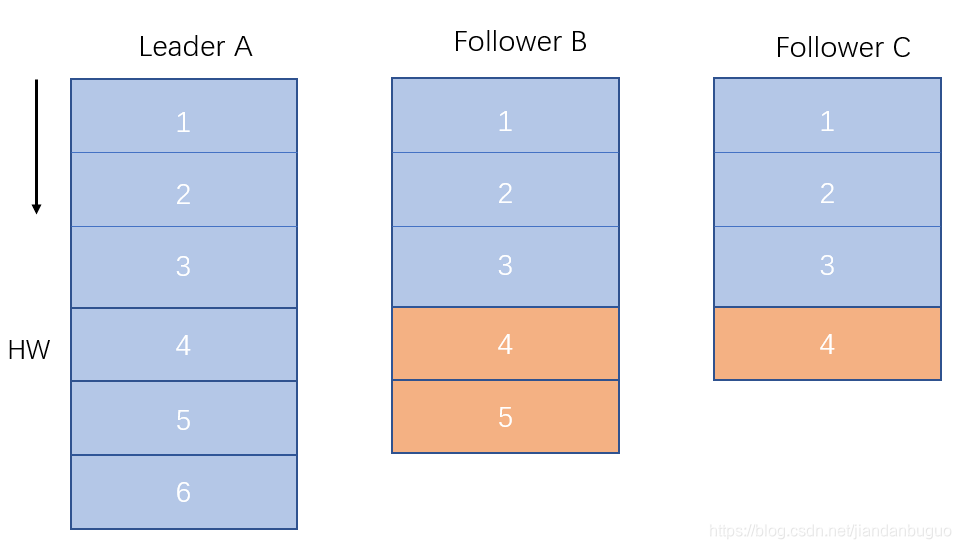
如上图,某个topic的某partition有三个副本。A作为leader肯定是LEO最高,B紧随其后,C由于配置比较低,网络比较差,故而同步最慢。这个时候A宕机,如果B成为leader,假如没有HW,在A重新恢复之后会做同步操作,在宕机时log文件之后直接做追加操作,而假如B的LEO已经达到了A的LEO,会产生数据不一致的情况,所以使用HW来避免这种情况。 A在做同步操作的时候,先将log文件截断到之前自己的HW的位置,即3的位置,之后再从B中拉取消息进行同步。
如果是C宕机,C恢复过来,它首先将自己的log文件截断到上次checkpointed时刻的HW的位置,之后再从leader中同步消息。leader挂掉会重新选举,新的leader会发送“指令”让其余的follower截断至自身的HW的位置然后再拉取新的消息。
这种宕机后截断到HW的操作是kafka的文件截断机制。
consumer消息保证
有三种级别的消息保证:
At most once: 消息可能会丢,但绝不会重复传输
At least once:消息绝不会丢,但可能会重复传输
Exactly once:每条消息肯定会被传输一次且仅传输一次
(1)先commit offset再消费消息,如果在offset被commit之后但消息没有被消费时consumer宕机,则会丢失消息,实现at most once。
(2)先消费消息,再commit offset,如果在offset被commit之前consumer宕机,当重启时会重复消费。实现at least once。
(3)要实现exactly once则需要对commit offset和消息消费加上事务,或者对at least once加上去重机制。
Leader选举
在上面我们了解到,leader接收生产者的消息后,会通知follower同步,只有ISR中该分区的所有follower都同步完成,leader才会commit(提交),这种策略有效预防了数据被写进leader后,任何follower都没有同步的情况下,leader宕机导致数据丢失的问题。对于生产者producer若是在一定时间间隔内没有收到commit,会重新发送消息,当然可以通过request.required.acks的设置来选择是否等待消息的commit。这种机制确保了只要ISR中有一个或者以上的follower,一条被commit的消息就不会丢失。
有一个需要考虑的问题是如果leader宕机了,要在怎么选举新的leader。我们需要考虑的是选举出新leader后不能造成数据丢失,因此被选举的新leader需要具备原leader所有已经commit的消息。讲到这里大家或许能够想到HW和ISR的作用。事实上leader的选举机制确实是利用了HW和ISR,Kafka在Zookeeper中为每一个partition动态的维护了一个ISR,这个ISR里的所有follower都跟上了leader,只有ISR里的成员才能有被选为leader的可能(unclean.leader.election.enable=false)。在这种模式下,对于f+1个副本,一个Kafka topic能在保证不丢失已经commit消息的前提下容忍f个副本的失败,在大多数使用场景下,这种模式是十分有利的。
当在ISR中至少有一个follower时,Kafka可以确保已经commit的数据不丢失,但如果某一个partition的所有replica都挂了,就无法保证数据不丢失了。这种情况下有两种可行的方案:
①等待ISR中任意一个replica“活”过来,并且选它作为leader
②选择第一个“活”过来的replica(并不一定是在ISR中)作为leader
这就需要在可用性和一致性当中作出一个简单的抉择。如果一定要等待ISR中的replica“活”过来,那不可用的时间就可能会相对较长。而且如果ISR中所有的replica都无法“活”过来了,或者数据丢失了,这个partition将永远不可用。选择第一个“活”过来的replica作为leader,而这个副本不是ISR中的副本,那即使它并不保障已经包含了所有已commit的消息,它也会成为leader并作为consumer的数据源。默认情况下,Kafka采用第二种策略,即unclean.leader.election.enable=true,也可以将此参数设置为false来启用第一种策略。
三、安全可靠性配置
要保证数据写入到Kafka是安全的,高可靠的,需要如下的配置:
- topic的配置
副本数:replication.factor>=2,即副本数不小于2个。2<=min.insync.replicas<=replication.factor - broker的配置
leader的选举条件:unclean.leader.election.enable=false - producer的配置
request.required.acks = -1(all)
producer.type=sync

















 798
798

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









